 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Deep Graph Neural Networks: A Probabilistic Graphical Model Perspective
Jan 25, 2023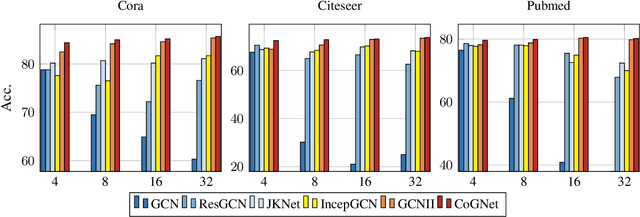
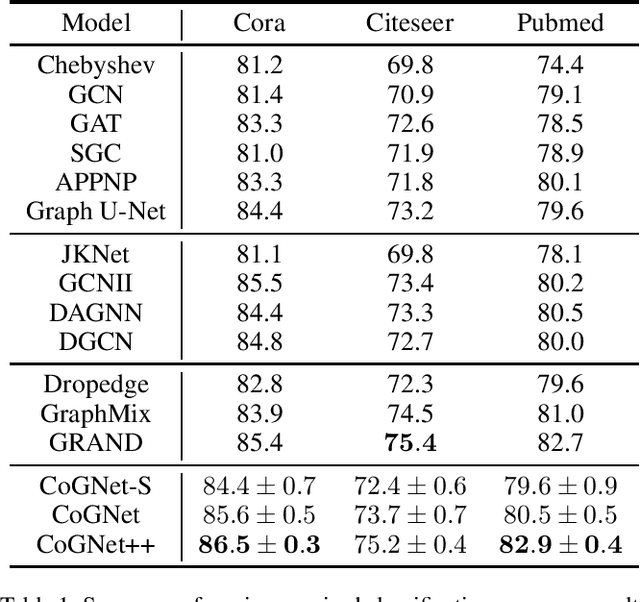

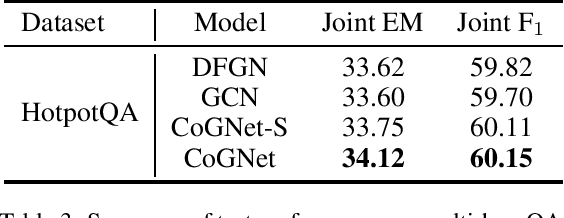
Recently, graph-based models designed for downstream tasks have significantly advanced research on graph neural networks (GNNs). GNN baselines based on neural message-passing mechanisms such as GCN and GAT perform worse as the network deepens. Therefore, numerous GNN variants have been proposed to tackle this performance degradation problem, including many deep GNNs. However, a unified framework is still lacking to connect these existing models and interpret their effectiveness at a high level. In this work, we focus on deep GNNs and propose a novel view for understanding them. We establish a theoretical framework via inference on a probabilistic graphical model. Given the fixed point equation (FPE) derived from the variational inference on the Markov random fields, the deep GNNs, including JKNet, GCNII, DGCN, and the classical GNNs, such as GCN, GAT, and APPNP, can be regarded as different approximations of the FPE. Moreover, given this framework, more accurate approximations of FPE are brought, guiding us to design a more powerful GNN: coupling graph neural network (CoGNet). Extensive experiments are carried out on citation networks and natural language processing downstream tasks. The results demonstrate that the CoGNet outperforms the SOTA models.
Soft Threshold Ternary Networks
Apr 04, 2022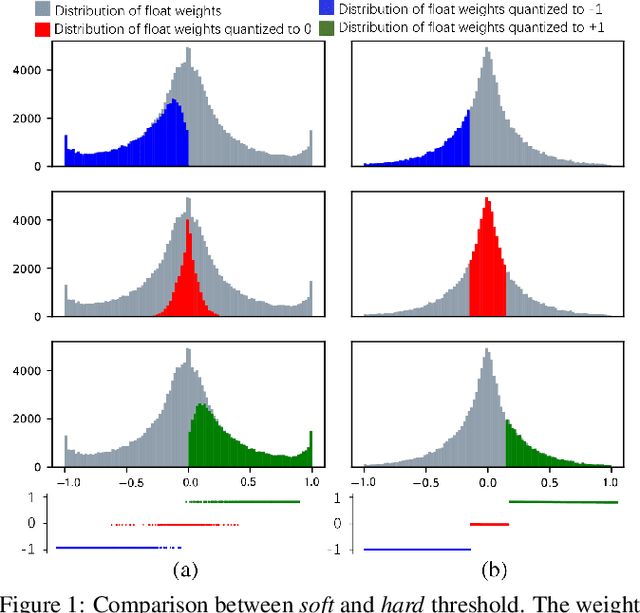

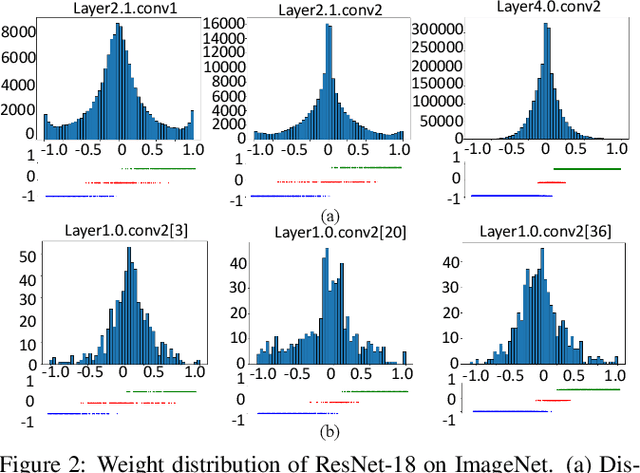

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
APRIL: Finding the Achilles' Heel on Privacy for Vision Transformers
Dec 28, 2021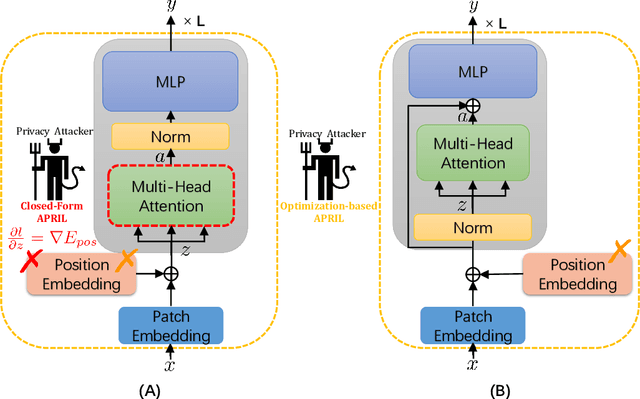



Federated learning frameworks typically require collaborators to share their local gradient updates of a common model instead of sharing training data to preserve privacy. However, prior works on Gradient Leakage Attacks showed that private training data can be revealed from gradients. So far almost all relevant works base their attacks on fully-connected or convolutional neural networks. Given the recent overwhelmingly rising trend of adapting Transformers to solve multifarious vision tasks, it is highly valuable to investigate the privacy risk of vision transformers. In this paper, we analyse the gradient leakage risk of self-attention based mechanism in both theoretical and practical manners. Particularly, we propose APRIL - Attention PRIvacy Leakage, which poses a strong threat to self-attention inspired models such as ViT. Showing how vision Transformers are at the risk of privacy leakage via gradients, we urge the significance of designing privacy-safer Transformer models and defending schemes.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021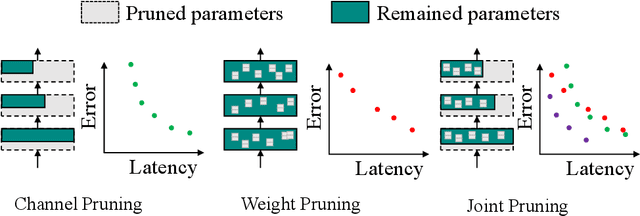
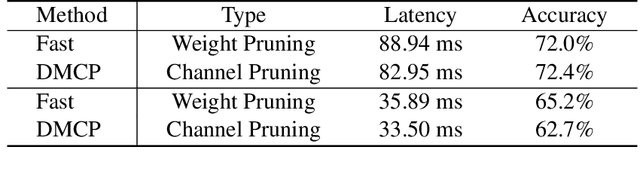
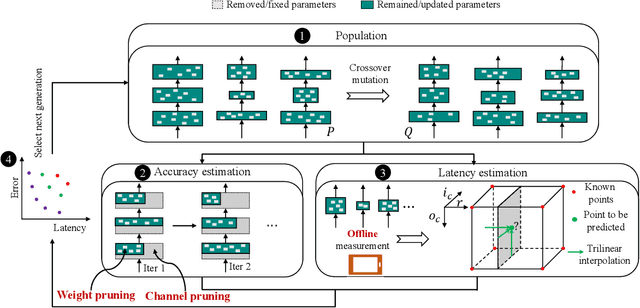
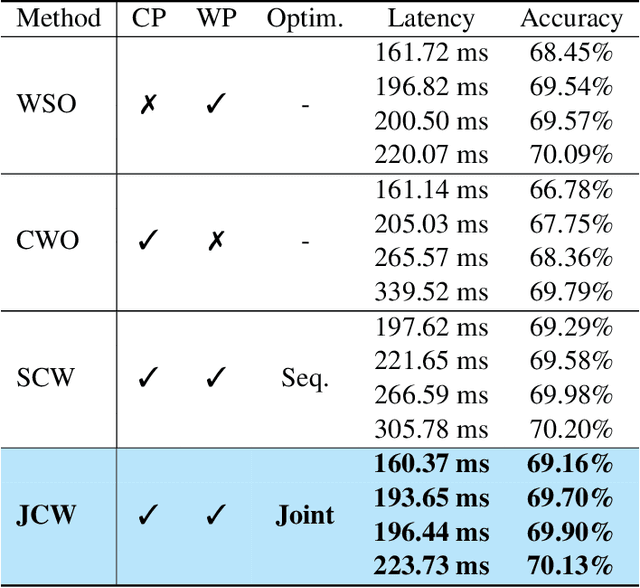
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021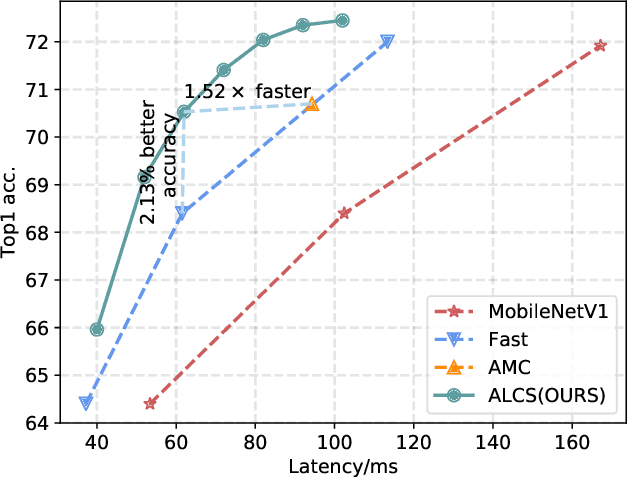
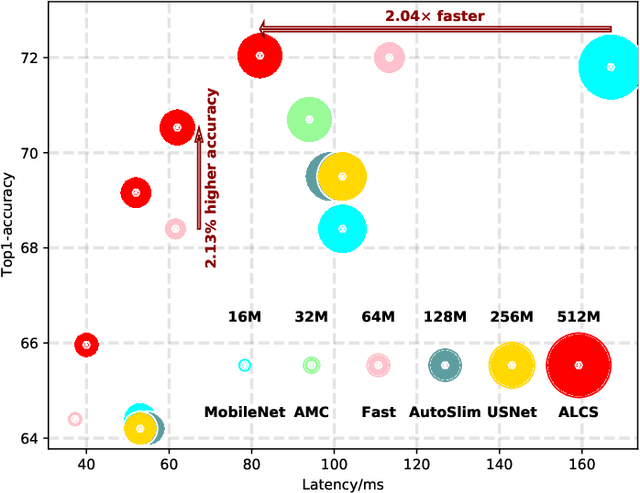
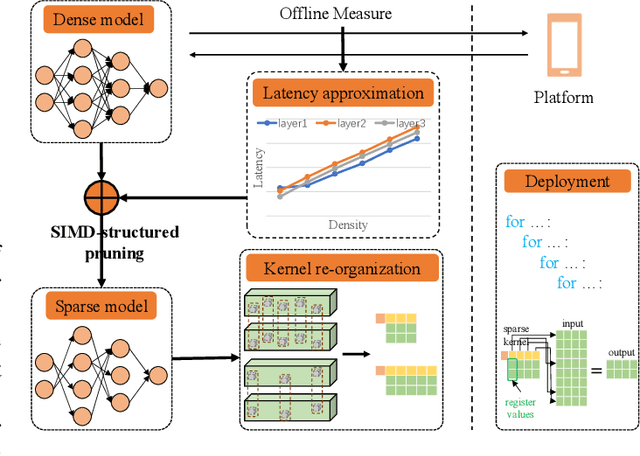
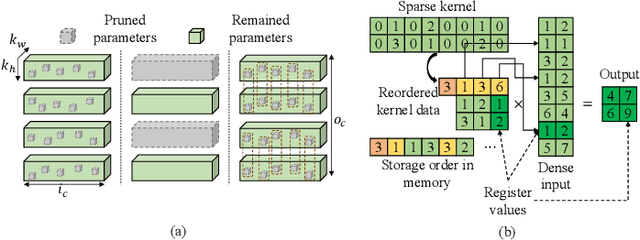
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.