 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
GRAFT: Grid-Aware Load Forecasting with Multi-Source Textual Alignment and Fusion
Dec 16, 2025



Electric load is simultaneously affected across multiple time scales by exogenous factors such as weather and calendar rhythms, sudden events, and policies. Therefore, this paper proposes GRAFT (GRid-Aware Forecasting with Text), which modifies and improves STanHOP to better support grid-aware forecasting and multi-source textual interventions. Specifically, GRAFT strictly aligns daily-aggregated news, social media, and policy texts with half-hour load, and realizes text-guided fusion to specific time positions via cross-attention during both training and rolling forecasting. In addition, GRAFT provides a plug-and-play external-memory interface to accommodate different information sources in real-world deployment. We construct and release a unified aligned benchmark covering 2019--2021 for five Australian states (half-hour load, daily-aligned weather/calendar variables, and three categories of external texts), and conduct systematic, reproducible evaluations at three scales -- hourly, daily, and monthly -- under a unified protocol for comparison across regions, external sources, and time scales. Experimental results show that GRAFT significantly outperforms strong baselines and reaches or surpasses the state of the art across multiple regions and forecasting horizons. Moreover, the model is robust in event-driven scenarios and enables temporal localization and source-level interpretation of text-to-load effects through attention read-out. We release the benchmark, preprocessing scripts, and forecasting results to facilitate standardized empirical evaluation and reproducibility in power grid load forecasting.
Causal Mean Field Multi-Agent Reinforcement Learning
Feb 20, 2025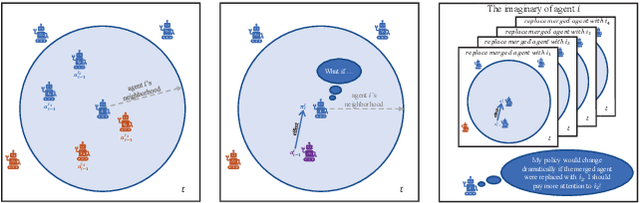
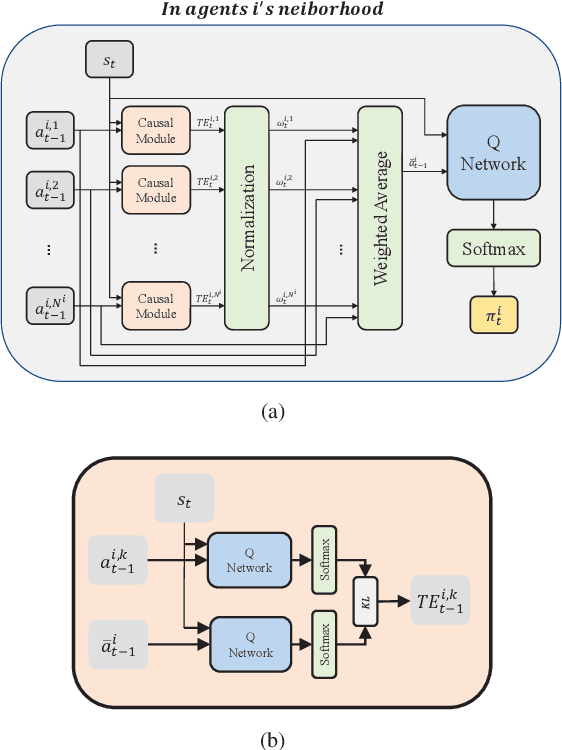
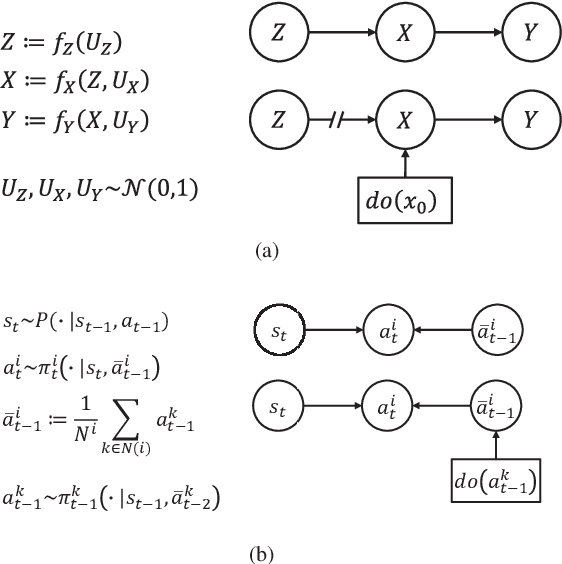
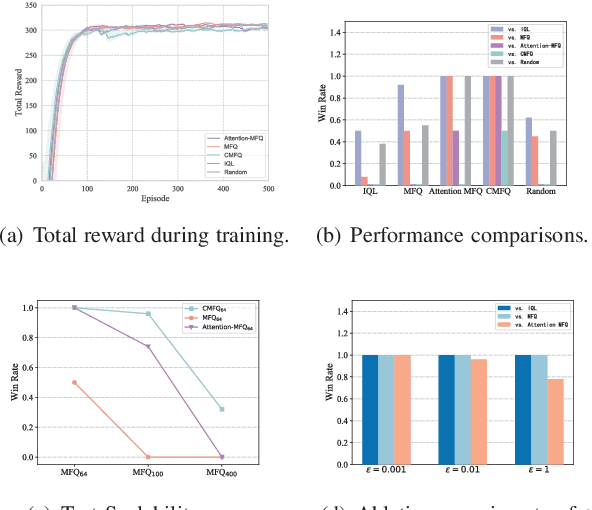
Scalability remains a challenge in multi-agent reinforcement learning and is currently under active research. A framework named mean-field reinforcement learning (MFRL) could alleviate the scalability problem by employing the Mean Field Theory to turn a many-agent problem into a two-agent problem. However, this framework lacks the ability to identify essential interactions under nonstationary environments. Causality contains relatively invariant mechanisms behind interactions, though environments are nonstationary. Therefore, we propose an algorithm called causal mean-field Q-learning (CMFQ) to address the scalability problem. CMFQ is ever more robust toward the change of the number of agents though inheriting the compressed representation of MFRL's action-state space. Firstly, we model the causality behind the decision-making process of MFRL into a structural causal model (SCM). Then the essential degree of each interaction is quantified via intervening on the SCM. Furthermore, we design the causality-aware compact representation for behavioral information of agents as the weighted sum of all behavioral information according to their causal effects. We test CMFQ in a mixed cooperative-competitive game and a cooperative game. The result shows that our method has excellent scalability performance in both training in environments containing a large number of agents and testing in environments containing much more agents.
Decoupling Knowledge and Reasoning in Transformers: A Modular Architecture with Generalized Cross-Attention
Jan 06, 2025Transformers have achieved remarkable success across diverse domains, but their monolithic architecture presents challenges in interpretability, adaptability, and scalability. This paper introduces a novel modular Transformer architecture that explicitly decouples knowledge and reasoning through a generalized cross-attention mechanism to a globally shared knowledge base with layer-specific transformations, specifically designed for effective knowledge retrieval. Critically, we provide a rigorous mathematical derivation demonstrating that the Feed-Forward Network (FFN) in a standard Transformer is a specialized case (a closure) of this generalized cross-attention, revealing its role in implicit knowledge retrieval and validating our design. This theoretical framework provides a new lens for understanding FFNs and lays the foundation for future research exploring enhanced interpretability, adaptability, and scalability, enabling richer interplay with external knowledge bases and other systems.
AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production
Mar 12, 2024The Agent and AIGC (Artificial Intelligence Generated Content) technologies have recently made significant progress. We propose AesopAgent, an Agent-driven Evolutionary System on Story-to-Video Production. AesopAgent is a practical application of agent technology for multimodal content generation. The system integrates multiple generative capabilities within a unified framework, so that individual users can leverage these modules easily. This innovative system would convert user story proposals into scripts, images, and audio, and then integrate these multimodal contents into videos. Additionally, the animating units (e.g., Gen-2 and Sora) could make the videos more infectious. The AesopAgent system could orchestrate task workflow for video generation, ensuring that the generated video is both rich in content and coherent. This system mainly contains two layers, i.e., the Horizontal Layer and the Utility Layer. In the Horizontal Layer, we introduce a novel RAG-based evolutionary system that optimizes the whole video generation workflow and the steps within the workflow. It continuously evolves and iteratively optimizes workflow by accumulating expert experience and professional knowledge, including optimizing the LLM prompts and utilities usage. The Utility Layer provides multiple utilities, leading to consistent image generation that is visually coherent in terms of composition, characters, and style. Meanwhile, it provides audio and special effects, integrating them into expressive and logically arranged videos. Overall, our AesopAgent achieves state-of-the-art performance compared with many previous works in visual storytelling. Our AesopAgent is designed for convenient service for individual users, which is available on the following page: https://aesopai.github.io/.
PT-Tuning: Bridging the Gap between Time Series Masked Reconstruction and Forecasting via Prompt Token Tuning
Nov 07, 2023



Self-supervised learning has been actively studied in time series domain recently, especially for masked reconstruction. Most of these methods follow the "Pre-training + Fine-tuning" paradigm in which a new decoder replaces the pre-trained decoder to fit for a specific downstream task, leading to inconsistency of upstream and downstream tasks. In this paper, we first point out that the unification of task objectives and adaptation for task difficulty are critical for bridging the gap between time series masked reconstruction and forecasting. By reserving the pre-trained mask token during fine-tuning stage, the forecasting task can be taken as a special case of masked reconstruction, where the future values are masked and reconstructed based on history values. It guarantees the consistency of task objectives but there is still a gap in task difficulty. Because masked reconstruction can utilize contextual information while forecasting can only use historical information to reconstruct. To further mitigate the existed gap, we propose a simple yet effective prompt token tuning (PT-Tuning) paradigm, in which all pre-trained parameters are frozen and only a few trainable prompt tokens are added to extended mask tokens in element-wise manner. Extensive experiments on real-world datasets demonstrate the superiority of our proposed paradigm with state-of-the-art performance compared to representation learning and end-to-end supervised forecasting methods.
In progress
Sep 21, 2022The concept of causality plays an important role in human cognition . In the past few decades, causal inference has been well developed in many fields, such as computer science, medicine, economics, and education. With the advancement of deep learning techniques, it has been increasingly used in causal inference against counterfactual data. Typically, deep causal models map the characteristics of covariates to a representation space and then design various objective optimization functions to estimate counterfactual data unbiasedly based on the different optimization methods. This paper focuses on the survey of the deep causal models, and its core contributions are as follows: 1) we provide relevant metrics under multiple treatments and continuous-dose treatment; 2) we incorporate a comprehensive overview of deep causal models from both temporal development and method classification perspectives; 3) we assist a detailed and comprehensive classification and analysis of relevant datasets and source code.
Multi-modal Graph Learning for Disease Prediction
Mar 11, 2022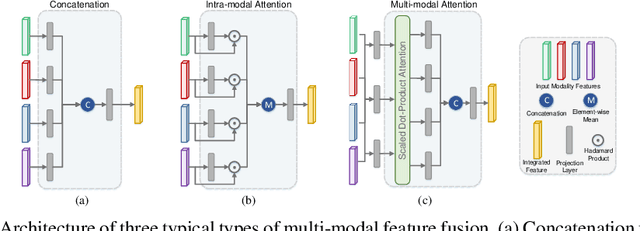
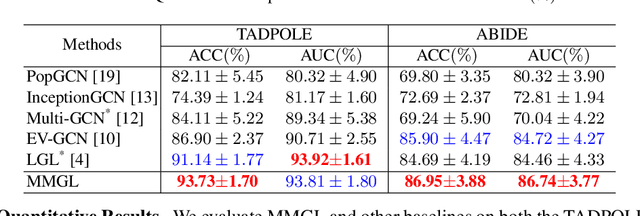
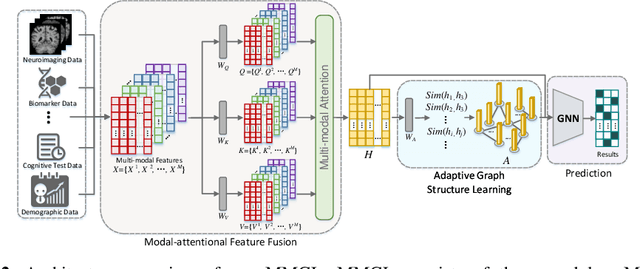
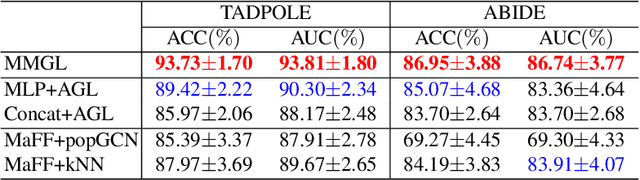
Benefiting from the powerful expressive capability of graphs, graph-based approaches have been popularly applied to handle multi-modal medical data and achieved impressive performance in various biomedical applications. For disease prediction tasks, most existing graph-based methods tend to define the graph manually based on specified modality (e.g., demographic information), and then integrated other modalities to obtain the patient representation by Graph Representation Learning (GRL). However, constructing an appropriate graph in advance is not a simple matter for these methods. Meanwhile, the complex correlation between modalities is ignored. These factors inevitably yield the inadequacy of providing sufficient information about the patient's condition for a reliable diagnosis. To this end, we propose an end-to-end Multi-modal Graph Learning framework (MMGL) for disease prediction with multi-modality. To effectively exploit the rich information across multi-modality associated with the disease, modality-aware representation learning is proposed to aggregate the features of each modality by leveraging the correlation and complementarity between the modalities. Furthermore, instead of defining the graph manually, the latent graph structure is captured through an effective way of adaptive graph learning. It could be jointly optimized with the prediction model, thus revealing the intrinsic connections among samples. Our model is also applicable to the scenario of inductive learning for those unseen data. An extensive group of experiments on two disease prediction tasks demonstrates that the proposed MMGL achieves more favorable performance. The code of MMGL is available at \url{https://github.com/SsGood/MMGL}.
CETransformer: Casual Effect Estimation via Transformer Based Representation Learning
Jul 19, 2021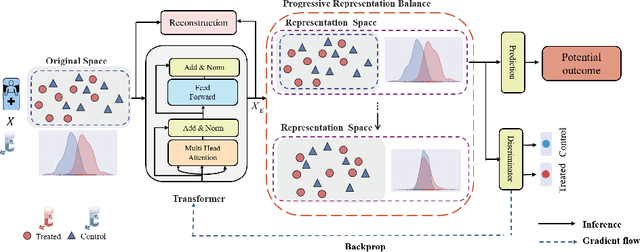
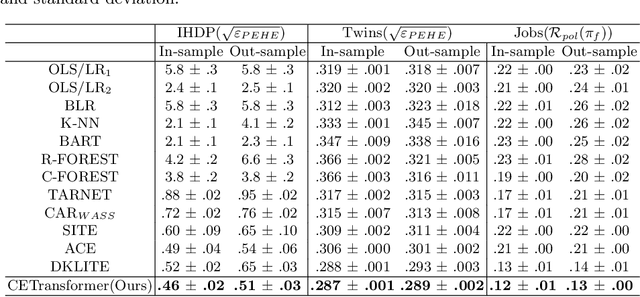
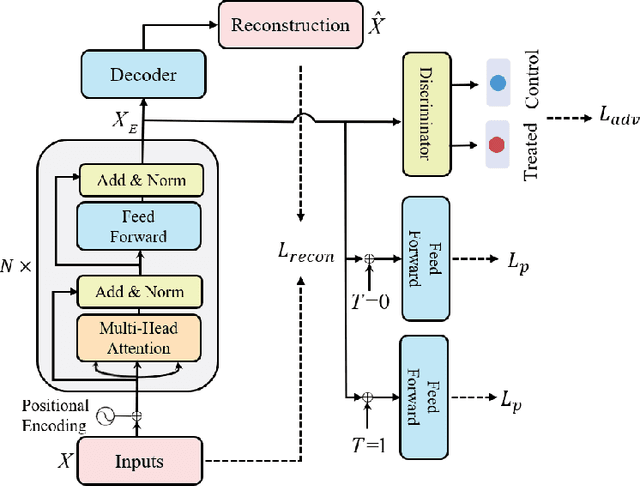
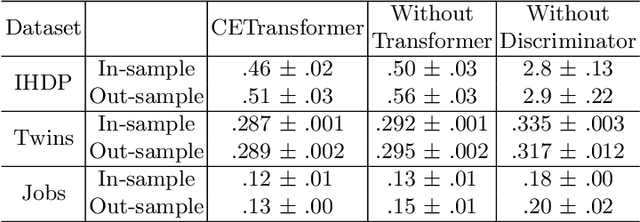
Treatment effect estimation, which refers to the estimation of causal effects and aims to measure the strength of the causal relationship, is of great importance in many fields but is a challenging problem in practice. As present, data-driven causal effect estimation faces two main challenges, i.e., selection bias and the missing of counterfactual. To address these two issues, most of the existing approaches tend to reduce the selection bias by learning a balanced representation, and then to estimate the counterfactual through the representation. However, they heavily rely on the finely hand-crafted metric functions when learning balanced representations, which generally doesn't work well for the situations where the original distribution is complicated. In this paper, we propose a CETransformer model for casual effect estimation via transformer based representation learning. To learn the representation of covariates(features) robustly, a self-supervised transformer is proposed, by which the correlation between covariates can be well exploited through self-attention mechanism. In addition, an adversarial network is adopted to balance the distribution of the treated and control groups in the representation space. Experimental results on three real-world datasets demonstrate the advantages of the proposed CETransformer, compared with the state-of-the-art treatment effect estimation methods.