 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Pre-trained Graph Condensation via Optimal Transport
Sep 18, 2025Graph condensation (GC) aims to distill the original graph into a small-scale graph, mitigating redundancy and accelerating GNN training. However, conventional GC approaches heavily rely on rigid GNNs and task-specific supervision. Such a dependency severely restricts their reusability and generalization across various tasks and architectures. In this work, we revisit the goal of ideal GC from the perspective of GNN optimization consistency, and then a generalized GC optimization objective is derived, by which those traditional GC methods can be viewed nicely as special cases of this optimization paradigm. Based on this, Pre-trained Graph Condensation (PreGC) via optimal transport is proposed to transcend the limitations of task- and architecture-dependent GC methods. Specifically, a hybrid-interval graph diffusion augmentation is presented to suppress the weak generalization ability of the condensed graph on particular architectures by enhancing the uncertainty of node states. Meanwhile, the matching between optimal graph transport plan and representation transport plan is tactfully established to maintain semantic consistencies across source graph and condensed graph spaces, thereby freeing graph condensation from task dependencies. To further facilitate the adaptation of condensed graphs to various downstream tasks, a traceable semantic harmonizer from source nodes to condensed nodes is proposed to bridge semantic associations through the optimized representation transport plan in pre-training. Extensive experiments verify the superiority and versatility of PreGC, demonstrating its task-independent nature and seamless compatibility with arbitrary GNNs.
Dynamic Graph Condensation
Jun 16, 2025Recent research on deep graph learning has shifted from static to dynamic graphs, motivated by the evolving behaviors observed in complex real-world systems. However, the temporal extension in dynamic graphs poses significant data efficiency challenges, including increased data volume, high spatiotemporal redundancy, and reliance on costly dynamic graph neural networks (DGNNs). To alleviate the concerns, we pioneer the study of dynamic graph condensation (DGC), which aims to substantially reduce the scale of dynamic graphs for data-efficient DGNN training. Accordingly, we propose DyGC, a novel framework that condenses the real dynamic graph into a compact version while faithfully preserving the inherent spatiotemporal characteristics. Specifically, to endow synthetic graphs with realistic evolving structures, a novel spiking structure generation mechanism is introduced. It draws on the dynamic behavior of spiking neurons to model temporally-aware connectivity in dynamic graphs. Given the tightly coupled spatiotemporal dependencies, DyGC proposes a tailored distribution matching approach that first constructs a semantically rich state evolving field for dynamic graphs, and then performs fine-grained spatiotemporal state alignment to guide the optimization of the condensed graph. Experiments across multiple dynamic graph datasets and representative DGNN architectures demonstrate the effectiveness of DyGC. Notably, our method retains up to 96.2% DGNN performance with only 0.5% of the original graph size, and achieves up to 1846 times training speedup.
FlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024

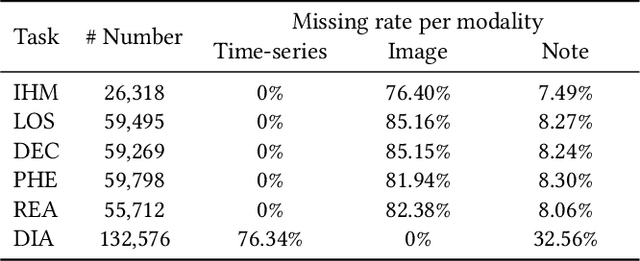
Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.
Unleashing the potential of GNNs via Bi-directional Knowledge Transfer
Oct 26, 2023
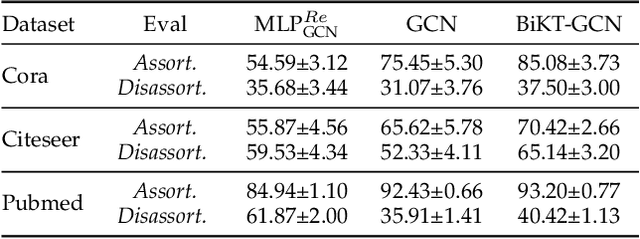

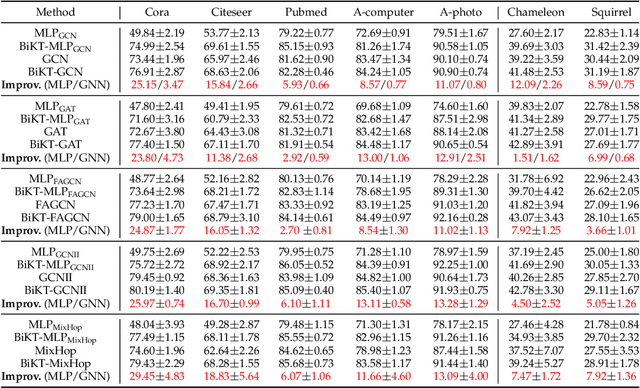
Based on the message-passing paradigm, there has been an amount of research proposing diverse and impressive feature propagation mechanisms to improve the performance of GNNs. However, less focus has been put on feature transformation, another major operation of the message-passing framework. In this paper, we first empirically investigate the performance of the feature transformation operation in several typical GNNs. Unexpectedly, we notice that GNNs do not completely free up the power of the inherent feature transformation operation. By this observation, we propose the Bi-directional Knowledge Transfer (BiKT), a plug-and-play approach to unleash the potential of the feature transformation operations without modifying the original architecture. Taking the feature transformation operation as a derived representation learning model that shares parameters with the original GNN, the direct prediction by this model provides a topological-agnostic knowledge feedback that can further instruct the learning of GNN and the feature transformations therein. On this basis, BiKT not only allows us to acquire knowledge from both the GNN and its derived model but promotes each other by injecting the knowledge into the other. In addition, a theoretical analysis is further provided to demonstrate that BiKT improves the generalization bound of the GNNs from the perspective of domain adaption. An extensive group of experiments on up to 7 datasets with 5 typical GNNs demonstrates that BiKT brings up to 0.5% - 4% performance gain over the original GNN, which means a boosted GNN is obtained. Meanwhile, the derived model also shows a powerful performance to compete with or even surpass the original GNN, enabling us to flexibly apply it independently to some other specific downstream tasks.
Neural Node Matching for Multi-Target Cross Domain Recommendation
Feb 12, 2023



Multi-Target Cross Domain Recommendation(CDR) has attracted a surge of interest recently, which intends to improve the recommendation performance in multiple domains (or systems) simultaneously. Most existing multi-target CDR frameworks primarily rely on the existence of the majority of overlapped users across domains. However, general practical CDR scenarios cannot meet the strictly overlapping requirements and only share a small margin of common users across domains}. Additionally, the majority of users have quite a few historical behaviors in such small-overlapping CDR scenarios}. To tackle the aforementioned issues, we propose a simple-yet-effective neural node matching based framework for more general CDR settings, i.e., only (few) partially overlapped users exist across domains and most overlapped as well as non-overlapped users do have sparse interactions. The present framework} mainly contains two modules: (i) intra-to-inter node matching module, and (ii) intra node complementing module. Concretely, the first module conducts intra-knowledge fusion within each domain and subsequent inter-knowledge fusion across domains by fully connected user-user homogeneous graph information aggregating.
* 13pages
Node-oriented Spectral Filtering for Graph Neural Networks
Dec 07, 2022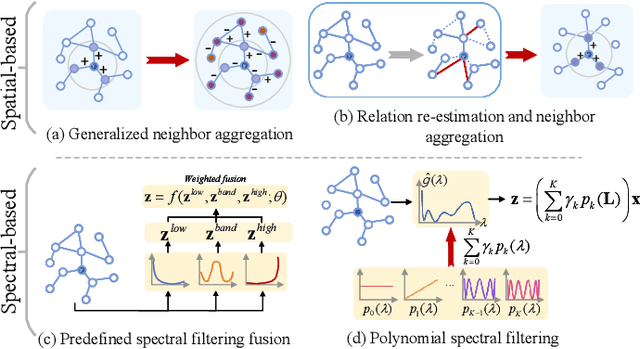

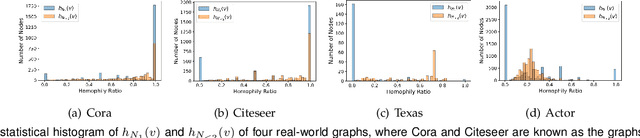
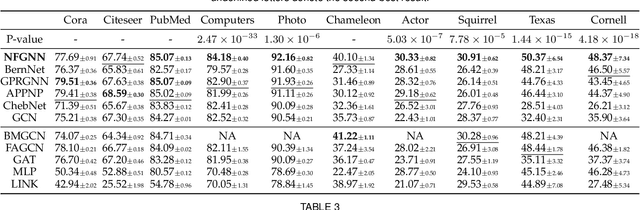
Graph neural networks (GNNs) have shown remarkable performance on homophilic graph data while being far less impressive when handling non-homophilic graph data due to the inherent low-pass filtering property of GNNs. In general, since the real-world graphs are often a complex mixture of diverse subgraph patterns, learning a universal spectral filter on the graph from the global perspective as in most current works may still suffer from great difficulty in adapting to the variation of local patterns. On the basis of the theoretical analysis on local patterns, we rethink the existing spectral filtering methods and propose the \textbf{\underline{N}}ode-oriented spectral \textbf{\underline{F}}iltering for \textbf{\underline{G}}raph \textbf{\underline{N}}eural \textbf{\underline{N}}etwork (namely NFGNN). By estimating the node-oriented spectral filter for each node, NFGNN is provided with the capability of precise local node positioning via the generalized translated operator, thus discriminating the variations of local homophily patterns adaptively. Meanwhile, the utilization of re-parameterization brings a good trade-off between global consistency and local sensibility for learning the node-oriented spectral filters. Furthermore, we theoretically analyze the localization property of NFGNN, demonstrating that the signal after adaptive filtering is still positioned around the corresponding node. Extensive experimental results demonstrate that the proposed NFGNN achieves more favorable performance.
Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation
Nov 30, 2022In recent years, semi-supervised graph learning with data augmentation (DA) is currently the most commonly used and best-performing method to enhance model robustness in sparse scenarios with few labeled samples. Differing from homogeneous graph, DA in heterogeneous graph has greater challenges: heterogeneity of information requires DA strategies to effectively handle heterogeneous relations, which considers the information contribution of different types of neighbors and edges to the target nodes. Furthermore, over-squashing of information is caused by the negative curvature that formed by the non-uniformity distribution and strong clustering in complex graph. To address these challenges, this paper presents a novel method named Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation (HG-MDA). For the problem of heterogeneity of information in DA, node and topology augmentation strategies are proposed for the characteristics of heterogeneous graph. And meta-relation-based attention is applied as one of the indexes for selecting augmented nodes and edges. For the problem of over-squashing of information, triangle based edge adding and removing are designed to alleviate the negative curvature and bring the gain of topology. Finally, the loss function consists of the cross-entropy loss for labeled data and the consistency regularization for unlabeled data. In order to effectively fuse the prediction results of various DA strategies, the sharpening is used. Existing experiments on public datasets, i.e., ACM, DBLP, OGB, and industry dataset MB show that HG-MDA outperforms current SOTA models. Additionly, HG-MDA is applied to user identification in internet finance scenarios, helping the business to add 30% key users, and increase loans and balances by 3.6%, 11.1%, and 9.8%.
HGV4Risk: Hierarchical Global View-guided Sequence Representation Learning for Risk Prediction
Nov 15, 2022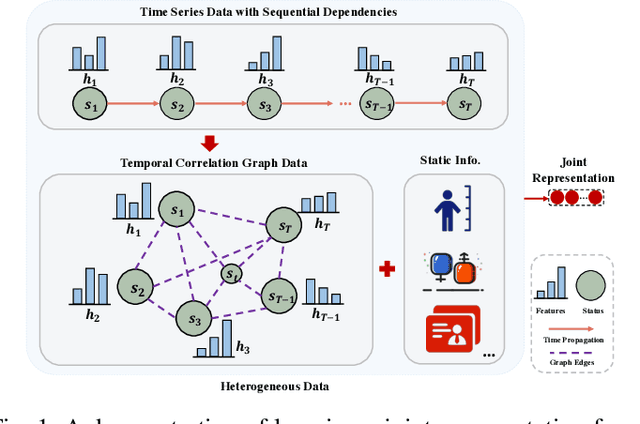
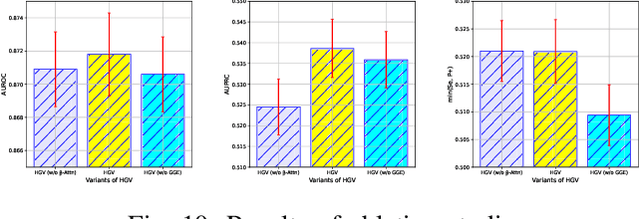
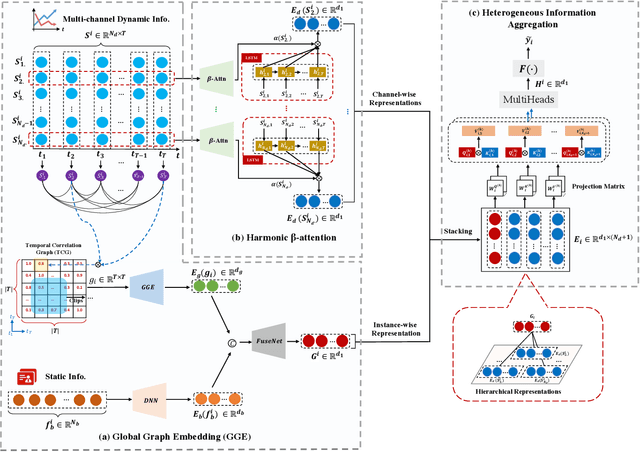
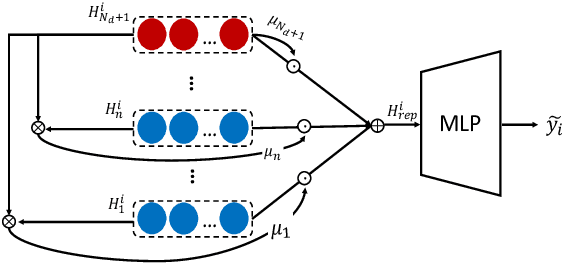
Risk prediction, as a typical time series modeling problem, is usually achieved by learning trends in markers or historical behavior from sequence data, and has been widely applied in healthcare and finance. In recent years, deep learning models, especially Long Short-Term Memory neural networks (LSTMs), have led to superior performances in such sequence representation learning tasks. Despite that some attention or self-attention based models with time-aware or feature-aware enhanced strategies have achieved better performance compared with other temporal modeling methods, such improvement is limited due to a lack of guidance from global view. To address this issue, we propose a novel end-to-end Hierarchical Global View-guided (HGV) sequence representation learning framework. Specifically, the Global Graph Embedding (GGE) module is proposed to learn sequential clip-aware representations from temporal correlation graph at instance level. Furthermore, following the way of key-query attention, the harmonic $\beta$-attention ($\beta$-Attn) is also developed for making a global trade-off between time-aware decay and observation significance at channel level adaptively. Moreover, the hierarchical representations at both instance level and channel level can be coordinated by the heterogeneous information aggregation under the guidance of global view. Experimental results on a benchmark dataset for healthcare risk prediction, and a real-world industrial scenario for Small and Mid-size Enterprises (SMEs) credit overdue risk prediction in MYBank, Ant Group, have illustrated that the proposed model can achieve competitive prediction performance compared with other known baselines.
In progress
Sep 21, 2022The concept of causality plays an important role in human cognition . In the past few decades, causal inference has been well developed in many fields, such as computer science, medicine, economics, and education. With the advancement of deep learning techniques, it has been increasingly used in causal inference against counterfactual data. Typically, deep causal models map the characteristics of covariates to a representation space and then design various objective optimization functions to estimate counterfactual data unbiasedly based on the different optimization methods. This paper focuses on the survey of the deep causal models, and its core contributions are as follows: 1) we provide relevant metrics under multiple treatments and continuous-dose treatment; 2) we incorporate a comprehensive overview of deep causal models from both temporal development and method classification perspectives; 3) we assist a detailed and comprehensive classification and analysis of relevant datasets and source code.
Multi-modal Graph Learning for Disease Prediction
Mar 11, 2022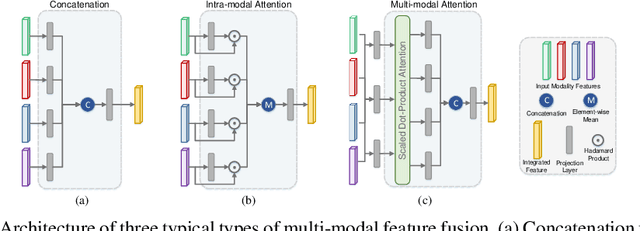
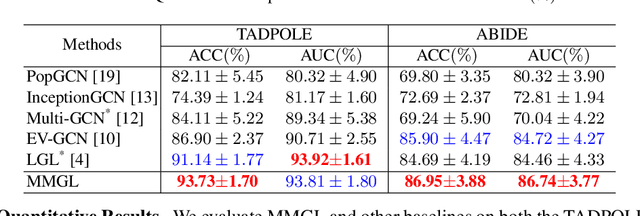
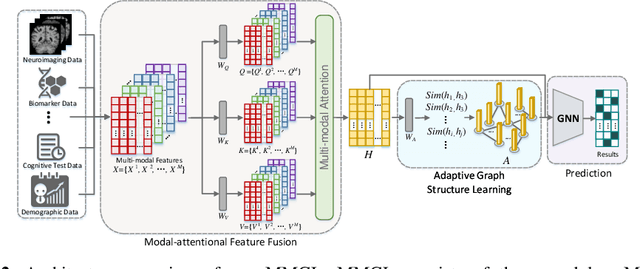
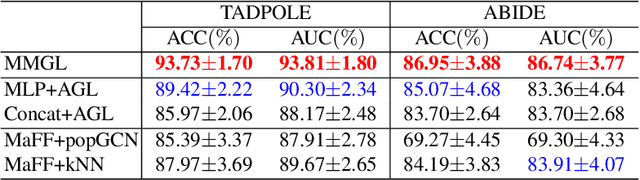
Benefiting from the powerful expressive capability of graphs, graph-based approaches have been popularly applied to handle multi-modal medical data and achieved impressive performance in various biomedical applications. For disease prediction tasks, most existing graph-based methods tend to define the graph manually based on specified modality (e.g., demographic information), and then integrated other modalities to obtain the patient representation by Graph Representation Learning (GRL). However, constructing an appropriate graph in advance is not a simple matter for these methods. Meanwhile, the complex correlation between modalities is ignored. These factors inevitably yield the inadequacy of providing sufficient information about the patient's condition for a reliable diagnosis. To this end, we propose an end-to-end Multi-modal Graph Learning framework (MMGL) for disease prediction with multi-modality. To effectively exploit the rich information across multi-modality associated with the disease, modality-aware representation learning is proposed to aggregate the features of each modality by leveraging the correlation and complementarity between the modalities. Furthermore, instead of defining the graph manually, the latent graph structure is captured through an effective way of adaptive graph learning. It could be jointly optimized with the prediction model, thus revealing the intrinsic connections among samples. Our model is also applicable to the scenario of inductive learning for those unseen data. An extensive group of experiments on two disease prediction tasks demonstrates that the proposed MMGL achieves more favorable performance. The code of MMGL is available at \url{https://github.com/SsGood/MMGL}.