 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the potential of GNNs via Bi-directional Knowledge Transfer
Oct 26, 2023
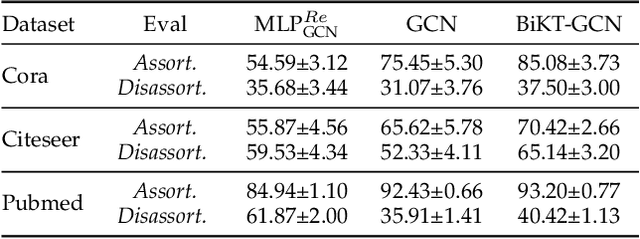

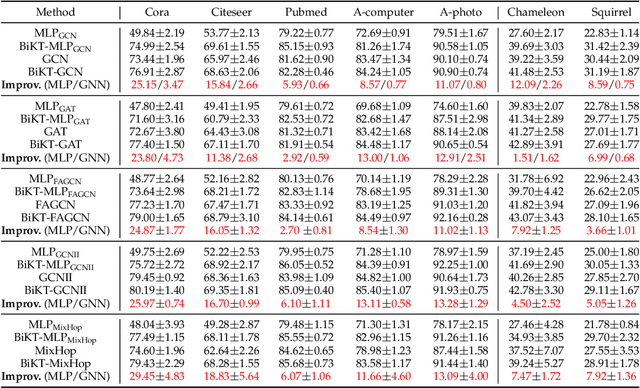
Based on the message-passing paradigm, there has been an amount of research proposing diverse and impressive feature propagation mechanisms to improve the performance of GNNs. However, less focus has been put on feature transformation, another major operation of the message-passing framework. In this paper, we first empirically investigate the performance of the feature transformation operation in several typical GNNs. Unexpectedly, we notice that GNNs do not completely free up the power of the inherent feature transformation operation. By this observation, we propose the Bi-directional Knowledge Transfer (BiKT), a plug-and-play approach to unleash the potential of the feature transformation operations without modifying the original architecture. Taking the feature transformation operation as a derived representation learning model that shares parameters with the original GNN, the direct prediction by this model provides a topological-agnostic knowledge feedback that can further instruct the learning of GNN and the feature transformations therein. On this basis, BiKT not only allows us to acquire knowledge from both the GNN and its derived model but promotes each other by injecting the knowledge into the other. In addition, a theoretical analysis is further provided to demonstrate that BiKT improves the generalization bound of the GNNs from the perspective of domain adaption. An extensive group of experiments on up to 7 datasets with 5 typical GNNs demonstrates that BiKT brings up to 0.5% - 4% performance gain over the original GNN, which means a boosted GNN is obtained. Meanwhile, the derived model also shows a powerful performance to compete with or even surpass the original GNN, enabling us to flexibly apply it independently to some other specific downstream tasks.
Node-oriented Spectral Filtering for Graph Neural Networks
Dec 07, 2022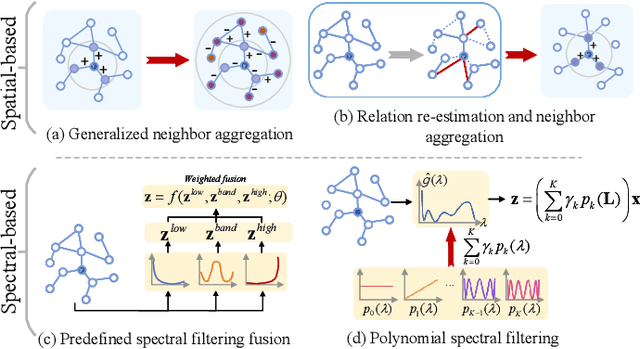

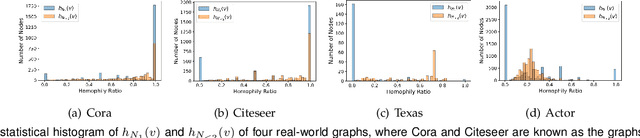
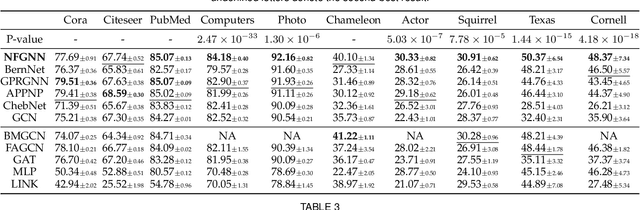
Graph neural networks (GNNs) have shown remarkable performance on homophilic graph data while being far less impressive when handling non-homophilic graph data due to the inherent low-pass filtering property of GNNs. In general, since the real-world graphs are often a complex mixture of diverse subgraph patterns, learning a universal spectral filter on the graph from the global perspective as in most current works may still suffer from great difficulty in adapting to the variation of local patterns. On the basis of the theoretical analysis on local patterns, we rethink the existing spectral filtering methods and propose the \textbf{\underline{N}}ode-oriented spectral \textbf{\underline{F}}iltering for \textbf{\underline{G}}raph \textbf{\underline{N}}eural \textbf{\underline{N}}etwork (namely NFGNN). By estimating the node-oriented spectral filter for each node, NFGNN is provided with the capability of precise local node positioning via the generalized translated operator, thus discriminating the variations of local homophily patterns adaptively. Meanwhile, the utilization of re-parameterization brings a good trade-off between global consistency and local sensibility for learning the node-oriented spectral filters. Furthermore, we theoretically analyze the localization property of NFGNN, demonstrating that the signal after adaptive filtering is still positioned around the corresponding node. Extensive experimental results demonstrate that the proposed NFGNN achieves more favorable performance.
Multi-modal Graph Learning for Disease Prediction
Mar 11, 2022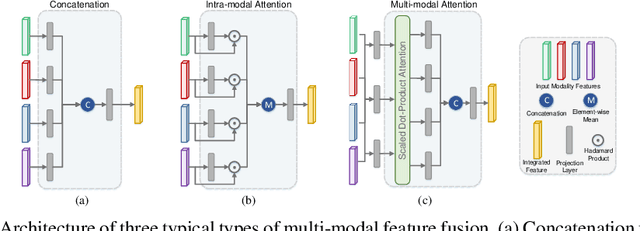
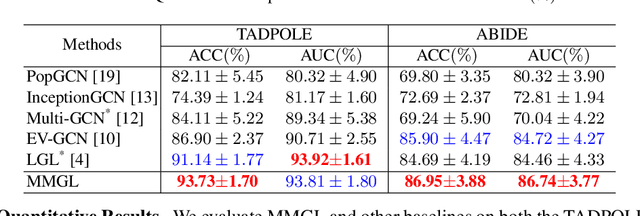
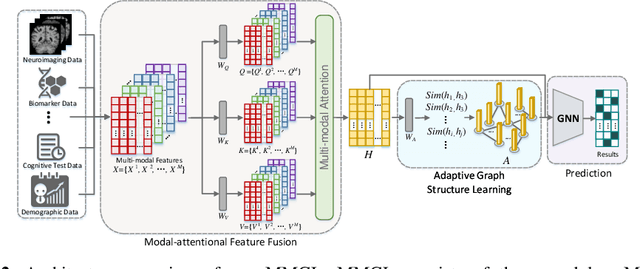
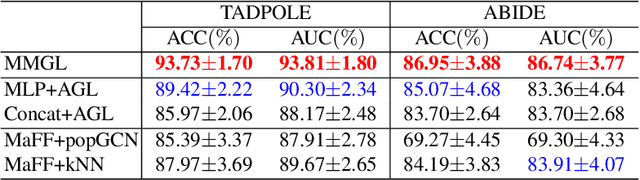
Benefiting from the powerful expressive capability of graphs, graph-based approaches have been popularly applied to handle multi-modal medical data and achieved impressive performance in various biomedical applications. For disease prediction tasks, most existing graph-based methods tend to define the graph manually based on specified modality (e.g., demographic information), and then integrated other modalities to obtain the patient representation by Graph Representation Learning (GRL). However, constructing an appropriate graph in advance is not a simple matter for these methods. Meanwhile, the complex correlation between modalities is ignored. These factors inevitably yield the inadequacy of providing sufficient information about the patient's condition for a reliable diagnosis. To this end, we propose an end-to-end Multi-modal Graph Learning framework (MMGL) for disease prediction with multi-modality. To effectively exploit the rich information across multi-modality associated with the disease, modality-aware representation learning is proposed to aggregate the features of each modality by leveraging the correlation and complementarity between the modalities. Furthermore, instead of defining the graph manually, the latent graph structure is captured through an effective way of adaptive graph learning. It could be jointly optimized with the prediction model, thus revealing the intrinsic connections among samples. Our model is also applicable to the scenario of inductive learning for those unseen data. An extensive group of experiments on two disease prediction tasks demonstrates that the proposed MMGL achieves more favorable performance. The code of MMGL is available at \url{https://github.com/SsGood/MMGL}.
CETransformer: Casual Effect Estimation via Transformer Based Representation Learning
Jul 19, 2021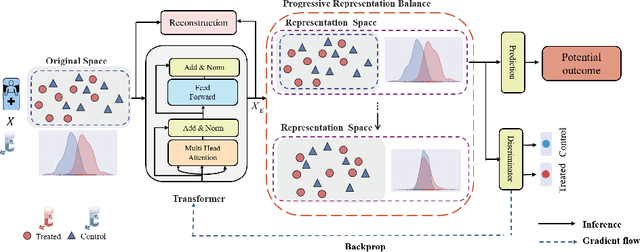
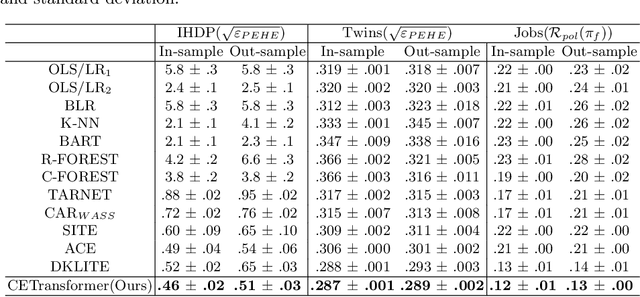
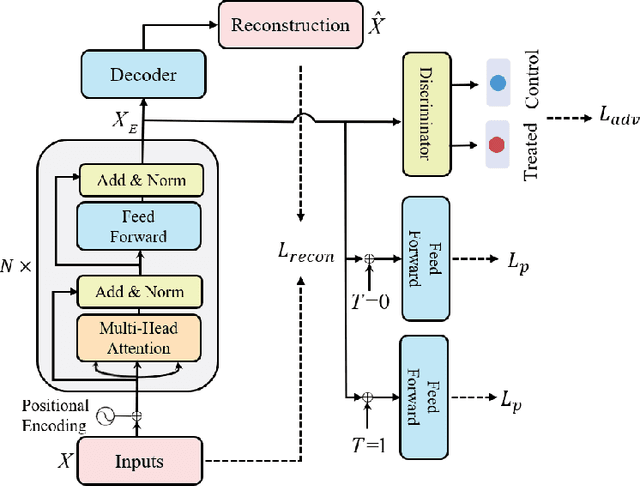
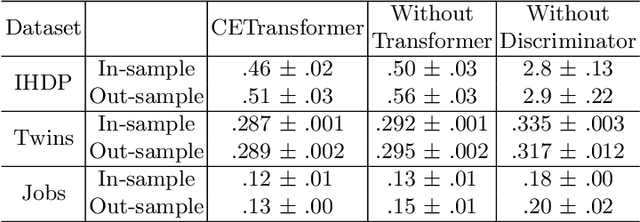
Treatment effect estimation, which refers to the estimation of causal effects and aims to measure the strength of the causal relationship, is of great importance in many fields but is a challenging problem in practice. As present, data-driven causal effect estimation faces two main challenges, i.e., selection bias and the missing of counterfactual. To address these two issues, most of the existing approaches tend to reduce the selection bias by learning a balanced representation, and then to estimate the counterfactual through the representation. However, they heavily rely on the finely hand-crafted metric functions when learning balanced representations, which generally doesn't work well for the situations where the original distribution is complicated. In this paper, we propose a CETransformer model for casual effect estimation via transformer based representation learning. To learn the representation of covariates(features) robustly, a self-supervised transformer is proposed, by which the correlation between covariates can be well exploited through self-attention mechanism. In addition, an adversarial network is adopted to balance the distribution of the treated and control groups in the representation space. Experimental results on three real-world datasets demonstrate the advantages of the proposed CETransformer, compared with the state-of-the-art treatment effect estimation methods.
Margin Preserving Self-paced Contrastive Learning Towards Domain Adaptation for Medical Image Segmentation
Mar 15, 2021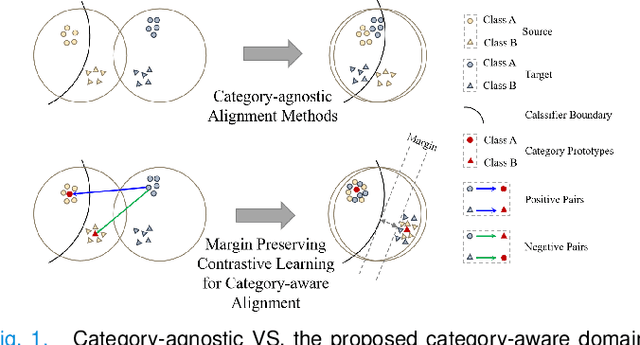
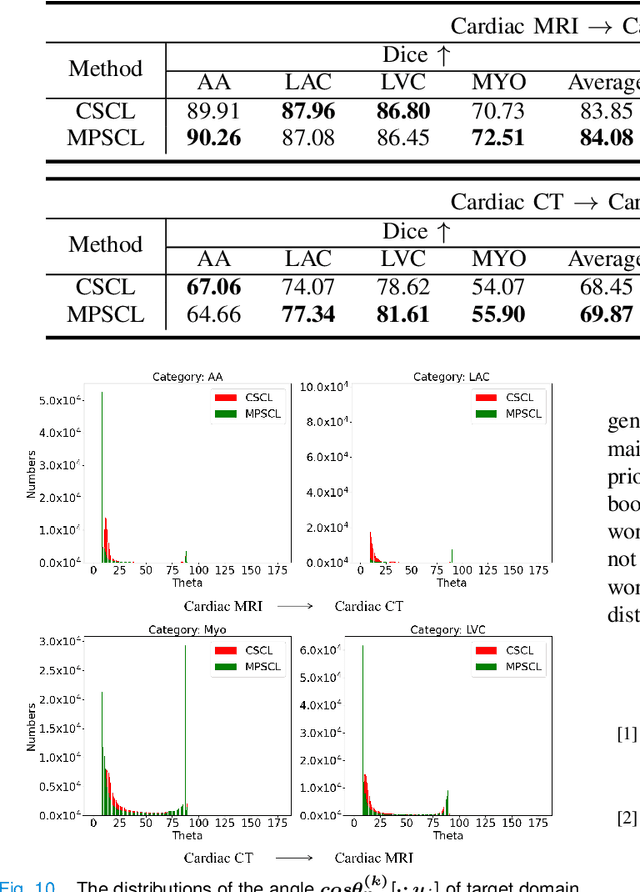
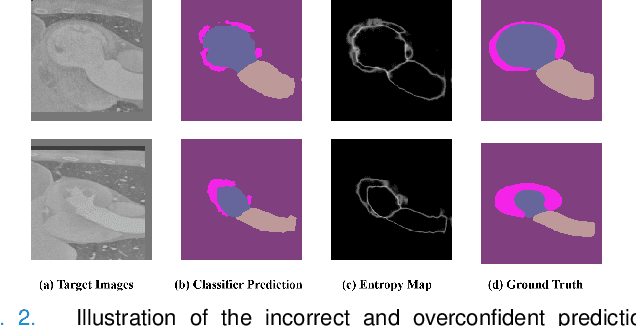
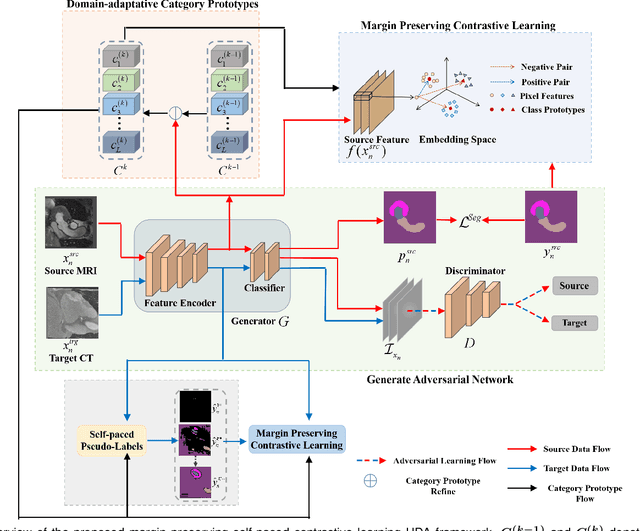
To bridge the gap between the source and target domains in unsupervised domain adaptation (UDA), the most common strategy puts focus on matching the marginal distributions in the feature space through adversarial learning. However, such category-agnostic global alignment lacks of exploiting the class-level joint distributions, causing the aligned distribution less discriminative. To address this issue, we propose in this paper a novel margin preserving self-paced contrastive Learning (MPSCL) model for cross-modal medical image segmentation. Unlike the conventional construction of contrastive pairs in contrastive learning, the domain-adaptive category prototypes are utilized to constitute the positive and negative sample pairs. With the guidance of progressively refined semantic prototypes, a novel margin preserving contrastive loss is proposed to boost the discriminability of embedded representation space. To enhance the supervision for contrastive learning, more informative pseudo-labels are generated in target domain in a self-paced way, thus benefiting the category-aware distribution alignment for UDA. Furthermore, the domain-invariant representations are learned through joint contrastive learning between the two domains. Extensive experiments on cross-modal cardiac segmentation tasks demonstrate that MPSCL significantly improves semantic segmentation performance, and outperforms a wide variety of state-of-the-art methods by a large margin.
Adversarial Graph Disentanglement
Mar 12, 2021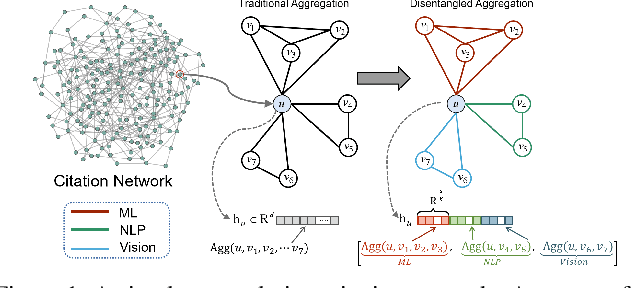
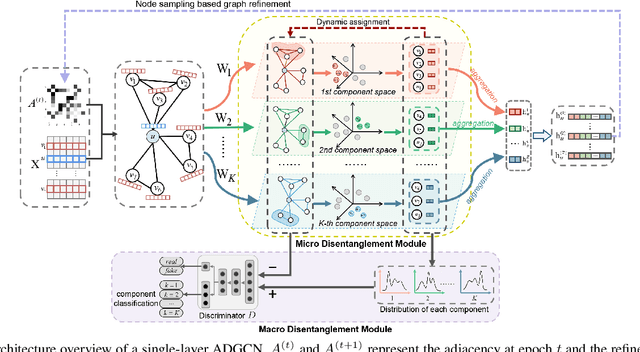
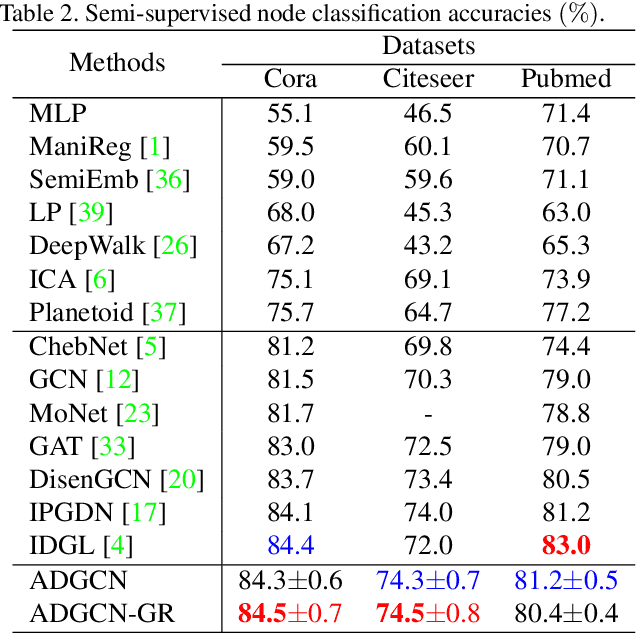
A real-world graph has a complex topology structure, which is often formed by the interaction of different latent factors. Disentanglement of these latent factors can effectively improve the robustness and interpretability of node representation of the graph. However, most existing methods lack consideration of the intrinsic differences in links caused by factor entanglement. In this paper, we propose an Adversarial Disentangled Graph Convolutional Network (ADGCN) for disentangled graph representation learning. Specifically, a dynamic multi-component convolution layer is designed to achieve micro-disentanglement by inferring latent components that caused links between nodes. On the basis of micro-disentanglement, we further propose a macro-disentanglement adversarial regularizer that improves the separability between component distributions, thus restricting interdependence among components. Additionally, to learn collaboratively a better disentangled representation and topological structure, a diversity preserving node sampling-based progressive refinement of graph structure is proposed. The experimental results on various real-world graph data verify that our ADGCN obtains remarkably more favorable performance over currently available alternatives.
Taking Modality-free Human Identification as Zero-shot Learning
Oct 02, 2020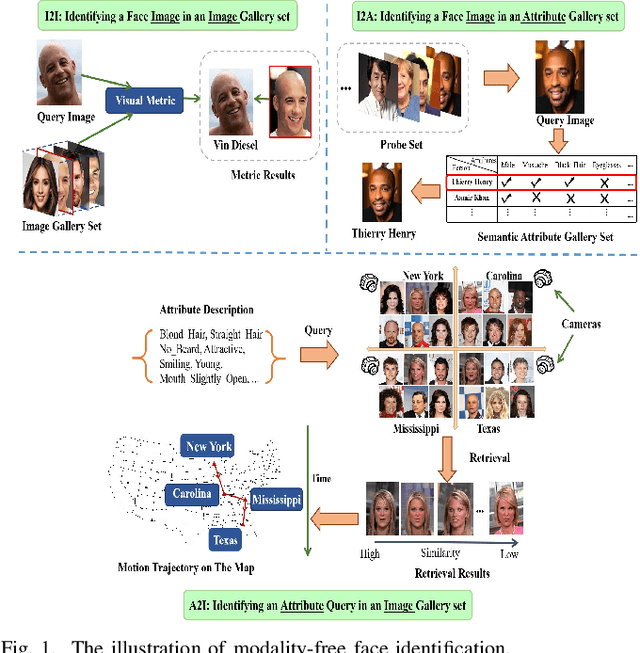
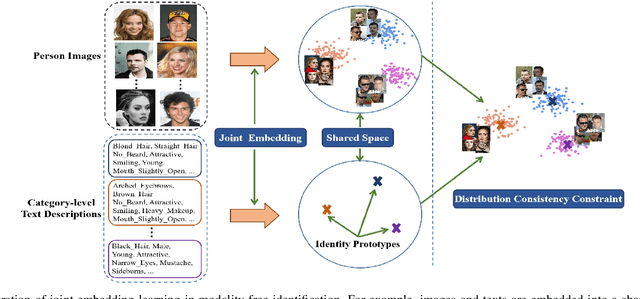
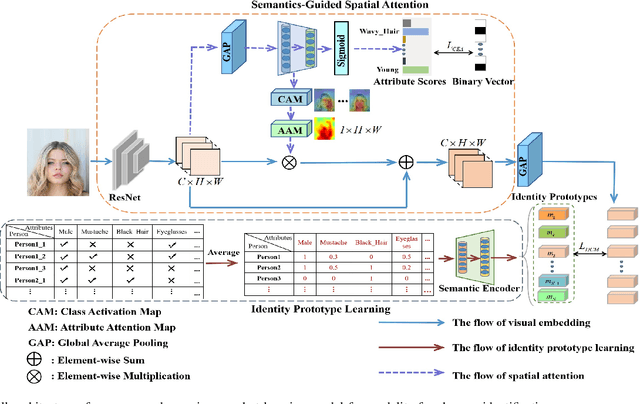

Human identification is an important topic in event detection, person tracking, and public security. There have been numerous methods proposed for human identification, such as face identification, person re-identification, and gait identification. Typically, existing methods predominantly classify a queried image to a specific identity in an image gallery set (I2I). This is seriously limited for the scenario where only a textual description of the query or an attribute gallery set is available in a wide range of video surveillance applications (A2I or I2A). However, very few efforts have been devoted towards modality-free identification, i.e., identifying a query in a gallery set in a scalable way. In this work, we take an initial attempt, and formulate such a novel Modality-Free Human Identification (named MFHI) task as a generic zero-shot learning model in a scalable way. Meanwhile, it is capable of bridging the visual and semantic modalities by learning a discriminative prototype of each identity. In addition, the semantics-guided spatial attention is enforced on visual modality to obtain representations with both high global category-level and local attribute-level discrimination. Finally, we design and conduct an extensive group of experiments on two common challenging identification tasks, including face identification and person re-identification, demonstrating that our method outperforms a wide variety of state-of-the-art methods on modality-free human identification.
Distribution-induced Bidirectional Generative Adversarial Network for Graph Representation Learning
Dec 04, 2019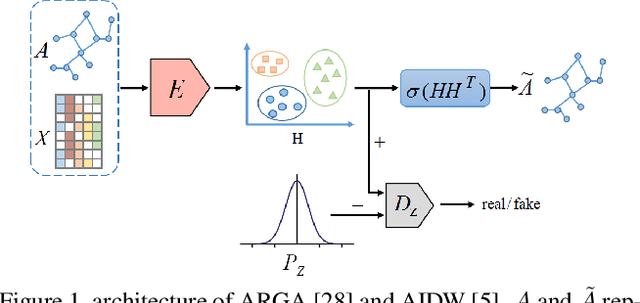
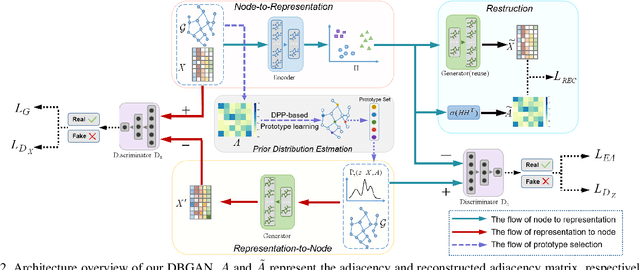
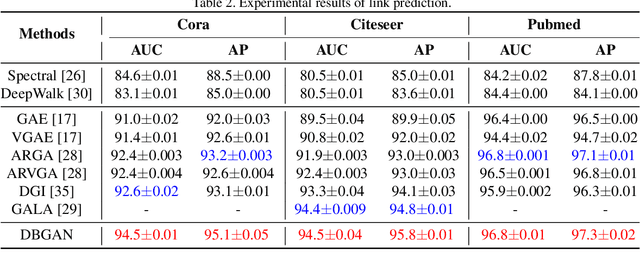
Graph representation learning aims to encode all nodes of a graph into low-dimensional vectors that will serve as input of many compute vision tasks. However, most existing algorithms ignore the existence of inherent data distribution and even noises. This may significantly increase the phenomenon of over-fitting and deteriorate the testing accuracy. In this paper, we propose a Distribution-induced Bidirectional Generative Adversarial Network (named DBGAN) for graph representation learning. Instead of the widely used normal distribution assumption, the prior distribution of latent representation in our DBGAN is estimated in a structure-aware way, which implicitly bridges the graph and feature spaces by prototype learning. Thus discriminative and robust representations are generated for all nodes. Furthermore, to improve their generalization ability while preserving representation ability, the sample-level and distribution-level consistency is well balanced via a bidirectional adversarial learning framework. An extensive group of experiments are then carefully designed and presented, demonstrating that our DBGAN obtains remarkably more favorable trade-off between representation and robustness, and meanwhile is dimension-efficient, over currently available alternatives in various tasks.
Convolutional Prototype Learning for Zero-Shot Recognition
Oct 24, 2019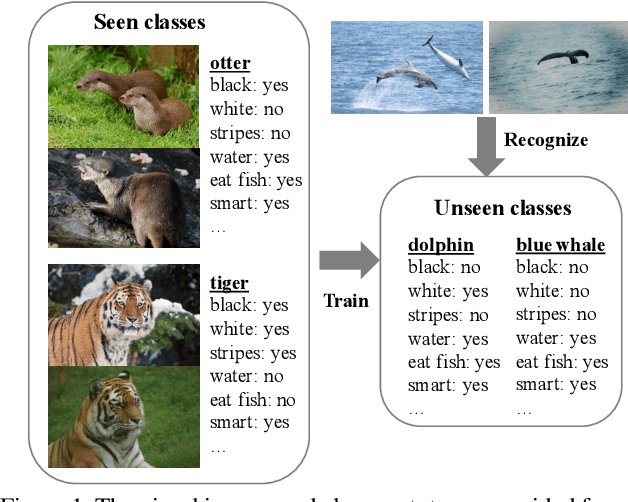


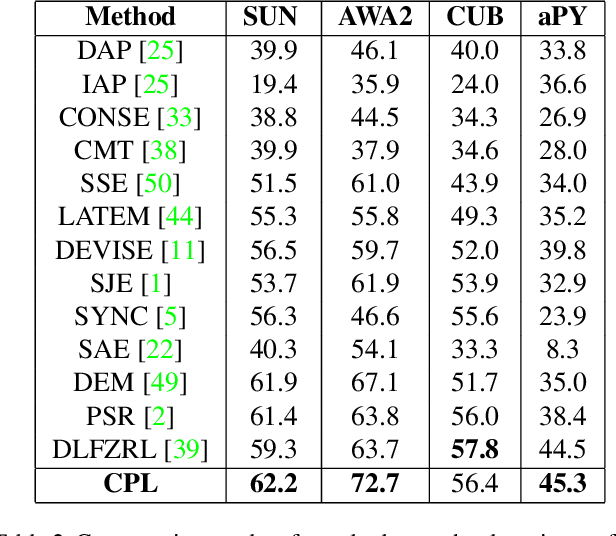
Zero-shot learning (ZSL) has received increasing attention in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. The key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary class attribute vectors. However, the popularly learned projection functions in previous works cannot generalize well since they assume the distribution consistency between seen and unseen domains at sample-level.Besides, the provided non-visual and unique class attributes can significantly degrade the recognition performance in semantic space. In this paper, we propose a simple yet effective convolutional prototype learning (CPL) framework for zero-shot recognition. By assuming distribution consistency at task-level, our CPL is capable of transferring knowledge smoothly to recognize unseen samples.Furthermore, inside each task, discriminative visual prototypes are learned via a distance based training mechanism. Consequently, we can perform recognition in visual space, instead of semantic space. An extensive group of experiments are then carefully designed and presented, demonstrating that CPL obtains more favorable effectiveness, over currently available alternatives under various settings.