 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Pruning of Large Vision Language Models: A Comprehensive Study on Pruning Dynamics, Recovery, and Data Efficiency
Apr 27, 2026While Large Vision Language Models (LVLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose deployment challenges on resource-constrained edge devices. Current parameter reduction techniques primarily involve training LVLMs from small language models, but these methods offer limited flexibility and remain computationally intensive. We study a complementary route: compressing existing LVLMs by applying structured pruning to the language model backbone, followed by lightweight recovery training. Specifically, we investigate two structural pruning paradigms: layerwise and widthwise pruning, and pair them with supervised finetuning and knowledge distillation on logits and hidden states. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios, where computational resources are limited or there is insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels. Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved using just 5% of the original data, while retaining over 95% of the original performance. Through empirical study on three representative LVLM families ranging from 3B to 7B parameters, this study offers actionable insights for practitioners to compress LVLMs without extensive computation resources or sufficient data. The code base is available at https://github.com/YiranHuangIrene/VLMCompression.git.
Graph-RHO: Critical-path-aware Heterogeneous Graph Network for Long-Horizon Flexible Job-Shop Scheduling
Apr 11, 2026Long-horizon Flexible Job-Shop Scheduling~(FJSP) presents a formidable combinatorial challenge due to complex, interdependent decisions spanning extended time horizons. While learning-based Rolling Horizon Optimization~(RHO) has emerged as a promising paradigm to accelerate solving by identifying and fixing invariant operations, its effectiveness is hindered by the structural complexity of FJSP. Existing methods often fail to capture intricate graph-structured dependencies and ignore the asymmetric costs of prediction errors, in which misclassifying critical-path operations is significantly more detrimental than misclassifying non-critical ones. Furthermore, dynamic shifts in predictive confidence during the rolling process make static pruning thresholds inadequate. To address these limitations, we propose Graph-RHO, a novel critical-path-aware graph-based RHO framework. First, we introduce a topology-aware heterogeneous graph network that encodes subproblems as operation-machine graphs with multi-relational edges, leveraging edge-feature-aware message passing to predict operation stability. Second, we incorporate a critical-path-aware mechanism that injects inductive biases during training to distinguish highly sensitive bottleneck operations from robust ones. Third, we devise an adaptive thresholding strategy that dynamically calibrates decision boundaries based on online uncertainty estimation to align model predictions with the solver's search space. Extensive experiments on standard benchmarks demonstrate that \mbox{Graph-RHO} establishes a new state of the art in solution quality and computational efficiency. Remarkably, it exhibits exceptional zero-shot generalization, reducing solve time by over 30\% on large-scale instances (2000 operations) while achieving superior solution quality. Our code is available \href{https://github.com/IntelliSensing/Graph-RHO}{here}.
Zero Shot Deformation Reconstruction for Soft Robots Using a Flexible Sensor Array and Cage Based 3D Gaussian Modeling
Mar 20, 2026We present a zero-shot deformation reconstruction framework for soft robots that operates without any visual supervision at inference time. In this work, zero-shot deformation reconstruction is defined as the ability to infer object-wide deformations on previously unseen soft robots without collecting object-specific deformation data or performing any retraining during deployment. Our method assumes access to a static geometric proxy of the undeformed object, which can be obtained from a STL model. During operation, the system relies exclusively on tactile sensing, enabling camera-free deformation inference. The proposed framework integrates a flexible piezoresistive sensor array with a geometry-aware, cage-based 3D Gaussian deformation model. Local tactile measurements are mapped to low-dimensional cage control signals and propagated to dense Gaussian primitives to generate globally consistent shape deformations. A graph attention network regresses cage displacements from tactile input, enforcing spatial smoothness and structural continuity via boundary-aware propagation. Given only a nominal geometric proxy and real-time tactile signals, the system performs zero-shot deformation reconstruction of unseen soft robots in bending and twisting motions, while rendering photorealistic RGB in real time. It achieves 0.67 IoU, 0.65 SSIM, and 3.48 mm Chamfer distance, demonstrating strong zero-shot generalization through explicit coupling of tactile sensing and structured geometric deformation.
Dissecting Multimodal In-Context Learning: Modality Asymmetries and Circuit Dynamics in modern Transformers
Jan 28, 2026Transformer-based multimodal large language models often exhibit in-context learning (ICL) abilities. Motivated by this phenomenon, we ask: how do transformers learn to associate information across modalities from in-context examples? We investigate this question through controlled experiments on small transformers trained on synthetic classification tasks, enabling precise manipulation of data statistics and model architecture. We begin by revisiting core principles of unimodal ICL in modern transformers. While several prior findings replicate, we find that Rotary Position Embeddings (RoPE) increases the data complexity threshold for ICL. Extending to the multimodal setting reveals a fundamental learning asymmetry: when pretrained on high-diversity data from a primary modality, surprisingly low data complexity in the secondary modality suffices for multimodal ICL to emerge. Mechanistic analysis shows that both settings rely on an induction-style mechanism that copies labels from matching in-context exemplars; multimodal training refines and extends these circuits across modalities. Our findings provide a mechanistic foundation for understanding multimodal ICL in modern transformers and introduce a controlled testbed for future investigation.
Thinking on Maps: How Foundation Model Agents Explore, Remember, and Reason Map Environments
Dec 30, 2025Map environments provide a fundamental medium for representing spatial structure. Understanding how foundation model (FM) agents understand and act in such environments is therefore critical for enabling reliable map-based reasoning and applications. However, most existing evaluations of spatial ability in FMs rely on static map inputs or text-based queries, overlooking the interactive and experience-driven nature of spatial understanding.In this paper, we propose an interactive evaluation framework to analyze how FM agents explore, remember, and reason in symbolic map environments. Agents incrementally explore partially observable grid-based maps consisting of roads, intersections, and points of interest (POIs), receiving only local observations at each step. Spatial understanding is then evaluated using six kinds of spatial tasks. By systematically varying exploration strategies, memory representations, and reasoning schemes across multiple foundation models, we reveal distinct functional roles of these components. Exploration primarily affects experience acquisition but has a limited impact on final reasoning accuracy. In contrast, memory representation plays a central role in consolidating spatial experience, with structured memories particularly sequential and graph-based representations, substantially improving performance on structure-intensive tasks such as path planning. Reasoning schemes further shape how stored spatial knowledge is used, with advanced prompts supporting more effective multi-step inference. We further observe that spatial reasoning performance saturates across model versions and scales beyond a certain capability threshold, indicating that improvements in map-based spatial understanding require mechanisms tailored to spatial representation and reasoning rather than scaling alone.
Investigating Structural Pruning and Recovery Techniques for Compressing Multimodal Large Language Models: An Empirical Study
Jul 28, 2025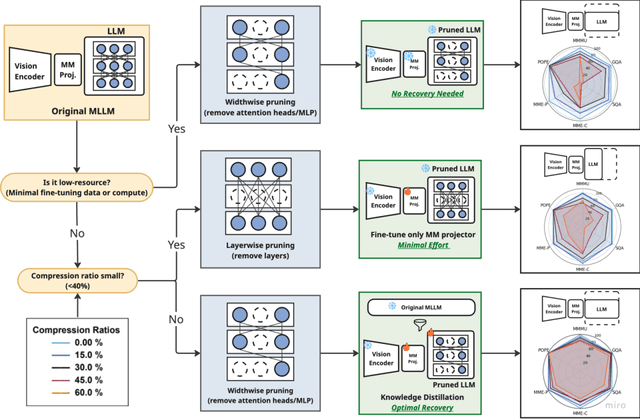
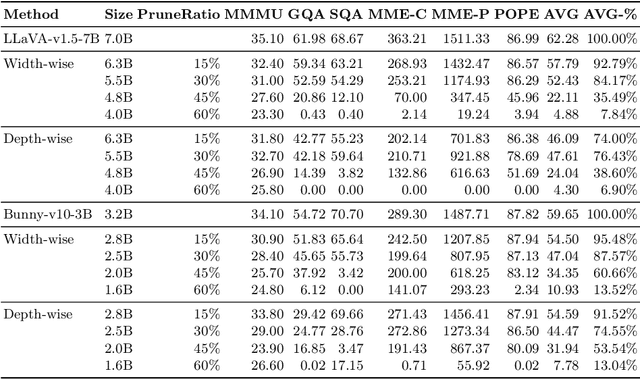
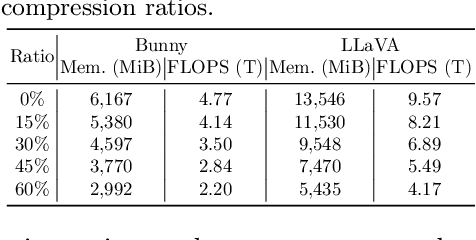
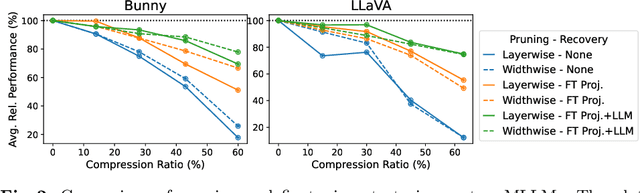
While Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities, their substantial computational and memory requirements pose significant barriers to practical deployment. Current parameter reduction techniques primarily involve training MLLMs from Small Language Models (SLMs), but these methods offer limited flexibility and remain computationally intensive. To address this gap, we propose to directly compress existing MLLMs through structural pruning combined with efficient recovery training. Specifically, we investigate two structural pruning paradigms--layerwise and widthwise pruning--applied to the language model backbone of MLLMs, alongside supervised finetuning and knowledge distillation. Additionally, we assess the feasibility of conducting recovery training with only a small fraction of the available data. Our results show that widthwise pruning generally maintains better performance in low-resource scenarios with limited computational resources or insufficient finetuning data. As for the recovery training, finetuning only the multimodal projector is sufficient at small compression levels (< 20%). Furthermore, a combination of supervised finetuning and hidden-state distillation yields optimal recovery across various pruning levels. Notably, effective recovery can be achieved with as little as 5% of the original training data, while retaining over 95% of the original performance. Through empirical study on two representative MLLMs, i.e., LLaVA-v1.5-7B and Bunny-v1.0-3B, this study offers actionable insights for practitioners aiming to compress MLLMs effectively without extensive computation resources or sufficient data.
TS-SatMVSNet: Slope Aware Height Estimation for Large-Scale Earth Terrain Multi-view Stereo
Jan 02, 2025



3D terrain reconstruction with remote sensing imagery achieves cost-effective and large-scale earth observation and is crucial for safeguarding natural disasters, monitoring ecological changes, and preserving the environment.Recently, learning-based multi-view stereo~(MVS) methods have shown promise in this task. However, these methods simply modify the general learning-based MVS framework for height estimation, which overlooks the terrain characteristics and results in insufficient accuracy. Considering that the Earth's surface generally undulates with no drastic changes and can be measured by slope, integrating slope considerations into MVS frameworks could enhance the accuracy of terrain reconstructions. To this end, we propose an end-to-end slope-aware height estimation network named TS-SatMVSNet for large-scale remote sensing terrain reconstruction.To effectively obtain the slope representation, drawing from mathematical gradient concepts, we innovatively proposed a height-based slope calculation strategy to first calculate a slope map from a height map to measure the terrain undulation. To fully integrate slope information into the MVS pipeline, we separately design two slope-guided modules to enhance reconstruction outcomes at both micro and macro levels. Specifically, at the micro level, we designed a slope-guided interval partition module for refined height estimation using slope values. At the macro level, a height correction module is proposed, using a learnable Gaussian smoothing operator to amend the inaccurate height values. Additionally, to enhance the efficacy of height estimation, we proposed a slope direction loss for implicitly optimizing height estimation results. Extensive experiments on the WHU-TLC dataset and MVS3D dataset show that our proposed method achieves state-of-the-art performance and demonstrates competitive generalization ability.
UniRS: Unifying Multi-temporal Remote Sensing Tasks through Vision Language Models
Dec 30, 2024



The domain gap between remote sensing imagery and natural images has recently received widespread attention and Vision-Language Models (VLMs) have demonstrated excellent generalization performance in remote sensing multimodal tasks. However, current research is still limited in exploring how remote sensing VLMs handle different types of visual inputs. To bridge this gap, we introduce \textbf{UniRS}, the first vision-language model \textbf{uni}fying multi-temporal \textbf{r}emote \textbf{s}ensing tasks across various types of visual input. UniRS supports single images, dual-time image pairs, and videos as input, enabling comprehensive remote sensing temporal analysis within a unified framework. We adopt a unified visual representation approach, enabling the model to accept various visual inputs. For dual-time image pair tasks, we customize a change extraction module to further enhance the extraction of spatiotemporal features. Additionally, we design a prompt augmentation mechanism tailored to the model's reasoning process, utilizing the prior knowledge of the general-purpose VLM to provide clues for UniRS. To promote multi-task knowledge sharing, the model is jointly fine-tuned on a mixed dataset. Experimental results show that UniRS achieves state-of-the-art performance across diverse tasks, including visual question answering, change captioning, and video scene classification, highlighting its versatility and effectiveness in unifying these multi-temporal remote sensing tasks. Our code and dataset will be released soon.
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agents
Jun 11, 2024


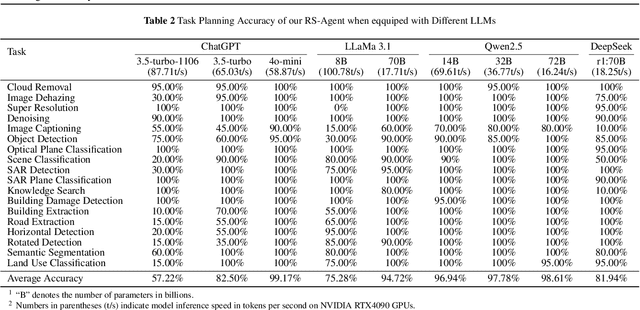
An increasing number of models have achieved great performance in remote sensing tasks with the recent development of Large Language Models (LLMs) and Visual Language Models (VLMs). However, these models are constrained to basic vision and language instruction-tuning tasks, facing challenges in complex remote sensing applications. Additionally, these models lack specialized expertise in professional domains. To address these limitations, we propose a LLM-driven remote sensing intelligent agent named RS-Agent. Firstly, RS-Agent is powered by a large language model (LLM) that acts as its "Central Controller," enabling it to understand and respond to various problems intelligently. Secondly, our RS-Agent integrates many high-performance remote sensing image processing tools, facilitating multi-tool and multi-turn conversations. Thirdly, our RS-Agent can answer professional questions by leveraging robust knowledge documents. We conducted experiments using several datasets, e.g., RSSDIVCS, RSVQA, and DOTAv1. The experimental results demonstrate that our RS-Agent delivers outstanding performance in many tasks, i.e., scene classification, visual question answering, and object counting tasks.
UAV-VisLoc: A Large-scale Dataset for UAV Visual Localization
May 20, 2024



The application of unmanned aerial vehicles (UAV) has been widely extended recently. It is crucial to ensure accurate latitude and longitude coordinates for UAVs, especially when the global navigation satellite systems (GNSS) are disrupted and unreliable. Existing visual localization methods achieve autonomous visual localization without error accumulation by matching the ground-down view image of UAV with the ortho satellite maps. However, collecting UAV ground-down view images across diverse locations is costly, leading to a scarcity of large-scale datasets for real-world scenarios. Existing datasets for UAV visual localization are often limited to small geographic areas or are focused only on urban regions with distinct textures. To address this, we define the UAV visual localization task by determining the UAV's real position coordinates on a large-scale satellite map based on the captured ground-down view. In this paper, we present a large-scale dataset, UAV-VisLoc, to facilitate the UAV visual localization task. This dataset comprises images from diverse drones across 11 locations in China, capturing a range of topographical features. The dataset features images from fixed-wing drones and multi-terrain drones, captured at different altitudes and orientations. Our dataset includes 6,742 drone images and 11 satellite maps, with metadata such as latitude, longitude, altitude, and capture date. Our dataset is tailored to support both the training and testing of models by providing a diverse and extensive data.