 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-RHO: Critical-path-aware Heterogeneous Graph Network for Long-Horizon Flexible Job-Shop Scheduling
Apr 11, 2026Long-horizon Flexible Job-Shop Scheduling~(FJSP) presents a formidable combinatorial challenge due to complex, interdependent decisions spanning extended time horizons. While learning-based Rolling Horizon Optimization~(RHO) has emerged as a promising paradigm to accelerate solving by identifying and fixing invariant operations, its effectiveness is hindered by the structural complexity of FJSP. Existing methods often fail to capture intricate graph-structured dependencies and ignore the asymmetric costs of prediction errors, in which misclassifying critical-path operations is significantly more detrimental than misclassifying non-critical ones. Furthermore, dynamic shifts in predictive confidence during the rolling process make static pruning thresholds inadequate. To address these limitations, we propose Graph-RHO, a novel critical-path-aware graph-based RHO framework. First, we introduce a topology-aware heterogeneous graph network that encodes subproblems as operation-machine graphs with multi-relational edges, leveraging edge-feature-aware message passing to predict operation stability. Second, we incorporate a critical-path-aware mechanism that injects inductive biases during training to distinguish highly sensitive bottleneck operations from robust ones. Third, we devise an adaptive thresholding strategy that dynamically calibrates decision boundaries based on online uncertainty estimation to align model predictions with the solver's search space. Extensive experiments on standard benchmarks demonstrate that \mbox{Graph-RHO} establishes a new state of the art in solution quality and computational efficiency. Remarkably, it exhibits exceptional zero-shot generalization, reducing solve time by over 30\% on large-scale instances (2000 operations) while achieving superior solution quality. Our code is available \href{https://github.com/IntelliSensing/Graph-RHO}{here}.
RoboSVG: A Unified Framework for Interactive SVG Generation with Multi-modal Guidance
Oct 26, 2025

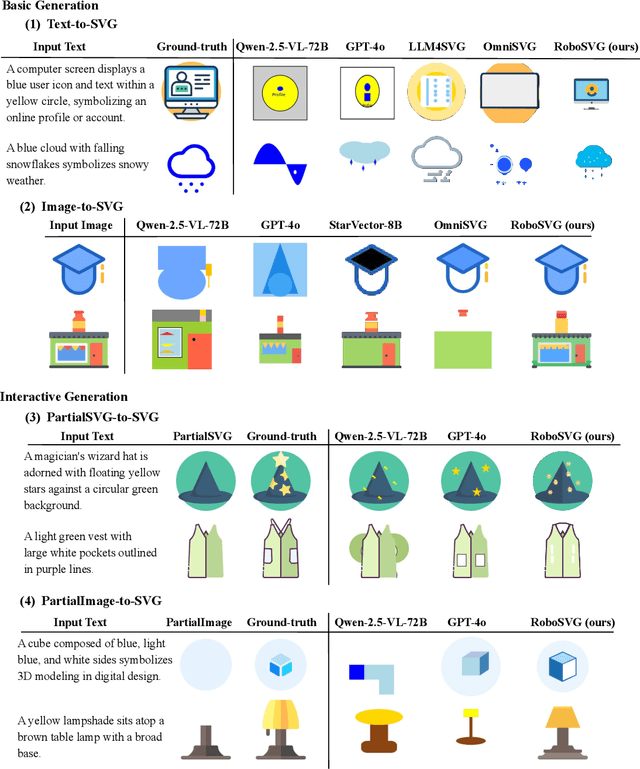

Scalable Vector Graphics (SVGs) are fundamental to digital design and robot control, encoding not only visual structure but also motion paths in interactive drawings. In this work, we introduce RoboSVG, a unified multimodal framework for generating interactive SVGs guided by textual, visual, and numerical signals. Given an input query, the RoboSVG model first produces multimodal guidance, then synthesizes candidate SVGs through dedicated generation modules, and finally refines them under numerical guidance to yield high-quality outputs. To support this framework, we construct RoboDraw, a large-scale dataset of one million examples, each pairing an SVG generation condition (e.g., text, image, and partial SVG) with its corresponding ground-truth SVG code. RoboDraw dataset enables systematic study of four tasks, including basic generation (Text-to-SVG, Image-to-SVG) and interactive generation (PartialSVG-to-SVG, PartialImage-to-SVG). Extensive experiments demonstrate that RoboSVG achieves superior query compliance and visual fidelity across tasks, establishing a new state of the art in versatile SVG generation. The dataset and source code of this project will be publicly available soon.
GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
Sep 19, 2025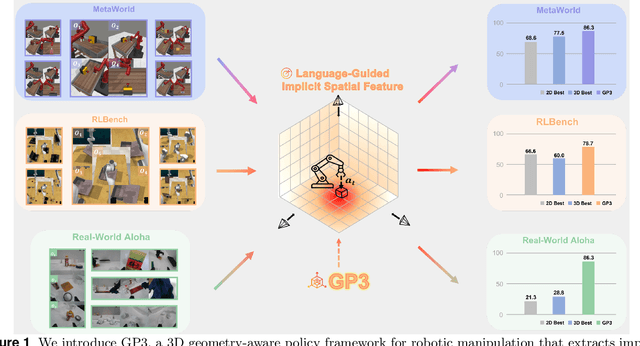



Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.
UniRS: Unifying Multi-temporal Remote Sensing Tasks through Vision Language Models
Dec 30, 2024



The domain gap between remote sensing imagery and natural images has recently received widespread attention and Vision-Language Models (VLMs) have demonstrated excellent generalization performance in remote sensing multimodal tasks. However, current research is still limited in exploring how remote sensing VLMs handle different types of visual inputs. To bridge this gap, we introduce \textbf{UniRS}, the first vision-language model \textbf{uni}fying multi-temporal \textbf{r}emote \textbf{s}ensing tasks across various types of visual input. UniRS supports single images, dual-time image pairs, and videos as input, enabling comprehensive remote sensing temporal analysis within a unified framework. We adopt a unified visual representation approach, enabling the model to accept various visual inputs. For dual-time image pair tasks, we customize a change extraction module to further enhance the extraction of spatiotemporal features. Additionally, we design a prompt augmentation mechanism tailored to the model's reasoning process, utilizing the prior knowledge of the general-purpose VLM to provide clues for UniRS. To promote multi-task knowledge sharing, the model is jointly fine-tuned on a mixed dataset. Experimental results show that UniRS achieves state-of-the-art performance across diverse tasks, including visual question answering, change captioning, and video scene classification, highlighting its versatility and effectiveness in unifying these multi-temporal remote sensing tasks. Our code and dataset will be released soon.
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agents
Jun 11, 2024


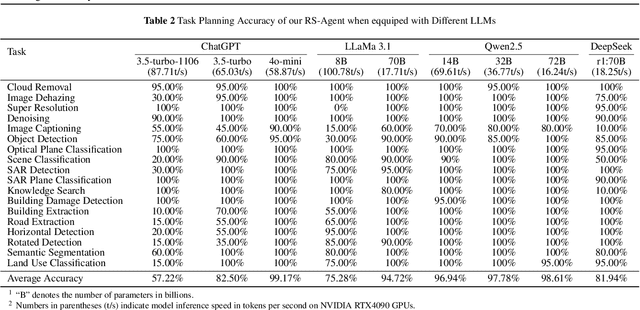
An increasing number of models have achieved great performance in remote sensing tasks with the recent development of Large Language Models (LLMs) and Visual Language Models (VLMs). However, these models are constrained to basic vision and language instruction-tuning tasks, facing challenges in complex remote sensing applications. Additionally, these models lack specialized expertise in professional domains. To address these limitations, we propose a LLM-driven remote sensing intelligent agent named RS-Agent. Firstly, RS-Agent is powered by a large language model (LLM) that acts as its "Central Controller," enabling it to understand and respond to various problems intelligently. Secondly, our RS-Agent integrates many high-performance remote sensing image processing tools, facilitating multi-tool and multi-turn conversations. Thirdly, our RS-Agent can answer professional questions by leveraging robust knowledge documents. We conducted experiments using several datasets, e.g., RSSDIVCS, RSVQA, and DOTAv1. The experimental results demonstrate that our RS-Agent delivers outstanding performance in many tasks, i.e., scene classification, visual question answering, and object counting tasks.
UAV-VisLoc: A Large-scale Dataset for UAV Visual Localization
May 20, 2024



The application of unmanned aerial vehicles (UAV) has been widely extended recently. It is crucial to ensure accurate latitude and longitude coordinates for UAVs, especially when the global navigation satellite systems (GNSS) are disrupted and unreliable. Existing visual localization methods achieve autonomous visual localization without error accumulation by matching the ground-down view image of UAV with the ortho satellite maps. However, collecting UAV ground-down view images across diverse locations is costly, leading to a scarcity of large-scale datasets for real-world scenarios. Existing datasets for UAV visual localization are often limited to small geographic areas or are focused only on urban regions with distinct textures. To address this, we define the UAV visual localization task by determining the UAV's real position coordinates on a large-scale satellite map based on the captured ground-down view. In this paper, we present a large-scale dataset, UAV-VisLoc, to facilitate the UAV visual localization task. This dataset comprises images from diverse drones across 11 locations in China, capturing a range of topographical features. The dataset features images from fixed-wing drones and multi-terrain drones, captured at different altitudes and orientations. Our dataset includes 6,742 drone images and 11 satellite maps, with metadata such as latitude, longitude, altitude, and capture date. Our dataset is tailored to support both the training and testing of models by providing a diverse and extensive data.
AesopAgent: Agent-driven Evolutionary System on Story-to-Video Production
Mar 12, 2024The Agent and AIGC (Artificial Intelligence Generated Content) technologies have recently made significant progress. We propose AesopAgent, an Agent-driven Evolutionary System on Story-to-Video Production. AesopAgent is a practical application of agent technology for multimodal content generation. The system integrates multiple generative capabilities within a unified framework, so that individual users can leverage these modules easily. This innovative system would convert user story proposals into scripts, images, and audio, and then integrate these multimodal contents into videos. Additionally, the animating units (e.g., Gen-2 and Sora) could make the videos more infectious. The AesopAgent system could orchestrate task workflow for video generation, ensuring that the generated video is both rich in content and coherent. This system mainly contains two layers, i.e., the Horizontal Layer and the Utility Layer. In the Horizontal Layer, we introduce a novel RAG-based evolutionary system that optimizes the whole video generation workflow and the steps within the workflow. It continuously evolves and iteratively optimizes workflow by accumulating expert experience and professional knowledge, including optimizing the LLM prompts and utilities usage. The Utility Layer provides multiple utilities, leading to consistent image generation that is visually coherent in terms of composition, characters, and style. Meanwhile, it provides audio and special effects, integrating them into expressive and logically arranged videos. Overall, our AesopAgent achieves state-of-the-art performance compared with many previous works in visual storytelling. Our AesopAgent is designed for convenient service for individual users, which is available on the following page: https://aesopai.github.io/.
Deep Semantic-Visual Alignment for Zero-Shot Remote Sensing Image Scene Classification
Feb 03, 2024Deep neural networks have achieved promising progress in remote sensing (RS) image classification, for which the training process requires abundant samples for each class. However, it is time-consuming and unrealistic to annotate labels for each RS category, given the fact that the RS target database is increasing dynamically. Zero-shot learning (ZSL) allows for identifying novel classes that are not seen during training, which provides a promising solution for the aforementioned problem. However, previous ZSL models mainly depend on manually-labeled attributes or word embeddings extracted from language models to transfer knowledge from seen classes to novel classes. Besides, pioneer ZSL models use convolutional neural networks pre-trained on ImageNet, which focus on the main objects appearing in each image, neglecting the background context that also matters in RS scene classification. To address the above problems, we propose to collect visually detectable attributes automatically. We predict attributes for each class by depicting the semantic-visual similarity between attributes and images. In this way, the attribute annotation process is accomplished by machine instead of human as in other methods. Moreover, we propose a Deep Semantic-Visual Alignment (DSVA) that take advantage of the self-attention mechanism in the transformer to associate local image regions together, integrating the background context information for prediction. The DSVA model further utilizes the attribute attention maps to focus on the informative image regions that are essential for knowledge transfer in ZSL, and maps the visual images into attribute space to perform ZSL classification. With extensive experiments, we show that our model outperforms other state-of-the-art models by a large margin on a challenging large-scale RS scene classification benchmark.
* Published in ISPRS P&RS. The code is available at https://github.com/wenjiaXu/RS_Scene_ZSL
Jointly Optimized Global-Local Visual Localization of UAVs
Oct 12, 2023



Navigation and localization of UAVs present a challenge when global navigation satellite systems (GNSS) are disrupted and unreliable. Traditional techniques, such as simultaneous localization and mapping (SLAM) and visual odometry (VO), exhibit certain limitations in furnishing absolute coordinates and mitigating error accumulation. Existing visual localization methods achieve autonomous visual localization without error accumulation by matching with ortho satellite images. However, doing so cannot guarantee real-time performance due to the complex matching process. To address these challenges, we propose a novel Global-Local Visual Localization (GLVL) network. Our GLVL network is a two-stage visual localization approach, combining a large-scale retrieval module that finds similar regions with the UAV flight scene, and a fine-grained matching module that localizes the precise UAV coordinate, enabling real-time and precise localization. The training process is jointly optimized in an end-to-end manner to further enhance the model capability. Experiments on six UAV flight scenes encompassing both texture-rich and texture-sparse regions demonstrate the ability of our model to achieve the real-time precise localization requirements of UAVs. Particularly, our method achieves a localization error of only 2.39 meters in 0.48 seconds in a village scene with sparse texture features.
ModelScope Text-to-Video Technical Report
Aug 12, 2023This paper introduces ModelScopeT2V, a text-to-video synthesis model that evolves from a text-to-image synthesis model (i.e., Stable Diffusion). ModelScopeT2V incorporates spatio-temporal blocks to ensure consistent frame generation and smooth movement transitions. The model could adapt to varying frame numbers during training and inference, rendering it suitable for both image-text and video-text datasets. ModelScopeT2V brings together three components (i.e., VQGAN, a text encoder, and a denoising UNet), totally comprising 1.7 billion parameters, in which 0.5 billion parameters are dedicated to temporal capabilities. The model demonstrates superior performance over state-of-the-art methods across three evaluation metrics. The code and an online demo are available at \url{https://modelscope.cn/models/damo/text-to-video-synthesis/summary}.