 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024
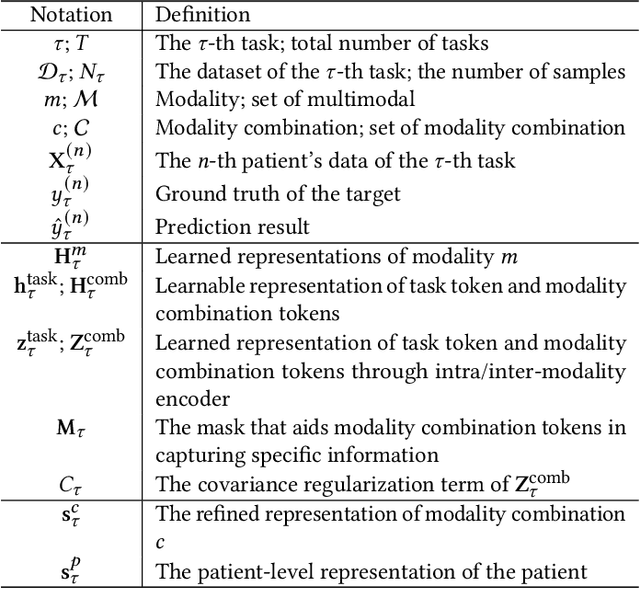

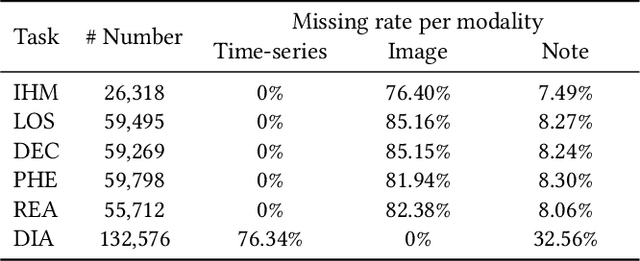
Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.
Information Maximization via Variational Autoencoders for Cross-Domain Recommendation
May 31, 2024



Cross-Domain Sequential Recommendation (CDSR) methods aim to address the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR methods typically rely on overlapping users, designing complex cross-domain modules to capture users' latent interests that can propagate across different domains. However, their propagated informative information is limited to the overlapping users and the users who have rich historical behavior records. As a result, these methods often underperform in real-world scenarios, where most users are non-overlapping (cold-start) and long-tailed. In this research, we introduce a new CDSR framework named Information Maximization Variational Autoencoder (\textbf{\texttt{IM-VAE}}). Here, we suggest using a Pseudo-Sequence Generator to enhance the user's interaction history input for downstream fine-grained CDSR models to alleviate the cold-start issues. We also propose a Generative Recommendation Framework combined with three regularizers inspired by the mutual information maximization (MIM) theory \cite{mcgill1954multivariate} to capture the semantic differences between a user's interests shared across domains and those specific to certain domains, as well as address the informational gap between a user's actual interaction sequences and the pseudo-sequences generated. To the best of our knowledge, this paper is the first CDSR work that considers the information disentanglement and denoising of pseudo-sequences in the open-world recommendation scenario. Empirical experiments illustrate that \texttt{IM-VAE} outperforms the state-of-the-art approaches on two real-world cross-domain datasets on all sorts of users, including cold-start and tailed users, demonstrating the effectiveness of \texttt{IM-VAE} in open-world recommendation.
Node-oriented Spectral Filtering for Graph Neural Networks
Dec 07, 2022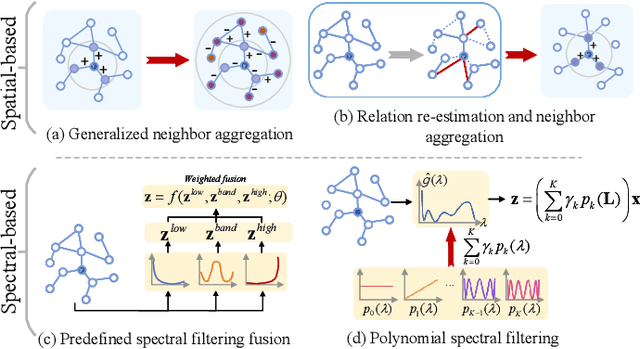

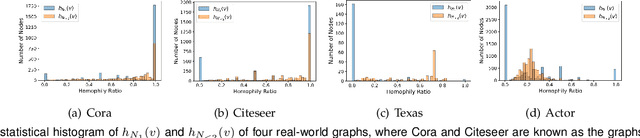
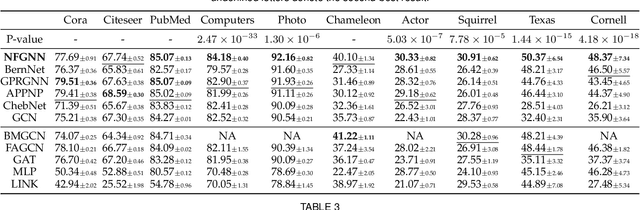
Graph neural networks (GNNs) have shown remarkable performance on homophilic graph data while being far less impressive when handling non-homophilic graph data due to the inherent low-pass filtering property of GNNs. In general, since the real-world graphs are often a complex mixture of diverse subgraph patterns, learning a universal spectral filter on the graph from the global perspective as in most current works may still suffer from great difficulty in adapting to the variation of local patterns. On the basis of the theoretical analysis on local patterns, we rethink the existing spectral filtering methods and propose the \textbf{\underline{N}}ode-oriented spectral \textbf{\underline{F}}iltering for \textbf{\underline{G}}raph \textbf{\underline{N}}eural \textbf{\underline{N}}etwork (namely NFGNN). By estimating the node-oriented spectral filter for each node, NFGNN is provided with the capability of precise local node positioning via the generalized translated operator, thus discriminating the variations of local homophily patterns adaptively. Meanwhile, the utilization of re-parameterization brings a good trade-off between global consistency and local sensibility for learning the node-oriented spectral filters. Furthermore, we theoretically analyze the localization property of NFGNN, demonstrating that the signal after adaptive filtering is still positioned around the corresponding node. Extensive experimental results demonstrate that the proposed NFGNN achieves more favorable performance.
HGV4Risk: Hierarchical Global View-guided Sequence Representation Learning for Risk Prediction
Nov 15, 2022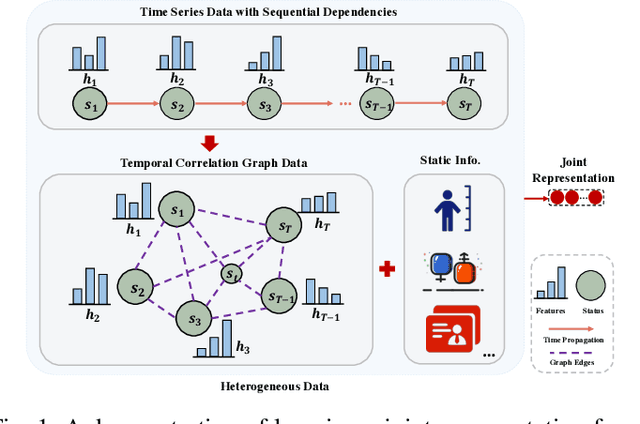
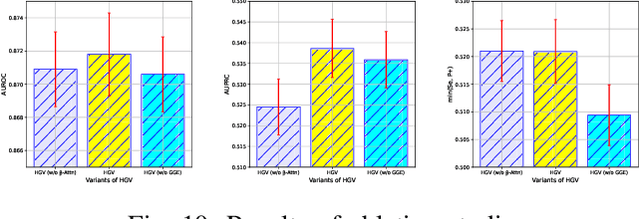
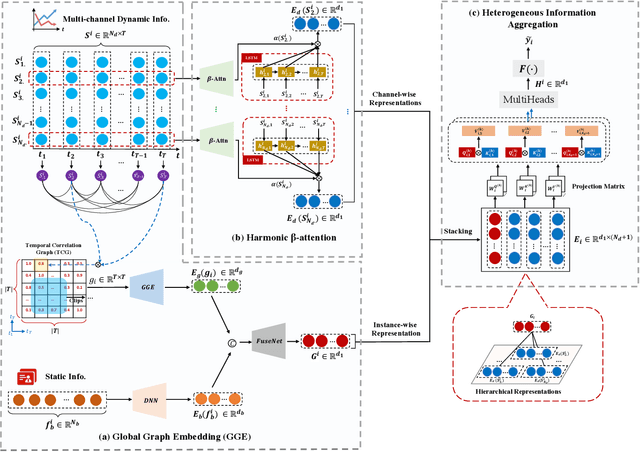
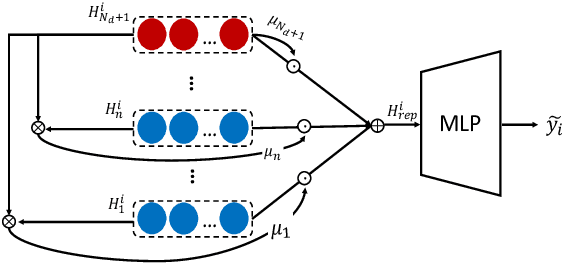
Risk prediction, as a typical time series modeling problem, is usually achieved by learning trends in markers or historical behavior from sequence data, and has been widely applied in healthcare and finance. In recent years, deep learning models, especially Long Short-Term Memory neural networks (LSTMs), have led to superior performances in such sequence representation learning tasks. Despite that some attention or self-attention based models with time-aware or feature-aware enhanced strategies have achieved better performance compared with other temporal modeling methods, such improvement is limited due to a lack of guidance from global view. To address this issue, we propose a novel end-to-end Hierarchical Global View-guided (HGV) sequence representation learning framework. Specifically, the Global Graph Embedding (GGE) module is proposed to learn sequential clip-aware representations from temporal correlation graph at instance level. Furthermore, following the way of key-query attention, the harmonic $\beta$-attention ($\beta$-Attn) is also developed for making a global trade-off between time-aware decay and observation significance at channel level adaptively. Moreover, the hierarchical representations at both instance level and channel level can be coordinated by the heterogeneous information aggregation under the guidance of global view. Experimental results on a benchmark dataset for healthcare risk prediction, and a real-world industrial scenario for Small and Mid-size Enterprises (SMEs) credit overdue risk prediction in MYBank, Ant Group, have illustrated that the proposed model can achieve competitive prediction performance compared with other known baselines.
EA-LSTM: Evolutionary Attention-based LSTM for Time Series Prediction
Nov 09, 2018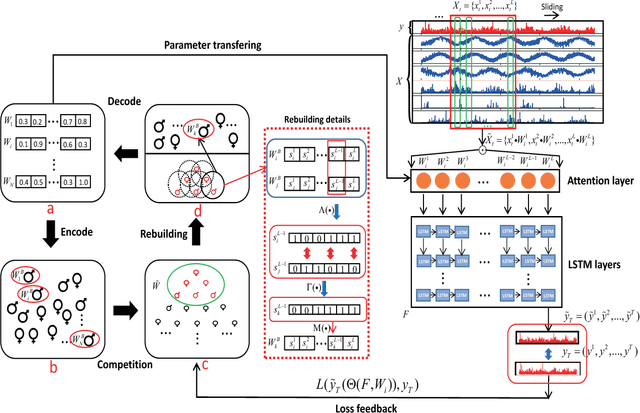


Time series prediction with deep learning methods, especially long short-term memory neural networks (LSTMs), have scored significant achievements in recent years. Despite the fact that the LSTMs can help to capture long-term dependencies, its ability to pay different degree of attention on sub-window feature within multiple time-steps is insufficient. To address this issue, an evolutionary attention-based LSTM training with competitive random search is proposed for multivariate time series prediction. By transferring shared parameters, an evolutionary attention learning approach is introduced to the LSTMs model. Thus, like that for biological evolution, the pattern for importance-based attention sampling can be confirmed during temporal relationship mining. To refrain from being trapped into partial optimization like traditional gradient-based methods, an evolutionary computation inspired competitive random search method is proposed, which can well configure the parameters in the attention layer. Experimental results have illustrated that the proposed model can achieve competetive prediction performance compared with other baseline methods.