 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline-to-Online Multi-Agent Reinforcement Learning with Offline Value Function Memory and Sequential Exploration
Paper and Code
Oct 25, 2024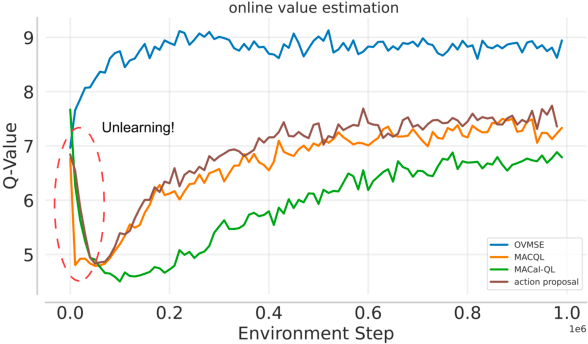
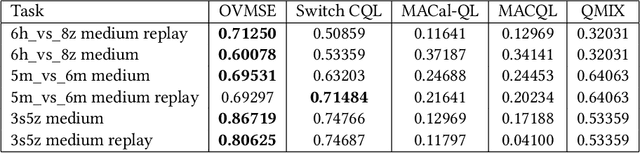
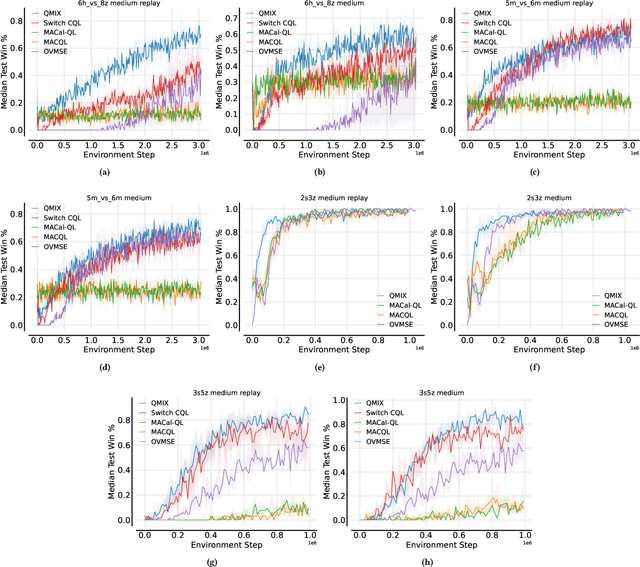
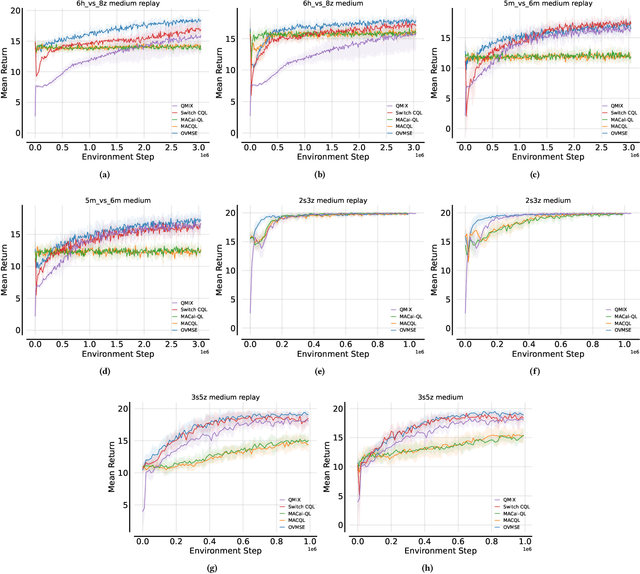
Offline-to-Online Reinforcement Learning has emerged as a powerful paradigm, leveraging offline data for initialization and online fine-tuning to enhance both sample efficiency and performance. However, most existing research has focused on single-agent settings, with limited exploration of the multi-agent extension, i.e., Offline-to-Online Multi-Agent Reinforcement Learning (O2O MARL). In O2O MARL, two critical challenges become more prominent as the number of agents increases: (i) the risk of unlearning pre-trained Q-values due to distributional shifts during the transition from offline-to-online phases, and (ii) the difficulty of efficient exploration in the large joint state-action space. To tackle these challenges, we propose a novel O2O MARL framework called Offline Value Function Memory with Sequential Exploration (OVMSE). First, we introduce the Offline Value Function Memory (OVM) mechanism to compute target Q-values, preserving knowledge gained during offline training, ensuring smoother transitions, and enabling efficient fine-tuning. Second, we propose a decentralized Sequential Exploration (SE) strategy tailored for O2O MARL, which effectively utilizes the pre-trained offline policy for exploration, thereby significantly reducing the joint state-action space to be explored. Extensive experiments on the StarCraft Multi-Agent Challenge (SMAC) demonstrate that OVMSE significantly outperforms existing baselines, achieving superior sample efficiency and overall performance.