 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboSVG: A Unified Framework for Interactive SVG Generation with Multi-modal Guidance
Oct 26, 2025Scalable Vector Graphics (SVGs) are fundamental to digital design and robot control, encoding not only visual structure but also motion paths in interactive drawings. In this work, we introduce RoboSVG, a unified multimodal framework for generating interactive SVGs guided by textual, visual, and numerical signals. Given an input query, the RoboSVG model first produces multimodal guidance, then synthesizes candidate SVGs through dedicated generation modules, and finally refines them under numerical guidance to yield high-quality outputs. To support this framework, we construct RoboDraw, a large-scale dataset of one million examples, each pairing an SVG generation condition (e.g., text, image, and partial SVG) with its corresponding ground-truth SVG code. RoboDraw dataset enables systematic study of four tasks, including basic generation (Text-to-SVG, Image-to-SVG) and interactive generation (PartialSVG-to-SVG, PartialImage-to-SVG). Extensive experiments demonstrate that RoboSVG achieves superior query compliance and visual fidelity across tasks, establishing a new state of the art in versatile SVG generation. The dataset and source code of this project will be publicly available soon.
GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
Sep 19, 2025Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.
Causal Mean Field Multi-Agent Reinforcement Learning
Feb 20, 2025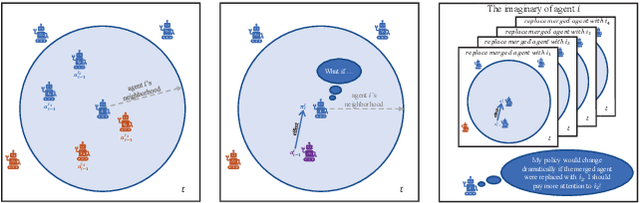
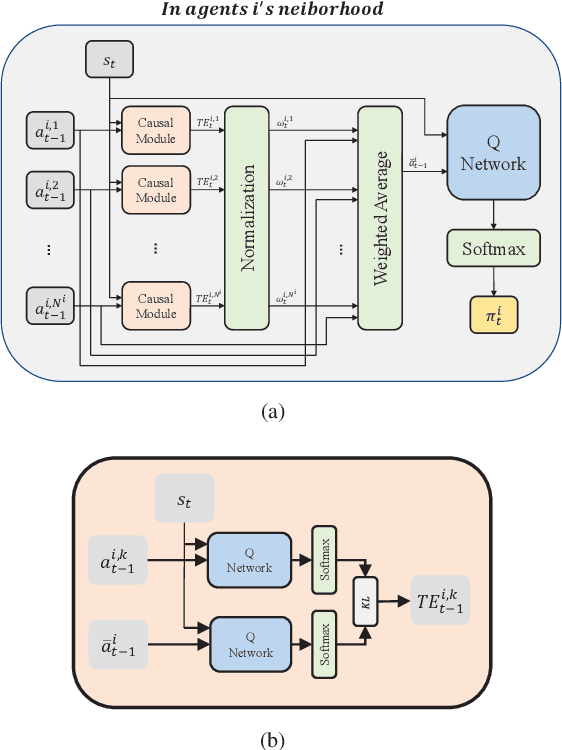
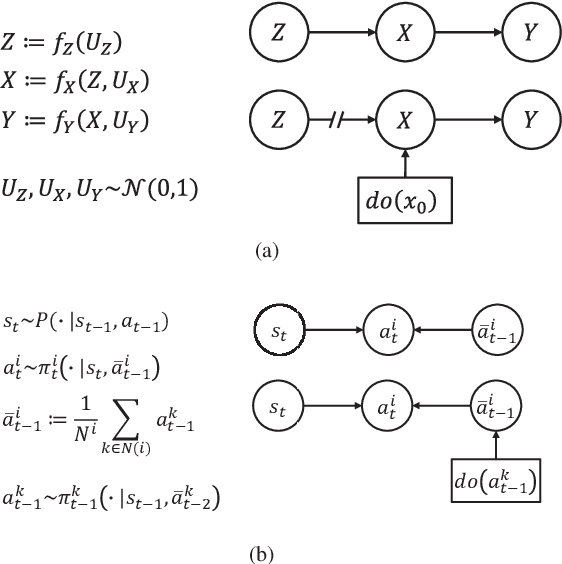
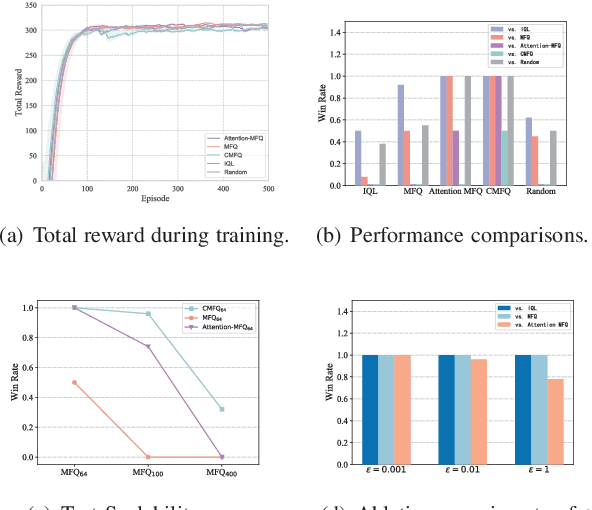
Scalability remains a challenge in multi-agent reinforcement learning and is currently under active research. A framework named mean-field reinforcement learning (MFRL) could alleviate the scalability problem by employing the Mean Field Theory to turn a many-agent problem into a two-agent problem. However, this framework lacks the ability to identify essential interactions under nonstationary environments. Causality contains relatively invariant mechanisms behind interactions, though environments are nonstationary. Therefore, we propose an algorithm called causal mean-field Q-learning (CMFQ) to address the scalability problem. CMFQ is ever more robust toward the change of the number of agents though inheriting the compressed representation of MFRL's action-state space. Firstly, we model the causality behind the decision-making process of MFRL into a structural causal model (SCM). Then the essential degree of each interaction is quantified via intervening on the SCM. Furthermore, we design the causality-aware compact representation for behavioral information of agents as the weighted sum of all behavioral information according to their causal effects. We test CMFQ in a mixed cooperative-competitive game and a cooperative game. The result shows that our method has excellent scalability performance in both training in environments containing a large number of agents and testing in environments containing much more agents.
AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production
Mar 12, 2024The Agent and AIGC (Artificial Intelligence Generated Content) technologies have recently made significant progress. We propose AesopAgent, an Agent-driven Evolutionary System on Story-to-Video Production. AesopAgent is a practical application of agent technology for multimodal content generation. The system integrates multiple generative capabilities within a unified framework, so that individual users can leverage these modules easily. This innovative system would convert user story proposals into scripts, images, and audio, and then integrate these multimodal contents into videos. Additionally, the animating units (e.g., Gen-2 and Sora) could make the videos more infectious. The AesopAgent system could orchestrate task workflow for video generation, ensuring that the generated video is both rich in content and coherent. This system mainly contains two layers, i.e., the Horizontal Layer and the Utility Layer. In the Horizontal Layer, we introduce a novel RAG-based evolutionary system that optimizes the whole video generation workflow and the steps within the workflow. It continuously evolves and iteratively optimizes workflow by accumulating expert experience and professional knowledge, including optimizing the LLM prompts and utilities usage. The Utility Layer provides multiple utilities, leading to consistent image generation that is visually coherent in terms of composition, characters, and style. Meanwhile, it provides audio and special effects, integrating them into expressive and logically arranged videos. Overall, our AesopAgent achieves state-of-the-art performance compared with many previous works in visual storytelling. Our AesopAgent is designed for convenient service for individual users, which is available on the following page: https://aesopai.github.io/.
Masked Non-Autoregressive Image Captioning
Jun 03, 2019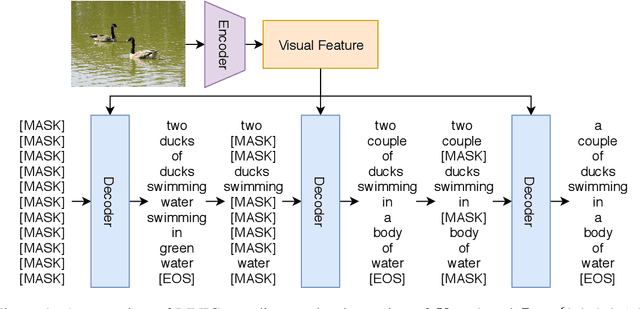
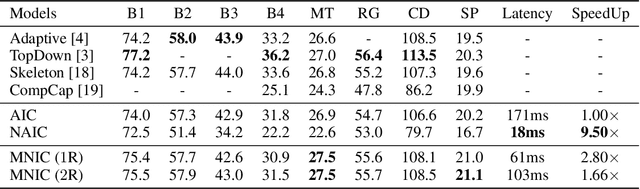
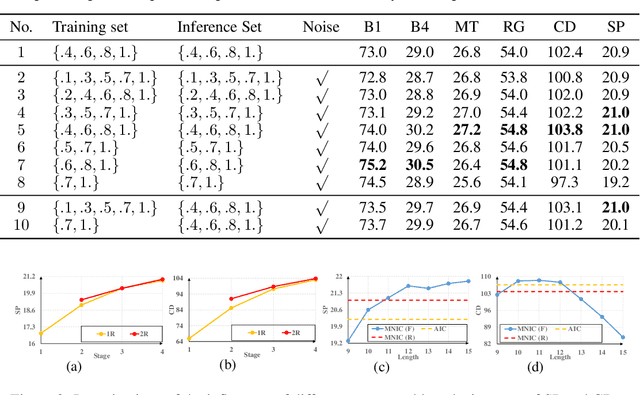
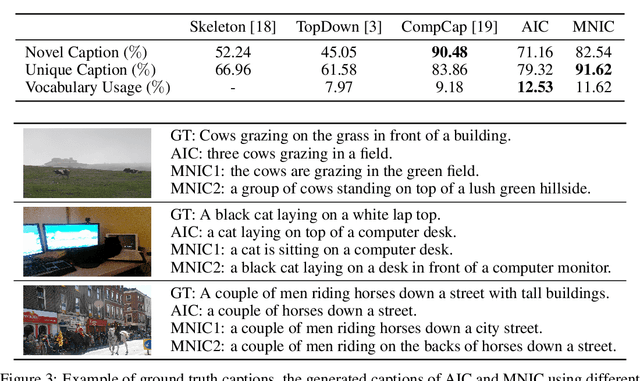
Existing captioning models often adopt the encoder-decoder architecture, where the decoder uses autoregressive decoding to generate captions, such that each token is generated sequentially given the preceding generated tokens. However, autoregressive decoding results in issues such as sequential error accumulation, slow generation, improper semantics and lack of diversity. Non-autoregressive decoding has been proposed to tackle slow generation for neural machine translation but suffers from multimodality problem due to the indirect modeling of the target distribution. In this paper, we propose masked non-autoregressive decoding to tackle the issues of both autoregressive decoding and non-autoregressive decoding. In masked non-autoregressive decoding, we mask several kinds of ratios of the input sequences during training, and generate captions parallelly in several stages from a totally masked sequence to a totally non-masked sequence in a compositional manner during inference. Experimentally our proposed model can preserve semantic content more effectively and can generate more diverse captions.
Self-critical n-step Training for Image Captioning
Apr 15, 2019



Existing methods for image captioning are usually trained by cross entropy loss, which leads to exposure bias and the inconsistency between the optimizing function and evaluation metrics. Recently it has been shown that these two issues can be addressed by incorporating techniques from reinforcement learning, where one of the popular techniques is the advantage actor-critic algorithm that calculates per-token advantage by estimating state value with a parametrized estimator at the cost of introducing estimation bias. In this paper, we estimate state value without using a parametrized value estimator. With the properties of image captioning, namely, the deterministic state transition function and the sparse reward, state value is equivalent to its preceding state-action value, and we reformulate advantage function by simply replacing the former with the latter. Moreover, the reformulated advantage is extended to n-step, which can generally increase the absolute value of the mean of reformulated advantage while lowering variance. Then two kinds of rollout are adopted to estimate state-action value, which we call self-critical n-step training. Empirically we find that our method can obtain better performance compared to the state-of-the-art methods that use the sequence level advantage and parametrized estimator respectively on the widely used MSCOCO benchmark.