 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of the Density Power Spectrum from Quasar Spectra using Machine Learning
Jul 19, 2021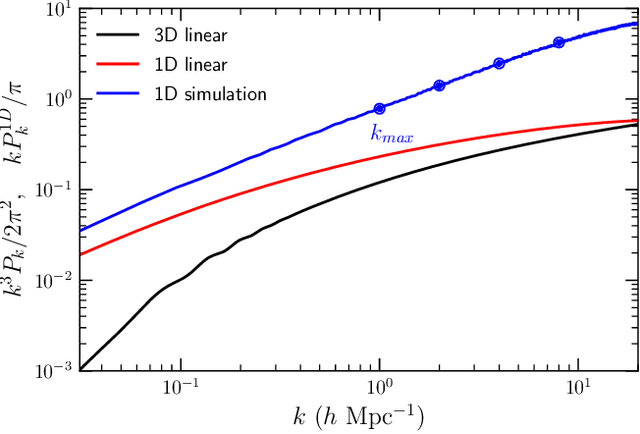

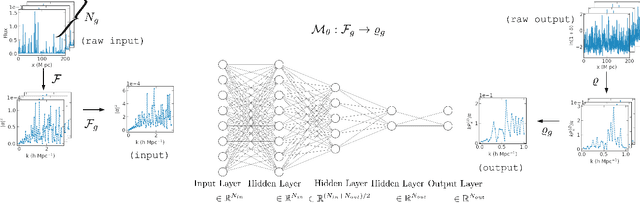
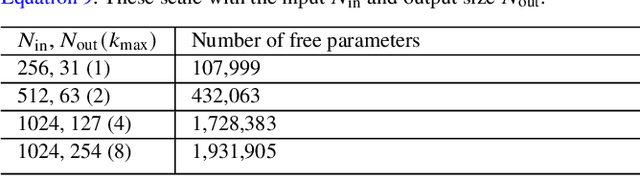
We describe a novel end-to-end approach using Machine Learning to reconstruct the power spectrum of cosmological density perturbations at high redshift from observed quasar spectra. State-of-the-art cosmological simulations of structure formation are used to generate a large synthetic dataset of line-of-sight absorption spectra paired with 1-dimensional fluid quantities along the same line-of-sight, such as the total density of matter and the density of neutral atomic hydrogen. With this dataset, we build a series of data-driven models to predict the power spectrum of total matter density. We are able to produce models which yield reconstruction to accuracy of about 1% for wavelengths $k \leq 2 h Mpc^{-1}$, while the error increases at larger $k$. We show the size of data sample required to reach a particular error rate, giving a sense of how much data is necessary to reach a desired accuracy. This work provides a foundation for developing methods to analyse very large upcoming datasets with the next-generation observational facilities.
Masked Non-Autoregressive Image Captioning
Jun 03, 2019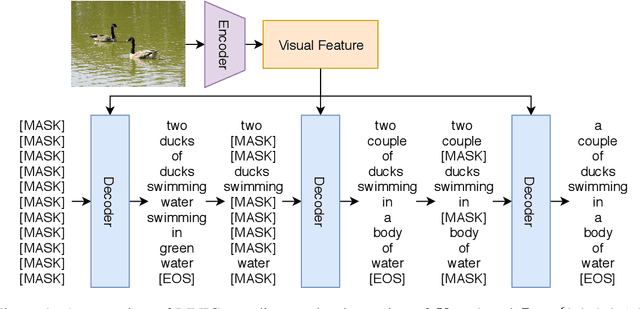
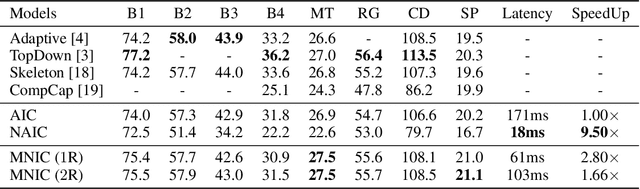
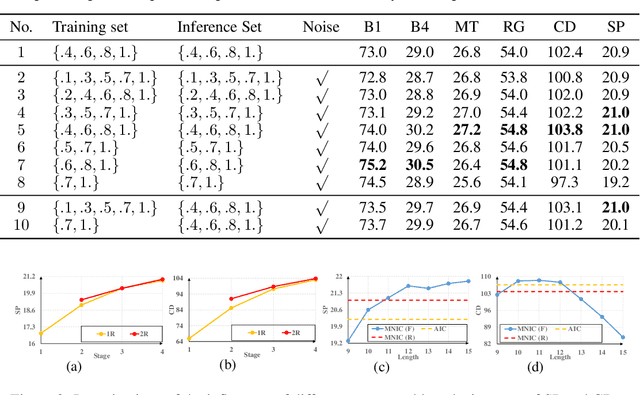
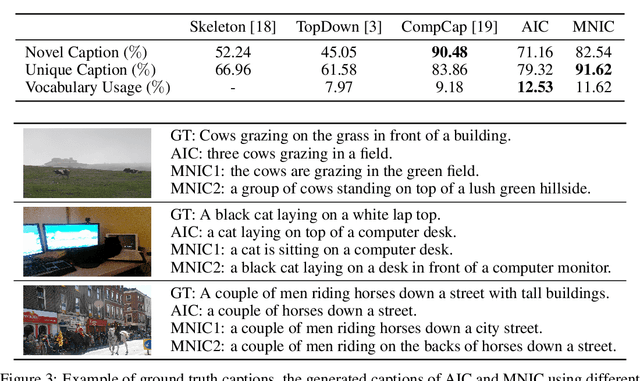
Existing captioning models often adopt the encoder-decoder architecture, where the decoder uses autoregressive decoding to generate captions, such that each token is generated sequentially given the preceding generated tokens. However, autoregressive decoding results in issues such as sequential error accumulation, slow generation, improper semantics and lack of diversity. Non-autoregressive decoding has been proposed to tackle slow generation for neural machine translation but suffers from multimodality problem due to the indirect modeling of the target distribution. In this paper, we propose masked non-autoregressive decoding to tackle the issues of both autoregressive decoding and non-autoregressive decoding. In masked non-autoregressive decoding, we mask several kinds of ratios of the input sequences during training, and generate captions parallelly in several stages from a totally masked sequence to a totally non-masked sequence in a compositional manner during inference. Experimentally our proposed model can preserve semantic content more effectively and can generate more diverse captions.