 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Search, But Scan: Benchmarking MLLMs on Scan-Oriented Academic Paper Reasoning
Mar 27, 2026With the rapid progress of multimodal large language models (MLLMs), AI already performs well at literature retrieval and certain reasoning tasks, serving as a capable assistant to human researchers, yet it remains far from autonomous research. The fundamental reason is that current work on academic paper reasoning is largely confined to a search-oriented paradigm centered on pre-specified targets, with reasoning grounded in relevance retrieval, which struggles to support researcher-style full-document understanding, reasoning, and verification. To bridge this gap, we propose \textbf{ScholScan}, a new benchmark for academic paper reasoning. ScholScan introduces a scan-oriented task setting that asks models to read and cross-check entire papers like human researchers, scanning the document to identify consistency issues. The benchmark comprises 1,800 carefully annotated questions drawn from nine error categories across 13 natural-science domains and 715 papers, and provides detailed annotations for evidence localization and reasoning traces, together with a unified evaluation protocol. We assessed 15 models across 24 input configurations and conducted a fine-grained analysis of MLLM capabilities for all error categories. Across the board, retrieval-augmented generation (RAG) methods yield no significant improvements, revealing systematic deficiencies of current MLLMs on scan-oriented tasks and underscoring the challenge posed by ScholScan. We expect ScholScan to be the leading and representative work of the scan-oriented task paradigm.
THEMIS: Towards Holistic Evaluation of MLLMs for Scientific Paper Fraud Forensics
Mar 26, 2026We present THEMIS, a novel multi-task benchmark designed to comprehensively evaluate multimodal large language models (MLLMs) on visual fraud reasoning within real-world academic scenarios. Compared to existing benchmarks, THEMIS introduces three major advances. (1) Real-World Scenarios and Complexity: Our benchmark comprises over 4,000 questions spanning seven scenarios, derived from authentic retracted-paper cases and carefully curated multimodal synthetic data. With 60.47% complex-texture images, THEMIS bridges the critical gap between existing benchmarks and the complexity of real-world academic fraud. (2) Fraud-Type Diversity and Granularity: THEMIS systematically covers five challenging fraud types and introduces 16 fine-grained manipulation operations. On average, each sample undergoes multiple stacked manipulation operations, with the diversity and difficulty of these manipulations demanding a high level of visual fraud reasoning from the models. (3) Multi-Dimensional Capability Evaluation: We establish a mapping from fraud types to five core visual fraud reasoning capabilities, thereby enabling an evaluation that reveals the distinct strengths and specific weaknesses of different models across these core capabilities. Experiments on 16 leading MLLMs show that even the best-performing model, GPT-5, achieves an overall performance of only 56.15%, demonstrating that our benchmark presents a stringent test. We expect THEMIS to advance the development of MLLMs for complex, real-world fraud reasoning tasks.
A Scheduling Framework for Efficient MoE Inference on Edge GPU-NDP Systems
Jan 07, 2026Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
TCM-5CEval: Extended Deep Evaluation Benchmark for LLM's Comprehensive Clinical Research Competence in Traditional Chinese Medicine
Nov 17, 2025Large language models (LLMs) have demonstrated exceptional capabilities in general domains, yet their application in highly specialized and culturally-rich fields like Traditional Chinese Medicine (TCM) requires rigorous and nuanced evaluation. Building upon prior foundational work such as TCM-3CEval, which highlighted systemic knowledge gaps and the importance of cultural-contextual alignment, we introduce TCM-5CEval, a more granular and comprehensive benchmark. TCM-5CEval is designed to assess LLMs across five critical dimensions: (1) Core Knowledge (TCM-Exam), (2) Classical Literacy (TCM-LitQA), (3) Clinical Decision-making (TCM-MRCD), (4) Chinese Materia Medica (TCM-CMM), and (5) Clinical Non-pharmacological Therapy (TCM-ClinNPT). We conducted a thorough evaluation of fifteen prominent LLMs, revealing significant performance disparities and identifying top-performing models like deepseek\_r1 and gemini\_2\_5\_pro. Our findings show that while models exhibit proficiency in recalling foundational knowledge, they struggle with the interpretative complexities of classical texts. Critically, permutation-based consistency testing reveals widespread fragilities in model inference. All evaluated models, including the highest-scoring ones, displayed a substantial performance degradation when faced with varied question option ordering, indicating a pervasive sensitivity to positional bias and a lack of robust understanding. TCM-5CEval not only provides a more detailed diagnostic tool for LLM capabilities in TCM but aldso exposes fundamental weaknesses in their reasoning stability. To promote further research and standardized comparison, TCM-5CEval has been uploaded to the Medbench platform, joining its predecessor in the "In-depth Challenge for Comprehensive TCM Abilities" special track.
MedCalc-Eval and MedCalc-Env: Advancing Medical Calculation Capabilities of Large Language Models
Oct 31, 2025As large language models (LLMs) enter the medical domain, most benchmarks evaluate them on question answering or descriptive reasoning, overlooking quantitative reasoning critical to clinical decision-making. Existing datasets like MedCalc-Bench cover few calculation tasks and fail to reflect real-world computational scenarios. We introduce MedCalc-Eval, the largest benchmark for assessing LLMs' medical calculation abilities, comprising 700+ tasks across two types: equation-based (e.g., Cockcroft-Gault, BMI, BSA) and rule-based scoring systems (e.g., Apgar, Glasgow Coma Scale). These tasks span diverse specialties including internal medicine, surgery, pediatrics, and cardiology, offering a broader and more challenging evaluation setting. To improve performance, we further develop MedCalc-Env, a reinforcement learning environment built on the InternBootcamp framework, enabling multi-step clinical reasoning and planning. Fine-tuning a Qwen2.5-32B model within this environment achieves state-of-the-art results on MedCalc-Eval, with notable gains in numerical sensitivity, formula selection, and reasoning robustness. Remaining challenges include unit conversion, multi-condition logic, and contextual understanding. Code and datasets are available at https://github.com/maokangkun/MedCalc-Eval.
Building a Human-Verified Clinical Reasoning Dataset via a Human LLM Hybrid Pipeline for Trustworthy Medical AI
May 11, 2025Despite strong performance in medical question-answering, the clinical adoption of Large Language Models (LLMs) is critically hampered by their opaque 'black-box' reasoning, limiting clinician trust. This challenge is compounded by the predominant reliance of current medical LLMs on corpora from scientific literature or synthetic data, which often lack the granular expert validation and high clinical relevance essential for advancing their specialized medical capabilities. To address these critical gaps, we introduce a highly clinically relevant dataset with 31,247 medical question-answer pairs, each accompanied by expert-validated chain-of-thought (CoT) explanations. This resource, spanning multiple clinical domains, was curated via a scalable human-LLM hybrid pipeline: LLM-generated rationales were iteratively reviewed, scored, and refined by medical experts against a structured rubric, with substandard outputs revised through human effort or guided LLM regeneration until expert consensus. This publicly available dataset provides a vital source for the development of medical LLMs that capable of transparent and verifiable reasoning, thereby advancing safer and more interpretable AI in medicine.
TCM-3CEval: A Triaxial Benchmark for Assessing Responses from Large Language Models in Traditional Chinese Medicine
Mar 10, 2025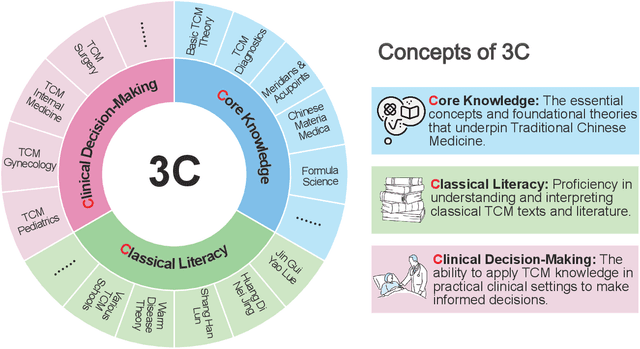
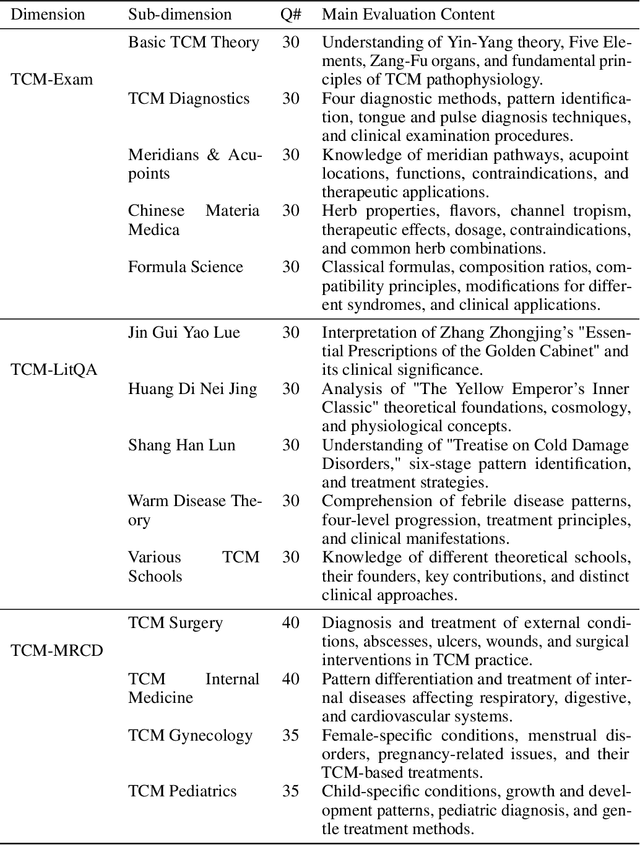

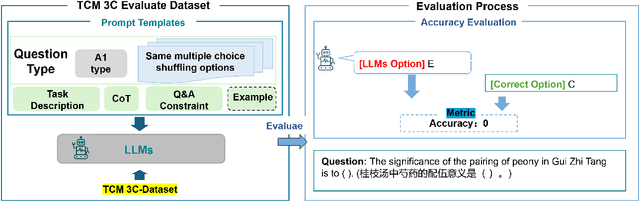
Large language models (LLMs) excel in various NLP tasks and modern medicine, but their evaluation in traditional Chinese medicine (TCM) is underexplored. To address this, we introduce TCM3CEval, a benchmark assessing LLMs in TCM across three dimensions: core knowledge mastery, classical text understanding, and clinical decision-making. We evaluate diverse models, including international (e.g., GPT-4o), Chinese (e.g., InternLM), and medical-specific (e.g., PLUSE). Results show a performance hierarchy: all models have limitations in specialized subdomains like Meridian & Acupoint theory and Various TCM Schools, revealing gaps between current capabilities and clinical needs. Models with Chinese linguistic and cultural priors perform better in classical text interpretation and clinical reasoning. TCM-3CEval sets a standard for AI evaluation in TCM, offering insights for optimizing LLMs in culturally grounded medical domains. The benchmark is available on Medbench's TCM track, aiming to assess LLMs' TCM capabilities in basic knowledge, classic texts, and clinical decision-making through multidimensional questions and real cases.
Benchmarking Chinese Medical LLMs: A Medbench-based Analysis of Performance Gaps and Hierarchical Optimization Strategies
Mar 10, 2025
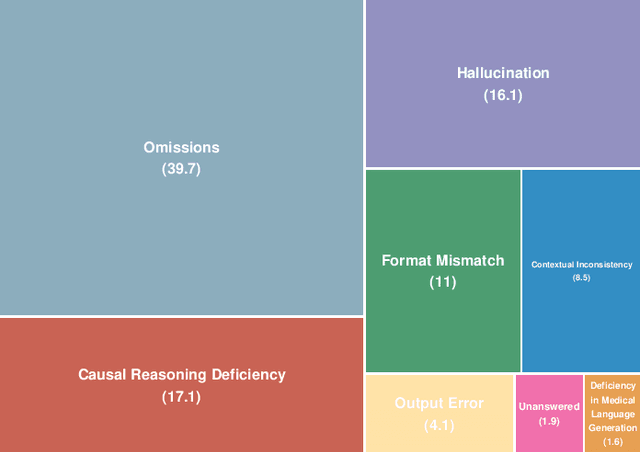

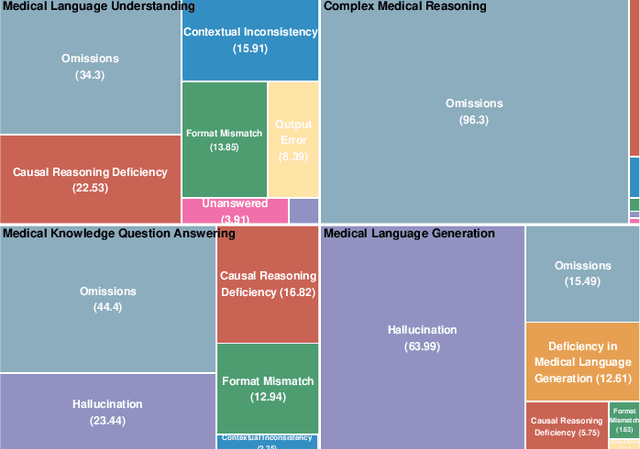
The evaluation and improvement of medical large language models (LLMs) are critical for their real-world deployment, particularly in ensuring accuracy, safety, and ethical alignment. Existing frameworks inadequately dissect domain-specific error patterns or address cross-modal challenges. This study introduces a granular error taxonomy through systematic analysis of top 10 models on MedBench, categorizing incorrect responses into eight types: Omissions, Hallucination, Format Mismatch, Causal Reasoning Deficiency, Contextual Inconsistency, Unanswered, Output Error, and Deficiency in Medical Language Generation. Evaluation of 10 leading models reveals vulnerabilities: despite achieving 0.86 accuracy in medical knowledge recall, critical reasoning tasks show 96.3% omission, while safety ethics evaluations expose alarming inconsistency (robustness score: 0.79) under option shuffled. Our analysis uncovers systemic weaknesses in knowledge boundary enforcement and multi-step reasoning. To address these, we propose a tiered optimization strategy spanning four levels, from prompt engineering and knowledge-augmented retrieval to hybrid neuro-symbolic architectures and causal reasoning frameworks. This work establishes an actionable roadmap for developing clinically robust LLMs while redefining evaluation paradigms through error-driven insights, ultimately advancing the safety and trustworthiness of AI in high-stakes medical environments.
Predictive Modeling with Temporal Graphical Representation on Electronic Health Records
May 07, 2024



Deep learning-based predictive models, leveraging Electronic Health Records (EHR), are receiving increasing attention in healthcare. An effective representation of a patient's EHR should hierarchically encompass both the temporal relationships between historical visits and medical events, and the inherent structural information within these elements. Existing patient representation methods can be roughly categorized into sequential representation and graphical representation. The sequential representation methods focus only on the temporal relationships among longitudinal visits. On the other hand, the graphical representation approaches, while adept at extracting the graph-structured relationships between various medical events, fall short in effectively integrate temporal information. To capture both types of information, we model a patient's EHR as a novel temporal heterogeneous graph. This graph includes historical visits nodes and medical events nodes. It propagates structured information from medical event nodes to visit nodes and utilizes time-aware visit nodes to capture changes in the patient's health status. Furthermore, we introduce a novel temporal graph transformer (TRANS) that integrates temporal edge features, global positional encoding, and local structural encoding into heterogeneous graph convolution, capturing both temporal and structural information. We validate the effectiveness of TRANS through extensive experiments on three real-world datasets. The results show that our proposed approach achieves state-of-the-art performance.