 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQZhou-Embedding Technical Report
Aug 29, 2025We present QZhou-Embedding, a general-purpose contextual text embedding model with exceptional text representation capabilities. Built upon the Qwen2.5-7B-Instruct foundation model, we designed a unified multi-task framework comprising specialized data transformation and training strategies. The data transformation scheme enables the incorporation of more diverse textual training datasets, while the task-specific training strategies enhance model learning efficiency. We developed a data synthesis pipeline leveraging LLM API, incorporating techniques such as paraphrasing, augmentation, and hard negative example generation to improve the semantic richness and sample difficulty of the training set. Additionally, we employ a two-stage training strategy, comprising initial retrieval-focused pretraining followed by full-task fine-tuning, enabling the embedding model to extend its capabilities based on robust retrieval performance. Our model achieves state-of-the-art results on the MTEB and CMTEB benchmarks, ranking first on both leaderboards (August 27 2025), and simultaneously achieves state-of-the-art performance on tasks including reranking, clustering, etc. Our findings demonstrate that higher-quality, more diverse data is crucial for advancing retrieval model performance, and that leveraging LLMs generative capabilities can further optimize data quality for embedding model breakthroughs. Our model weights are released on HuggingFace under Apache 2.0 license. For reproducibility, we provide evaluation code and instructions on GitHub.
GAN Based Near-Field Channel Estimation for Extremely Large-Scale MIMO Systems
Feb 27, 2024Extremely large-scale multiple-input-multiple-output (XL-MIMO) is a promising technique to achieve ultra-high spectral efficiency for future 6G communications. The mixed line-of-sight (LoS) and non-line-of-sight (NLoS) XL-MIMO near-field channel model is adopted to describe the XL-MIMO near-field channel accurately. In this paper, a generative adversarial network (GAN) variant based channel estimation method is proposed for XL-MIMO systems. Specifically, the GAN variant is developed to simultaneously estimate the LoS and NLoS path components of the XL-MIMO channel. The initially estimated channels instead of the received signals are input into the GAN variant as the conditional input to generate the XL-MIMO channels more efficiently. The GAN variant not only learns the mapping from the initially estimated channels to the XL-MIMO channels but also learns an adversarial loss. Moreover, we combine the adversarial loss with a conventional loss function to ensure the correct direction of training the generator. To further enhance the estimation performance, we investigate the impact of the hyper-parameter of the loss function on the performance of our method. Simulation results show that the proposed method outperforms the existing channel estimation approaches in the adopted channel model. In addition, the proposed method surpasses the Cram$\acute{\mathbf{e}}$r-Rao lower bound (CRLB) under low pilot overhead.
Understanding and Improving Deep Graph Neural Networks: A Probabilistic Graphical Model Perspective
Jan 25, 2023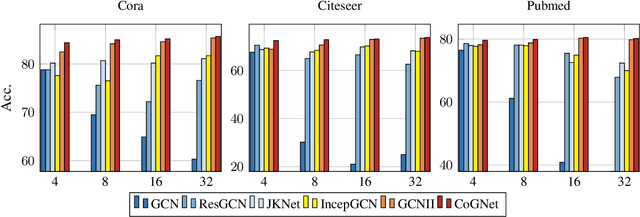
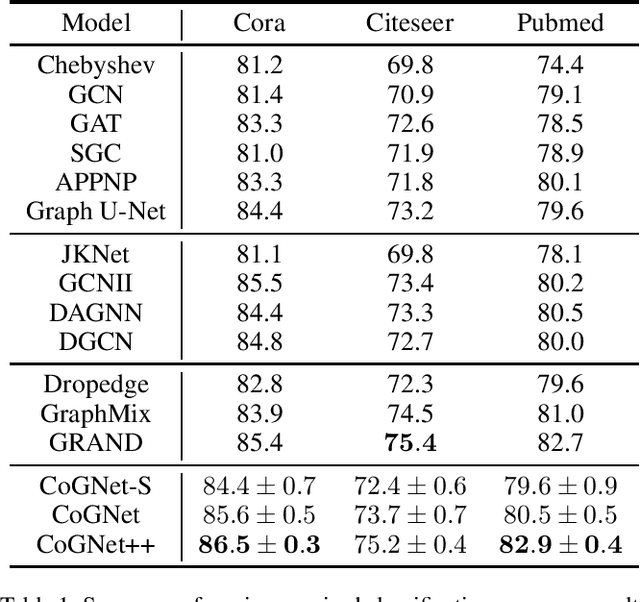

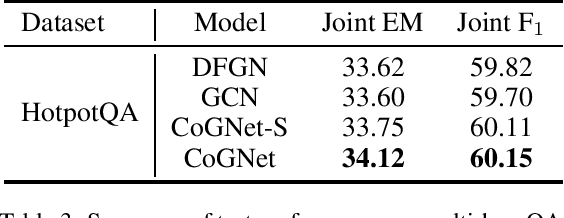
Recently, graph-based models designed for downstream tasks have significantly advanced research on graph neural networks (GNNs). GNN baselines based on neural message-passing mechanisms such as GCN and GAT perform worse as the network deepens. Therefore, numerous GNN variants have been proposed to tackle this performance degradation problem, including many deep GNNs. However, a unified framework is still lacking to connect these existing models and interpret their effectiveness at a high level. In this work, we focus on deep GNNs and propose a novel view for understanding them. We establish a theoretical framework via inference on a probabilistic graphical model. Given the fixed point equation (FPE) derived from the variational inference on the Markov random fields, the deep GNNs, including JKNet, GCNII, DGCN, and the classical GNNs, such as GCN, GAT, and APPNP, can be regarded as different approximations of the FPE. Moreover, given this framework, more accurate approximations of FPE are brought, guiding us to design a more powerful GNN: coupling graph neural network (CoGNet). Extensive experiments are carried out on citation networks and natural language processing downstream tasks. The results demonstrate that the CoGNet outperforms the SOTA models.
Optimality of the Proper Gaussian Signal in Complex MIMO Wiretap Channels
Sep 28, 2022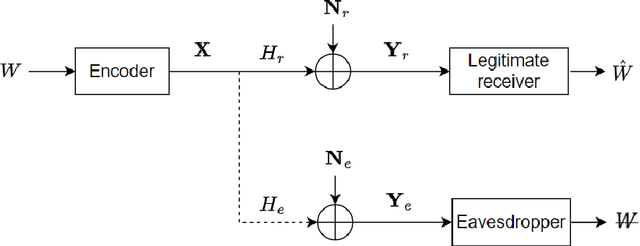
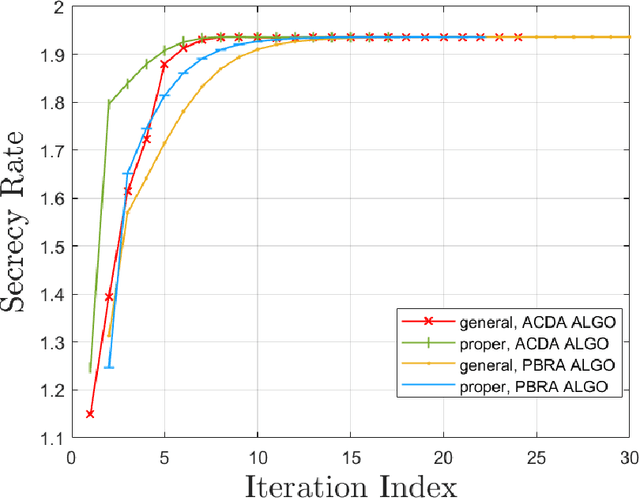
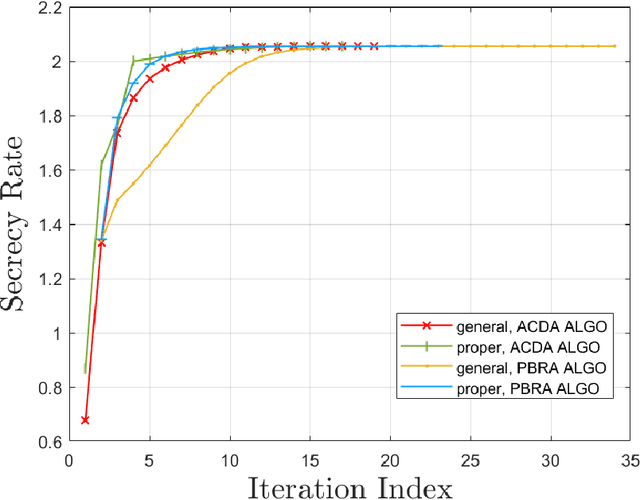
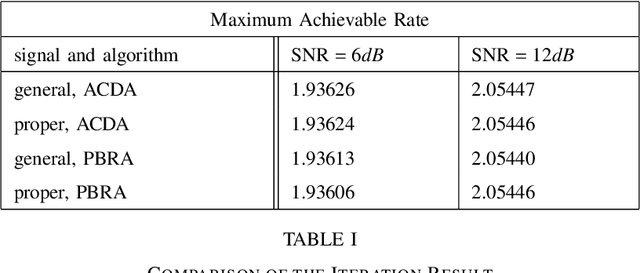
The multiple-input multiple-output (MIMO) wiretap channel (WTC), which has a transmitter, a legitimate user and an eavesdropper, is a classic model for studying information theoretic secrecy. In this paper, the fundamental problem for the complex WTC is whether the proper signal is optimal has yet to be given explicit proof, though previous work implicitly assumed the complex signal was proper. Thus, a determinant inequality is proposed to prove that the secrecy rate of a complex Gaussian signal with a fixed covariance matrix in a degraded complex WTC is maximized if and only if the signal is proper, i.e., the pseudo-covariance matrix is a zero matrix. Moreover, based on the result of the degraded complex WTC and the min-max reformulation of the secrecy capacity, the optimality of the proper signal in the general complex WTC is also revealed. The results of this research complement the current research on complex WTC. To be more specific, we have shown it is sufficient to focus on the proper signal when studying the secrecy capacity of the complex WTC.
TextRGNN: Residual Graph Neural Networks for Text Classification
Dec 30, 2021



Recently, text classification model based on graph neural network (GNN) has attracted more and more attention. Most of these models adopt a similar network paradigm, that is, using pre-training node embedding initialization and two-layer graph convolution. In this work, we propose TextRGNN, an improved GNN structure that introduces residual connection to deepen the convolution network depth. Our structure can obtain a wider node receptive field and effectively suppress the over-smoothing of node features. In addition, we integrate the probabilistic language model into the initialization of graph node embedding, so that the non-graph semantic information of can be better extracted. The experimental results show that our model is general and efficient. It can significantly improve the classification accuracy whether in corpus level or text level, and achieve SOTA performance on a wide range of text classification datasets.
Auto-Encoding Score Distribution Regression for Action Quality Assessment
Nov 22, 2021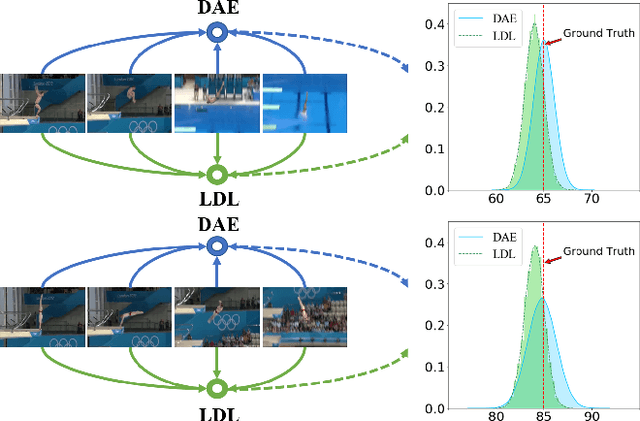
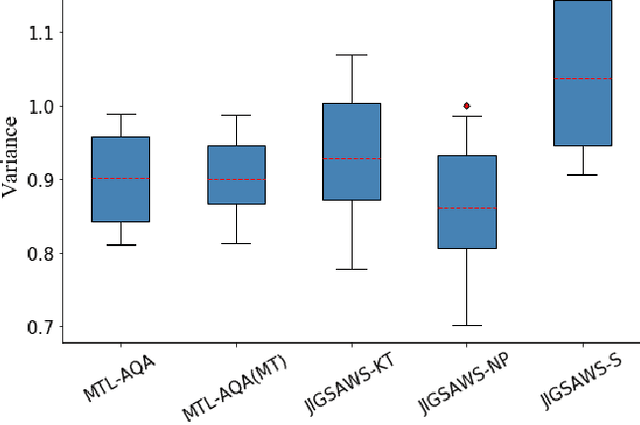
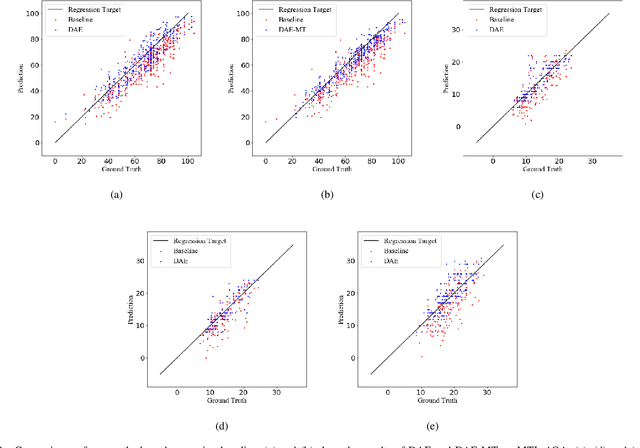
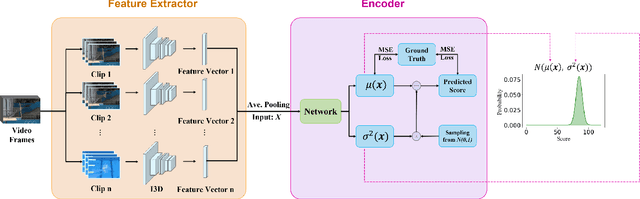
Action quality assessment (AQA) from videos is a challenging vision task since the relation between videos and action scores is difficult to model. Thus, action quality assessment has been widely studied in the literature. Traditionally, AQA task is treated as a regression problem to learn the underlying mappings between videos and action scores. More recently, the method of uncertainty score distribution learning (USDL) made success due to the introduction of label distribution learning (LDL). But USDL does not apply to dataset with continuous labels and needs a fixed variance in training. In this paper, to address the above problems, we further develop Distribution Auto-Encoder (DAE). DAE takes both advantages of regression algorithms and label distribution learning (LDL).Specifically, it encodes videos into distributions and uses the reparameterization trick in variational auto-encoders (VAE) to sample scores, which establishes a more accurate mapping between videos and scores. Meanwhile, a combined loss is constructed to accelerate the training of DAE. DAE-MT is further proposed to deal with AQA on multi-task datasets. We evaluate our DAE approach on MTL-AQA and JIGSAWS datasets. Experimental results on public datasets demonstrate that our method achieves state-of-the-arts under the Spearman's Rank Correlation: 0.9449 on MTL-AQA and 0.73 on JIGSAWS.
On Age of Information for Discrete Time Status Updating System With Ber/G/1/1 Queues
Sep 01, 2021


In this paper, we consider the age of information (AoI) of a discrete time status updating system, focusing on finding the stationary AoI distribution assuming that the Ber/G/1/1 queue is used. Following the standard queueing theory, we show that by invoking a two-dimensional state vector which tracks the AoI and packet age in system simultaneously, the stationary AoI distribution can be derived by analyzing the steady state of the constituted two-dimensional stochastic process. We give the general formula of the AoI distribution and calculate the explicit expression when the service time is also geometrically distributed. The discrete and continuous AoI are compared, we depict the mean of discrete AoI and that of continuous time AoI for system with M/M/1/1 queue. Although the stationary AoI distribution of some continuous time single-server system has been determined before, in this paper, we shall prove that the standard queueing theory is still appliable to analyze the discrete AoI, which is even stronger than the proposed methods handling the continuous AoI.
Robust Graph Learning Under Wasserstein Uncertainty
May 13, 2021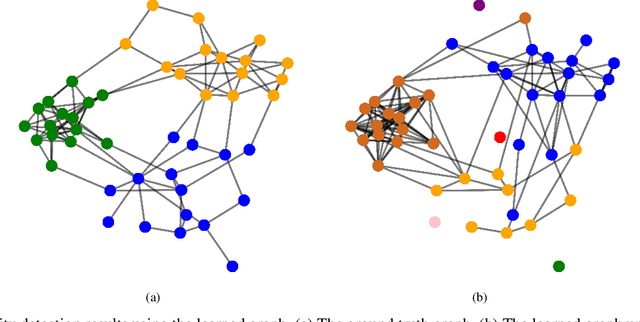

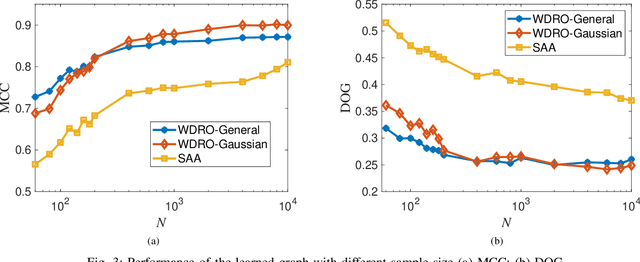
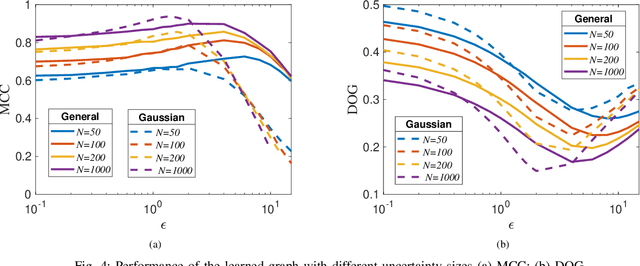
Graphs are playing a crucial role in different fields since they are powerful tools to unveil intrinsic relationships among signals. In many scenarios, an accurate graph structure representing signals is not available at all and that motivates people to learn a reliable graph structure directly from observed signals. However, in real life, it is inevitable that there exists uncertainty in the observed signals due to noise measurements or limited observability, which causes a reduction in reliability of the learned graph. To this end, we propose a graph learning framework using Wasserstein distributionally robust optimization (WDRO) which handles uncertainty in data by defining an uncertainty set on distributions of the observed data. Specifically, two models are developed, one of which assumes all distributions in uncertainty set are Gaussian distributions and the other one has no prior distributional assumption. Instead of using interior point method directly, we propose two algorithms to solve the corresponding models and show that our algorithms are more time-saving. In addition, we also reformulate both two models into Semi-Definite Programming (SDP), and illustrate that they are intractable in the scenario of large-scale graph. Experiments on both synthetic and real world data are carried out to validate the proposed framework, which show that our scheme can learn a reliable graph in the context of uncertainty.