 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
Explainable Global Wildfire Prediction Models using Graph Neural Networks
Feb 11, 2024



Wildfire prediction has become increasingly crucial due to the escalating impacts of climate change. Traditional CNN-based wildfire prediction models struggle with handling missing oceanic data and addressing the long-range dependencies across distant regions in meteorological data. In this paper, we introduce an innovative Graph Neural Network (GNN)-based model for global wildfire prediction. We propose a hybrid model that combines the spatial prowess of Graph Convolutional Networks (GCNs) with the temporal depth of Long Short-Term Memory (LSTM) networks. Our approach uniquely transforms global climate and wildfire data into a graph representation, addressing challenges such as null oceanic data locations and long-range dependencies inherent in traditional models. Benchmarking against established architectures using an unseen ensemble of JULES-INFERNO simulations, our model demonstrates superior predictive accuracy. Furthermore, we emphasise the model's explainability, unveiling potential wildfire correlation clusters through community detection and elucidating feature importance via Integrated Gradient analysis. Our findings not only advance the methodological domain of wildfire prediction but also underscore the importance of model transparency, offering valuable insights for stakeholders in wildfire management.
ModelScope Text-to-Video Technical Report
Aug 12, 2023This paper introduces ModelScopeT2V, a text-to-video synthesis model that evolves from a text-to-image synthesis model (i.e., Stable Diffusion). ModelScopeT2V incorporates spatio-temporal blocks to ensure consistent frame generation and smooth movement transitions. The model could adapt to varying frame numbers during training and inference, rendering it suitable for both image-text and video-text datasets. ModelScopeT2V brings together three components (i.e., VQGAN, a text encoder, and a denoising UNet), totally comprising 1.7 billion parameters, in which 0.5 billion parameters are dedicated to temporal capabilities. The model demonstrates superior performance over state-of-the-art methods across three evaluation metrics. The code and an online demo are available at \url{https://modelscope.cn/models/damo/text-to-video-synthesis/summary}.
VideoComposer: Compositional Video Synthesis with Motion Controllability
Jun 06, 2023The pursuit of controllability as a higher standard of visual content creation has yielded remarkable progress in customizable image synthesis. However, achieving controllable video synthesis remains challenging due to the large variation of temporal dynamics and the requirement of cross-frame temporal consistency. Based on the paradigm of compositional generation, this work presents VideoComposer that allows users to flexibly compose a video with textual conditions, spatial conditions, and more importantly temporal conditions. Specifically, considering the characteristic of video data, we introduce the motion vector from compressed videos as an explicit control signal to provide guidance regarding temporal dynamics. In addition, we develop a Spatio-Temporal Condition encoder (STC-encoder) that serves as a unified interface to effectively incorporate the spatial and temporal relations of sequential inputs, with which the model could make better use of temporal conditions and hence achieve higher inter-frame consistency. Extensive experimental results suggest that VideoComposer is able to control the spatial and temporal patterns simultaneously within a synthesized video in various forms, such as text description, sketch sequence, reference video, or even simply hand-crafted motions. The code and models will be publicly available at https://videocomposer.github.io.
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
Mar 22, 2023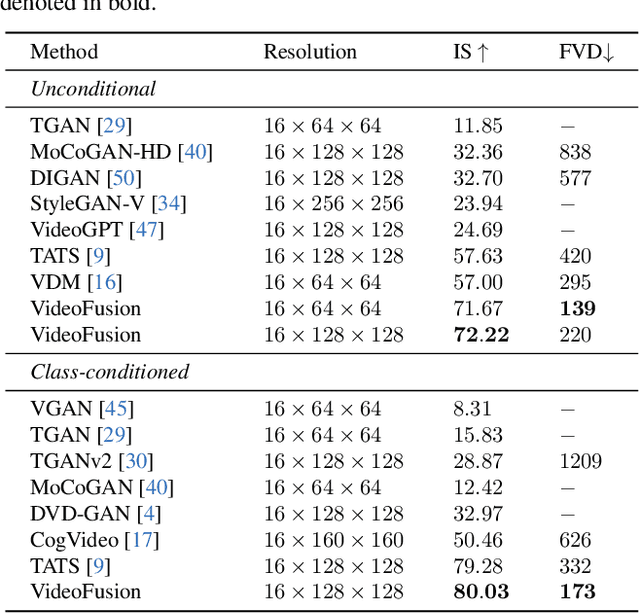


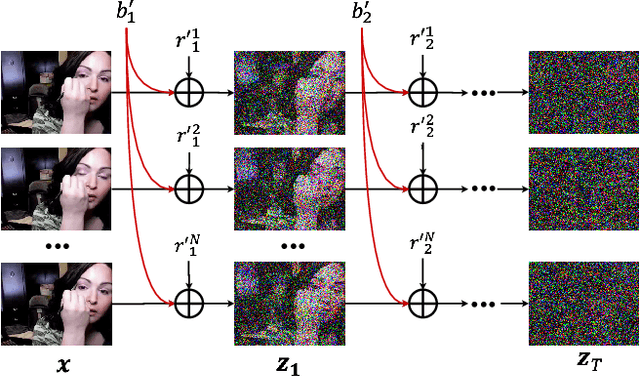
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
Multi-Task Recommendations with Reinforcement Learning
Feb 07, 2023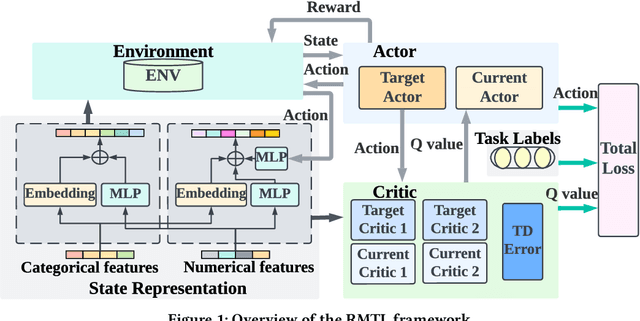
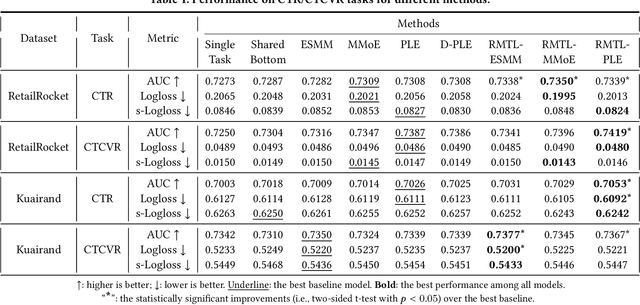
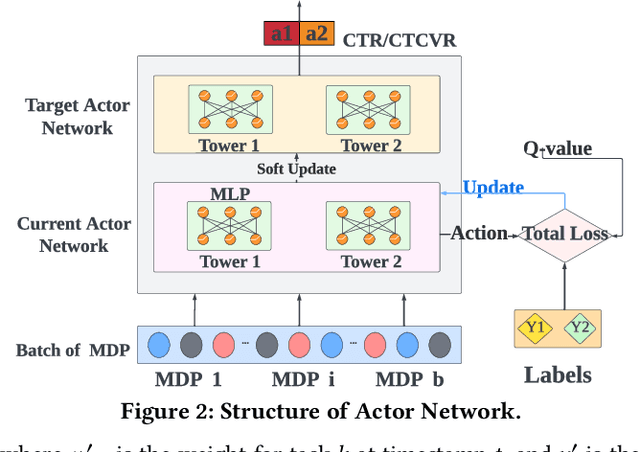
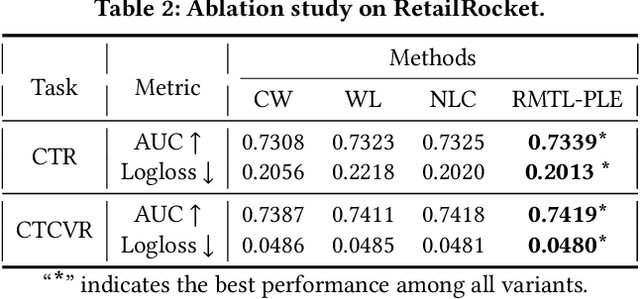
In recent years, Multi-task Learning (MTL) has yielded immense success in Recommender System (RS) applications. However, current MTL-based recommendation models tend to disregard the session-wise patterns of user-item interactions because they are predominantly constructed based on item-wise datasets. Moreover, balancing multiple objectives has always been a challenge in this field, which is typically avoided via linear estimations in existing works. To address these issues, in this paper, we propose a Reinforcement Learning (RL) enhanced MTL framework, namely RMTL, to combine the losses of different recommendation tasks using dynamic weights. To be specific, the RMTL structure can address the two aforementioned issues by (i) constructing an MTL environment from session-wise interactions and (ii) training multi-task actor-critic network structure, which is compatible with most existing MTL-based recommendation models, and (iii) optimizing and fine-tuning the MTL loss function using the weights generated by critic networks. Experiments on two real-world public datasets demonstrate the effectiveness of RMTL with a higher AUC against state-of-the-art MTL-based recommendation models. Additionally, we evaluate and validate RMTL's compatibility and transferability across various MTL models.