 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the potential of GNNs via Bi-directional Knowledge Transfer
Paper and Code
Oct 26, 2023
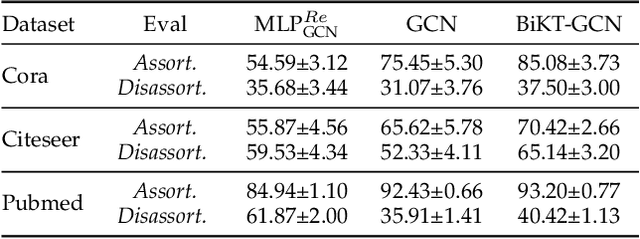

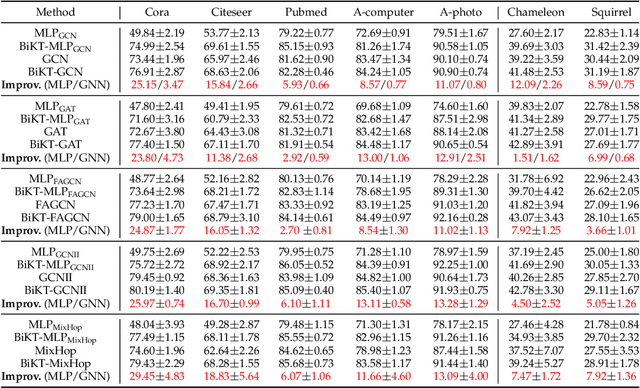
Based on the message-passing paradigm, there has been an amount of research proposing diverse and impressive feature propagation mechanisms to improve the performance of GNNs. However, less focus has been put on feature transformation, another major operation of the message-passing framework. In this paper, we first empirically investigate the performance of the feature transformation operation in several typical GNNs. Unexpectedly, we notice that GNNs do not completely free up the power of the inherent feature transformation operation. By this observation, we propose the Bi-directional Knowledge Transfer (BiKT), a plug-and-play approach to unleash the potential of the feature transformation operations without modifying the original architecture. Taking the feature transformation operation as a derived representation learning model that shares parameters with the original GNN, the direct prediction by this model provides a topological-agnostic knowledge feedback that can further instruct the learning of GNN and the feature transformations therein. On this basis, BiKT not only allows us to acquire knowledge from both the GNN and its derived model but promotes each other by injecting the knowledge into the other. In addition, a theoretical analysis is further provided to demonstrate that BiKT improves the generalization bound of the GNNs from the perspective of domain adaption. An extensive group of experiments on up to 7 datasets with 5 typical GNNs demonstrates that BiKT brings up to 0.5% - 4% performance gain over the original GNN, which means a boosted GNN is obtained. Meanwhile, the derived model also shows a powerful performance to compete with or even surpass the original GNN, enabling us to flexibly apply it independently to some other specific downstream tasks.