 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024

Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.
Markov Chain Mirror Descent On Data Federation
Sep 26, 2023


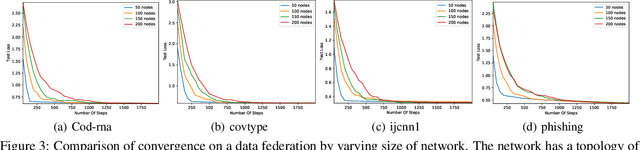
Stochastic optimization methods such as mirror descent have wide applications due to low computational cost. Those methods have been well studied under assumption of the independent and identical distribution, and usually achieve sublinear rate of convergence. However, this assumption may be too strong and unpractical in real application scenarios. Recent researches investigate stochastic gradient descent when instances are sampled from a Markov chain. Unfortunately, few results are known for stochastic mirror descent. In the paper, we propose a new version of stochastic mirror descent termed by MarchOn in the scenario of the federated learning. Given a distributed network, the model iteratively travels from a node to one of its neighbours randomly. Furthermore, we propose a new framework to analyze MarchOn, which yields best rates of convergence for convex, strongly convex, and non-convex loss. Finally, we conduct empirical studies to evaluate the convergence of MarchOn, and validate theoretical results.
Medical Federated Model with Mixture of Personalized and Sharing Components
Jun 26, 2023



Although data-driven methods usually have noticeable performance on disease diagnosis and treatment, they are suspected of leakage of privacy due to collecting data for model training. Recently, federated learning provides a secure and trustable alternative to collaboratively train model without any exchange of medical data among multiple institutes. Therefore, it has draw much attention due to its natural merit on privacy protection. However, when heterogenous medical data exists between different hospitals, federated learning usually has to face with degradation of performance. In the paper, we propose a new personalized framework of federated learning to handle the problem. It successfully yields personalized models based on awareness of similarity between local data, and achieves better tradeoff between generalization and personalization than existing methods. After that, we further design a differentially sparse regularizer to improve communication efficiency during procedure of model training. Additionally, we propose an effective method to reduce the computational cost, which improves computation efficiency significantly. Furthermore, we collect 5 real medical datasets, including 2 public medical image datasets and 3 private multi-center clinical diagnosis datasets, and evaluate its performance by conducting nodule classification, tumor segmentation, and clinical risk prediction tasks. Comparing with 13 existing related methods, the proposed method successfully achieves the best model performance, and meanwhile up to 60% improvement of communication efficiency. Source code is public, and can be accessed at: https://github.com/ApplicationTechnologyOfMedicalBigData/pFedNet-code.
Understand Dynamic Regret with Switching Cost for Online Decision Making
Nov 28, 2019
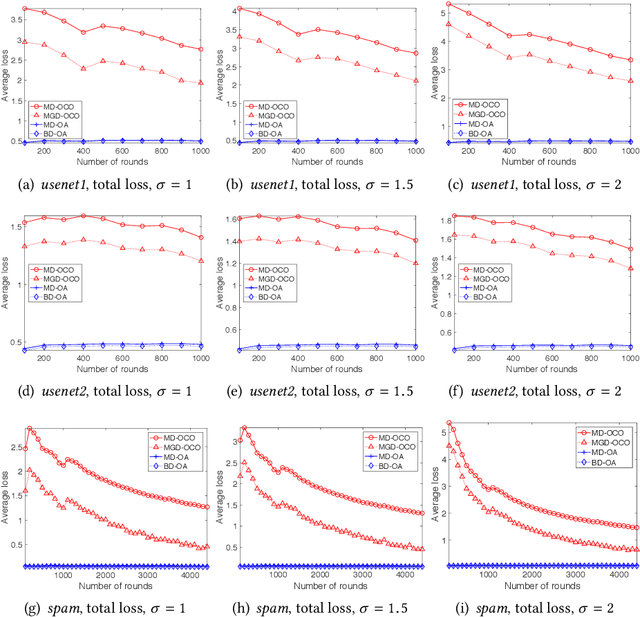
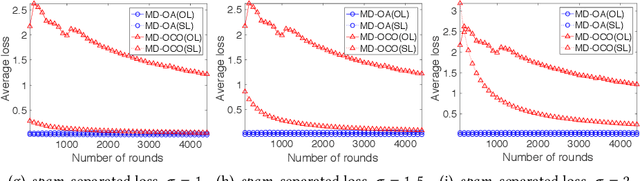
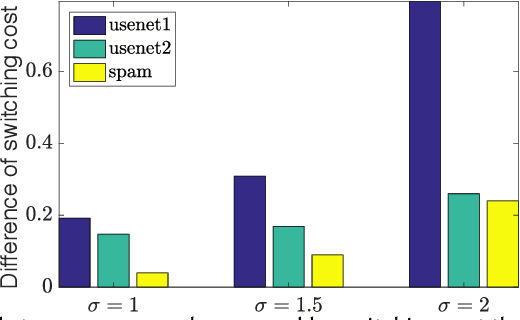
As a metric to measure the performance of an online method, dynamic regret with switching cost has drawn much attention for online decision making problems. Although the sublinear regret has been provided in many previous researches, we still have little knowledge about the relation between the dynamic regret and the switching cost. In the paper, we investigate the relation for two classic online settings: Online Algorithms (OA) and Online Convex Optimization (OCO). We provide a new theoretical analysis framework, which shows an interesting observation, that is, the relation between the switching cost and the dynamic regret is different for settings of OA and OCO. Specifically, the switching cost has significant impact on the dynamic regret in the setting of OA. But, it does not have an impact on the dynamic regret in the setting of OCO. Furthermore, we provide a lower bound of regret for the setting of OCO, which is same with the lower bound in the case of no switching cost. It shows that the switching cost does not change the difficulty of online decision making problems in the setting of OCO.
Simultaneous Clustering and Optimization for Evolving Datasets
Aug 04, 2019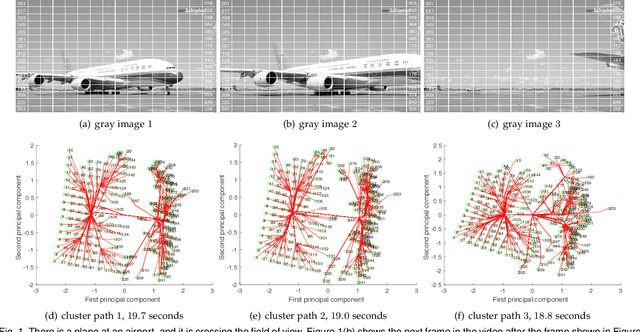


Simultaneous clustering and optimization (SCO) has recently drawn much attention due to its wide range of practical applications. Many methods have been previously proposed to solve this problem and obtain the optimal model. However, when a dataset evolves over time, those existing methods have to update the model frequently to guarantee accuracy; such updating is computationally infeasible. In this paper, we propose a new formulation of SCO to handle evolving datasets. Specifically, we propose a new variant of the alternating direction method of multipliers (ADMM) to solve this problem efficiently. The guarantee of model accuracy is analyzed theoretically for two specific tasks: ridge regression and convex clustering. Extensive empirical studies confirm the effectiveness of our method.
Decentralized Online Learning: Take Benefits from Others' Data without Sharing Your Own to Track Global Trend
Mar 28, 2019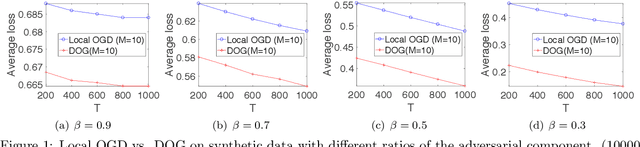
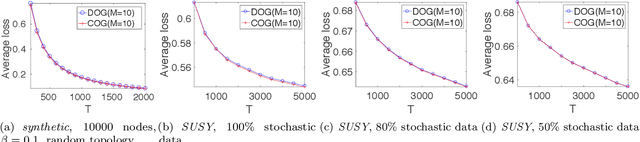
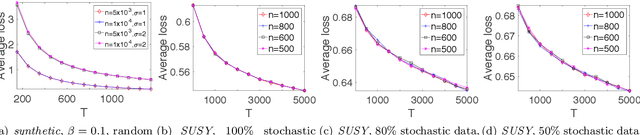

Decentralized Online Learning (online learning in decentralized networks) attracts more and more attention, since it is believed that Decentralized Online Learning can help the data providers cooperatively better solve their online problems without sharing their private data to a third party or other providers. Typically, the cooperation is achieved by letting the data providers exchange their models between neighbors, e.g., recommendation model. However, the best regret bound for a decentralized online learning algorithm is $\Ocal{n\sqrt{T}}$, where $n$ is the number of nodes (or users) and $T$ is the number of iterations. This is clearly insignificant since this bound can be achieved \emph{without} any communication in the networks. This reminds us to ask a fundamental question: \emph{Can people really get benefit from the decentralized online learning by exchanging information?} In this paper, we studied when and why the communication can help the decentralized online learning to reduce the regret. Specifically, each loss function is characterized by two components: the adversarial component and the stochastic component. Under this characterization, we show that decentralized online gradient (DOG) enjoys a regret bound $\Ocal{n\sqrt{T}G + \sqrt{nT}\sigma}$, where $G$ measures the magnitude of the adversarial component in the private data (or equivalently the local loss function) and $\sigma$ measures the randomness within the private data. This regret suggests that people can get benefits from the randomness in the private data by exchanging private information. Another important contribution of this paper is to consider the dynamic regret -- a more practical regret to track users' interest dynamics. Empirical studies are also conducted to validate our analysis.
Dynamic Online Gradient Descent with Improved Query Complexity: A Theoretical Revisit
Jan 08, 2019
We provide a new theoretical analysis framework to investigate online gradient descent in the dynamic environment. Comparing with the previous work, the new framework recovers the state-of-the-art dynamic regret, but does not require extra gradient queries for every iteration. Specifically, when functions are $\alpha$ strongly convex and $\beta$ smooth, to achieve the state-of-the-art dynamic regret, the previous work requires $O(\kappa)$ with $\kappa = \frac{\beta}{\alpha}$ queries of gradients at every iteration. But, our framework shows that the query complexity can be improved to be $O(1)$, which does not depend on $\kappa$. The improvement is significant for ill-conditioned problems because that their objective function usually has a large $\kappa$.
Proximal Online Gradient is Optimum for Dynamic Regret
Oct 23, 2018In online learning, the dynamic regret metric chooses the reference (optimal) solution that may change over time, while the typical (static) regret metric assumes the reference solution to be constant over the whole time horizon. The dynamic regret metric is particularly interesting for applications such as online recommendation (since the customers' preference always evolves over time). While the online gradient method has been shown to be optimal for the static regret metric, the optimal algorithm for the dynamic regret remains unknown. In this paper, we show that proximal online gradient (a general version of online gradient) is optimum to the dynamic regret by showing that the proved lower bound matches the upper bound that slightly improves existing upper bound.
Triangle Lasso for Simultaneous Clustering and Optimization in Graph Datasets
Aug 20, 2018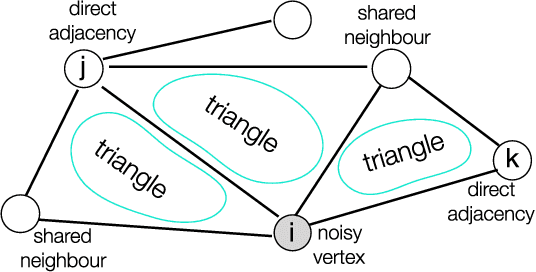

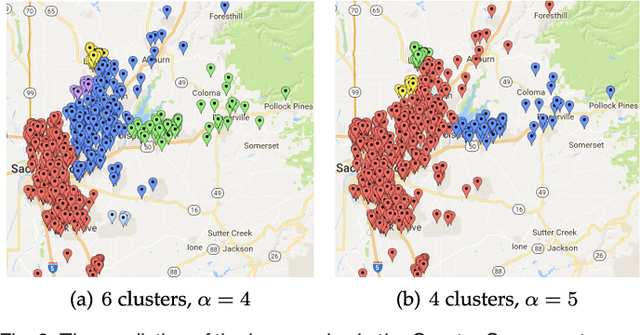
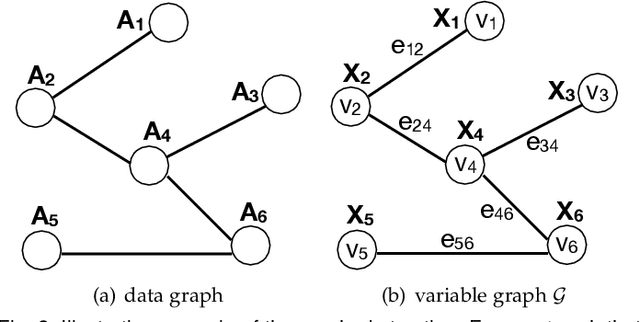
Recently, network lasso has drawn many attentions due to its remarkable performance on simultaneous clustering and optimization. However, it usually suffers from the imperfect data (noise, missing values etc), and yields sub-optimal solutions. The reason is that it finds the similar instances according to their features directly, which is usually impacted by the imperfect data, and thus returns sub-optimal results. In this paper, we propose triangle lasso to avoid its disadvantage. Triangle lasso finds the similar instances according to their neighbours. If two instances have many common neighbours, they tend to become similar. Although some instances are profiled by the imperfect data, it is still able to find the similar counterparts. Furthermore, we develop an efficient algorithm based on Alternating Direction Method of Multipliers (ADMM) to obtain a moderately accurate solution. In addition, we present a dual method to obtain the accurate solution with the low additional time consumption. We demonstrate through extensive numerical experiments that triangle lasso is robust to the imperfect data. It usually yields a better performance than the state-of-the-art method when performing data analysis tasks in practical scenarios.