 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMPCB: A Lightweight and Safety-Critical Motion Control Framework
May 03, 2025
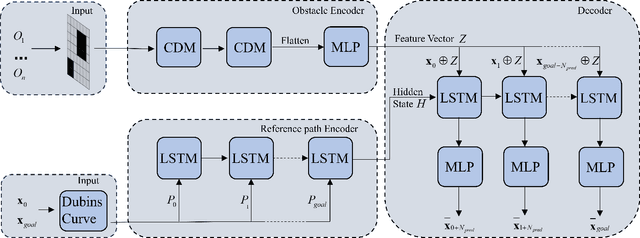


In multi-obstacle environments, real-time performance and safety in robot motion control have long been challenging issues, as conventional methods often struggle to balance the two. In this paper, we propose a novel motion control framework composed of a Neural network-based path planner and a Model Predictive Control (MPC) controller based on control Barrier function (NMPCB) . The planner predicts the next target point through a lightweight neural network and generates a reference trajectory for the controller. In the design of the controller, we introduce the dual problem of control barrier function (CBF) as the obstacle avoidance constraint, enabling it to ensure robot motion safety while significantly reducing computation time. The controller directly outputs control commands to the robot by tracking the reference trajectory. This framework achieves a balance between real-time performance and safety. We validate the feasibility of the framework through numerical simulations and real-world experiments.
Medical Federated Model with Mixture of Personalized and Sharing Components
Jun 26, 2023Although data-driven methods usually have noticeable performance on disease diagnosis and treatment, they are suspected of leakage of privacy due to collecting data for model training. Recently, federated learning provides a secure and trustable alternative to collaboratively train model without any exchange of medical data among multiple institutes. Therefore, it has draw much attention due to its natural merit on privacy protection. However, when heterogenous medical data exists between different hospitals, federated learning usually has to face with degradation of performance. In the paper, we propose a new personalized framework of federated learning to handle the problem. It successfully yields personalized models based on awareness of similarity between local data, and achieves better tradeoff between generalization and personalization than existing methods. After that, we further design a differentially sparse regularizer to improve communication efficiency during procedure of model training. Additionally, we propose an effective method to reduce the computational cost, which improves computation efficiency significantly. Furthermore, we collect 5 real medical datasets, including 2 public medical image datasets and 3 private multi-center clinical diagnosis datasets, and evaluate its performance by conducting nodule classification, tumor segmentation, and clinical risk prediction tasks. Comparing with 13 existing related methods, the proposed method successfully achieves the best model performance, and meanwhile up to 60% improvement of communication efficiency. Source code is public, and can be accessed at: https://github.com/ApplicationTechnologyOfMedicalBigData/pFedNet-code.
Robust Graph Learning Under Wasserstein Uncertainty
May 13, 2021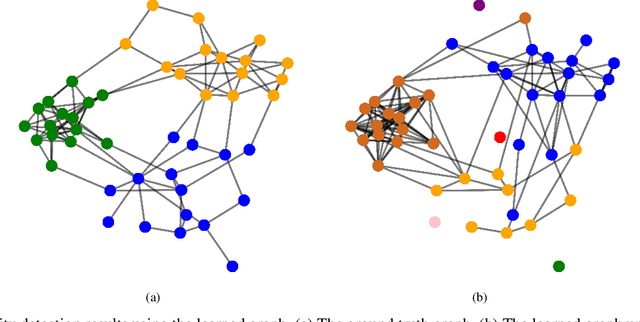

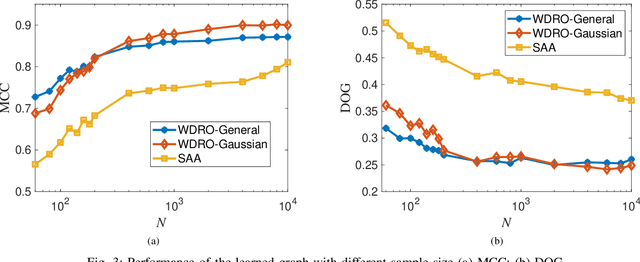
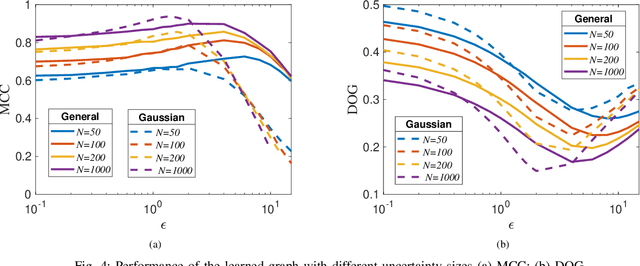
Graphs are playing a crucial role in different fields since they are powerful tools to unveil intrinsic relationships among signals. In many scenarios, an accurate graph structure representing signals is not available at all and that motivates people to learn a reliable graph structure directly from observed signals. However, in real life, it is inevitable that there exists uncertainty in the observed signals due to noise measurements or limited observability, which causes a reduction in reliability of the learned graph. To this end, we propose a graph learning framework using Wasserstein distributionally robust optimization (WDRO) which handles uncertainty in data by defining an uncertainty set on distributions of the observed data. Specifically, two models are developed, one of which assumes all distributions in uncertainty set are Gaussian distributions and the other one has no prior distributional assumption. Instead of using interior point method directly, we propose two algorithms to solve the corresponding models and show that our algorithms are more time-saving. In addition, we also reformulate both two models into Semi-Definite Programming (SDP), and illustrate that they are intractable in the scenario of large-scale graph. Experiments on both synthetic and real world data are carried out to validate the proposed framework, which show that our scheme can learn a reliable graph in the context of uncertainty.