 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Trajectory Prediction under Unstructured Constraints
Mar 18, 2025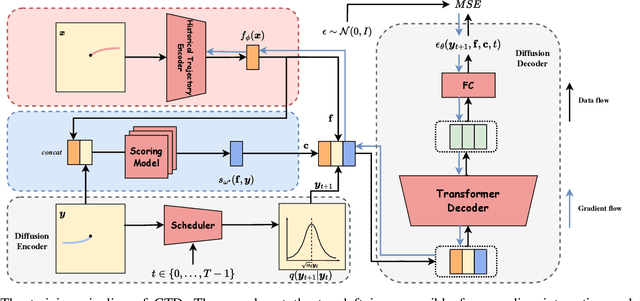
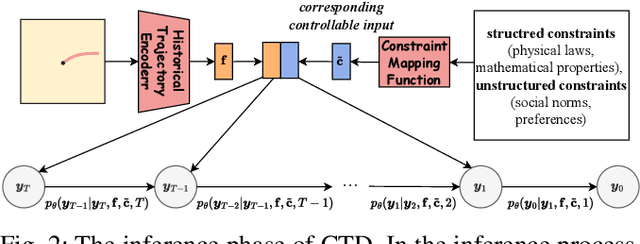
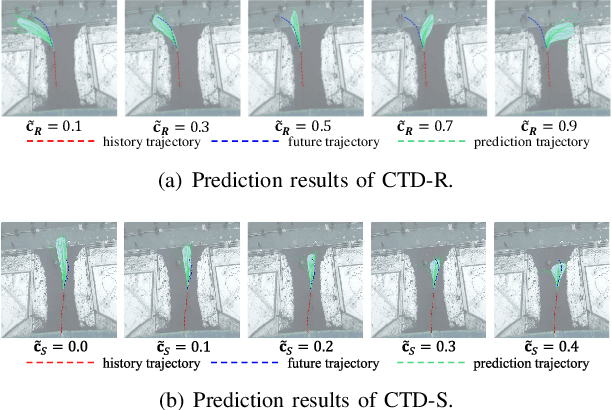
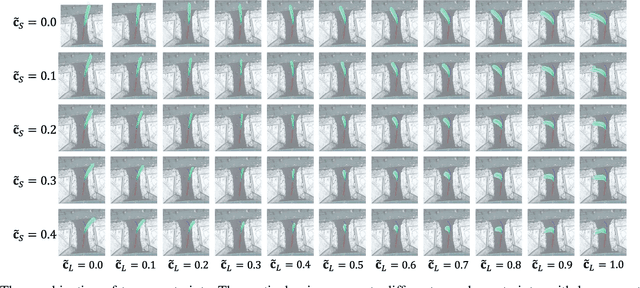
Trajectory prediction facilitates effective planning and decision-making, while constrained trajectory prediction integrates regulation into prediction. Recent advances in constrained trajectory prediction focus on structured constraints by constructing optimization objectives. However, handling unstructured constraints is challenging due to the lack of differentiable formal definitions. To address this, we propose a novel method for constrained trajectory prediction using a conditional generative paradigm, named Controllable Trajectory Diffusion (CTD). The key idea is that any trajectory corresponds to a degree of conformity to a constraint. By quantifying this degree and treating it as a condition, a model can implicitly learn to predict trajectories under unstructured constraints. CTD employs a pre-trained scoring model to predict the degree of conformity (i.e., a score), and uses this score as a condition for a conditional diffusion model to generate trajectories. Experimental results demonstrate that CTD achieves high accuracy on the ETH/UCY and SDD benchmarks. Qualitative analysis confirms that CTD ensures adherence to unstructured constraints and can predict trajectories that satisfy combinatorial constraints.
Causal Mean Field Multi-Agent Reinforcement Learning
Feb 20, 2025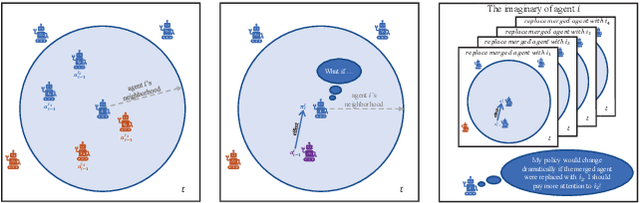
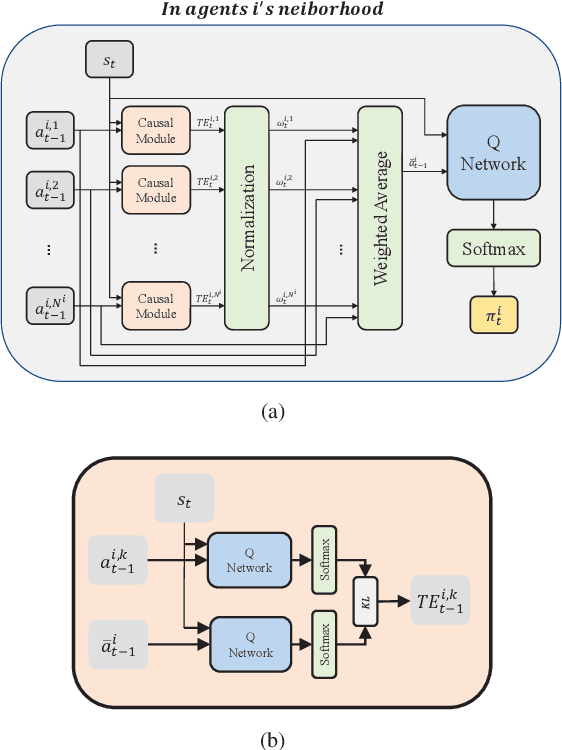
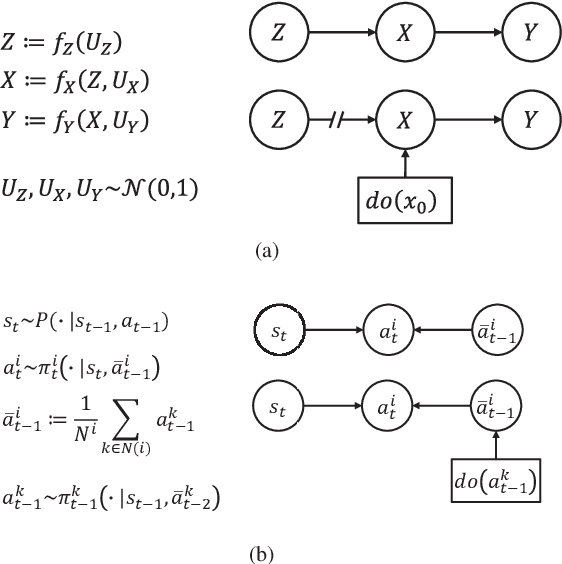
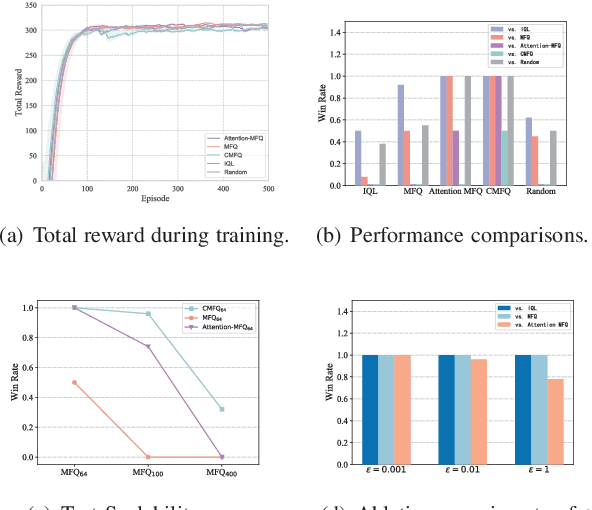
Scalability remains a challenge in multi-agent reinforcement learning and is currently under active research. A framework named mean-field reinforcement learning (MFRL) could alleviate the scalability problem by employing the Mean Field Theory to turn a many-agent problem into a two-agent problem. However, this framework lacks the ability to identify essential interactions under nonstationary environments. Causality contains relatively invariant mechanisms behind interactions, though environments are nonstationary. Therefore, we propose an algorithm called causal mean-field Q-learning (CMFQ) to address the scalability problem. CMFQ is ever more robust toward the change of the number of agents though inheriting the compressed representation of MFRL's action-state space. Firstly, we model the causality behind the decision-making process of MFRL into a structural causal model (SCM). Then the essential degree of each interaction is quantified via intervening on the SCM. Furthermore, we design the causality-aware compact representation for behavioral information of agents as the weighted sum of all behavioral information according to their causal effects. We test CMFQ in a mixed cooperative-competitive game and a cooperative game. The result shows that our method has excellent scalability performance in both training in environments containing a large number of agents and testing in environments containing much more agents.
Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning
Oct 08, 2024



Reinforcement learning (RL) has emerged as a pivotal technique for fine-tuning large language models (LLMs) on specific tasks. However, prevailing RL fine-tuning methods predominantly rely on PPO and its variants. Though these algorithms are effective in general RL settings, they often exhibit suboptimal performance and vulnerability to distribution collapse when applied to the fine-tuning of LLMs. In this paper, we propose CORY, extending the RL fine-tuning of LLMs to a sequential cooperative multi-agent reinforcement learning framework, to leverage the inherent coevolution and emergent capabilities of multi-agent systems. In CORY, the LLM to be fine-tuned is initially duplicated into two autonomous agents: a pioneer and an observer. The pioneer generates responses based on queries, while the observer generates responses using both the queries and the pioneer's responses. The two agents are trained together. During training, the agents exchange roles periodically, fostering cooperation and coevolution between them. Experiments evaluate CORY's performance by fine-tuning GPT-2 and Llama-2 under subjective and objective reward functions on the IMDB Review and GSM8K datasets, respectively. Results show that CORY outperforms PPO in terms of policy optimality, resistance to distribution collapse, and training robustness, thereby underscoring its potential as a superior methodology for refining LLMs in real-world applications.