 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Soft Actor-Critic with LLM-Based Action-Level Guidance for Continuous Control
Mar 18, 2026We present GuidedSAC, a novel reinforcement learning (RL) algorithm that facilitates efficient exploration in vast state-action spaces. GuidedSAC leverages large language models (LLMs) as intelligent supervisors that provide action-level guidance for the Soft Actor-Critic (SAC) algorithm. The LLM-based supervisor analyzes the most recent trajectory using state information and visual replays, offering action-level interventions that enable targeted exploration. Furthermore, we provide a theoretical analysis of GuidedSAC, proving that it preserves the convergence guarantees of SAC while improving convergence speed. Through experiments in both discrete and continuous control environments, including toy text tasks and complex MuJoCo benchmarks, we demonstrate that GuidedSAC consistently outperforms standard SAC and state-of-the-art exploration-enhanced variants (e.g., RND, ICM, and E3B) in terms of sample efficiency and final performance.
Enhancing Reinforcement Learning Fine-Tuning with an Online Refiner
Mar 18, 2026Constraints are essential for stabilizing reinforcement learning fine-tuning (RFT) and preventing degenerate outputs, yet they inherently conflict with the optimization objective because stronger constraints limit the ability of a fine-tuned model to discover better solutions. We propose \textit{dynamic constraints} that resolve this tension by adapting to the evolving capabilities of the fine-tuned model based on the insight that constraints should only intervene when degenerate outputs occur. We implement this by using a reference model as an \textit{online refiner} that takes the response from the fine-tuned model and generates a minimally corrected version which preserves correct content verbatim while fixing errors. A supervised fine-tuning loss then trains the fine-tuned model to produce the refined output. This mechanism yields a constraint that automatically strengthens or relaxes based on output quality. Experiments on dialogue and code generation show that dynamic constraints outperform both KL regularization and unconstrained baselines, achieving substantially higher task rewards while maintaining training stability.
MI-DETR: A Strong Baseline for Moving Infrared Small Target Detection with Bio-Inspired Motion Integration
Mar 05, 2026Infrared small target detection (ISTD) is challenging because tiny, low-contrast targets are easily obscured by complex and dynamic backgrounds. Conventional multi-frame approaches typically learn motion implicitly through deep neural networks, often requiring additional motion supervision or explicit alignment modules. We propose Motion Integration DETR (MI-DETR), a bio-inspired dual-pathway detector that processes one infrared frame per time step while explicitly modeling motion. First, a retina-inspired cellular automaton (RCA) converts raw frame sequences into a motion map defined on the same pixel grid as the appearance image, enabling parvocellular-like appearance and magnocellular-like motion pathways to be supervised by a single set of bounding boxes without extra motion labels or alignment operations. Second, a Parvocellular-Magnocellular Interconnection (PMI) Block facilitates bidirectional feature interaction between the two pathways, providing a biologically motivated intermediate interconnection mechanism. Finally, a RT-DETR decoder operates on features from the two pathways to produce detection results. Surprisingly, our proposed simple yet effective approach yields strong performance on three commonly used ISTD benchmarks. MI-DETR achieves 70.3% mAP@50 and 72.7% F1 on IRDST-H (+26.35 mAP@50 over the best multi-frame baseline), 98.0% mAP@50 on DAUB-R, and 88.3% mAP@50 on ITSDT-15K, demonstrating the effectiveness of biologically inspired motion-appearance integration. Code is available at https://github.com/nliu-25/MI-DETR.
Self-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
Heterogeneity in Multi-Agent Reinforcement Learning
Dec 28, 2025Heterogeneity is a fundamental property in multi-agent reinforcement learning (MARL), which is closely related not only to the functional differences of agents, but also to policy diversity and environmental interactions. However, the MARL field currently lacks a rigorous definition and deeper understanding of heterogeneity. This paper systematically discusses heterogeneity in MARL from the perspectives of definition, quantification, and utilization. First, based on an agent-level modeling of MARL, we categorize heterogeneity into five types and provide mathematical definitions. Second, we define the concept of heterogeneity distance and propose a practical quantification method. Third, we design a heterogeneity-based multi-agent dynamic parameter sharing algorithm as an example of the application of our methodology. Case studies demonstrate that our method can effectively identify and quantify various types of agent heterogeneity. Experimental results show that the proposed algorithm, compared to other parameter sharing baselines, has better interpretability and stronger adaptability. The proposed methodology will help the MARL community gain a more comprehensive and profound understanding of heterogeneity, and further promote the development of practical algorithms.
TacEleven: generative tactic discovery for football open play
Nov 18, 2025Creating offensive advantages during open play is fundamental to football success. However, due to the highly dynamic and long-sequence nature of open play, the potential tactic space grows exponentially as the sequence progresses, making automated tactic discovery extremely challenging. To address this, we propose TacEleven, a generative framework for football open-play tactic discovery developed in close collaboration with domain experts from AJ Auxerre, designed to assist coaches and analysts in tactical decision-making. TacEleven consists of two core components: a language-controlled tactical generator that produces diverse tactical proposals, and a multimodal large language model-based tactical critic that selects the optimal proposal aligned with a high-level stylistic tactical instruction. The two components enables rapid exploration of tactical proposals and discovery of alternative open-play offensive tactics. We evaluate TacEleven across three tasks with progressive tactical complexity: counterfactual exploration, single-step discovery, and multi-step discovery, through both quantitative metrics and a questionnaire-based qualitative assessment. The results show that the TacEleven-discovered tactics exhibit strong realism and tactical creativity, with 52.50% of the multi-step tactical alternatives rated adoptable in real-world elite football scenarios, highlighting the framework's ability to rapidly generate numerous high-quality tactics for complex long-sequence open-play situations. TacEleven demonstrates the potential of creatively leveraging domain data and generative models to advance tactical analysis in sports.
CoMoE: Contrastive Representation for Mixture-of-Experts in Parameter-Efficient Fine-tuning
May 23, 2025In parameter-efficient fine-tuning, mixture-of-experts (MoE), which involves specializing functionalities into different experts and sparsely activating them appropriately, has been widely adopted as a promising approach to trade-off between model capacity and computation overhead. However, current MoE variants fall short on heterogeneous datasets, ignoring the fact that experts may learn similar knowledge, resulting in the underutilization of MoE's capacity. In this paper, we propose Contrastive Representation for MoE (CoMoE), a novel method to promote modularization and specialization in MoE, where the experts are trained along with a contrastive objective by sampling from activated and inactivated experts in top-k routing. We demonstrate that such a contrastive objective recovers the mutual-information gap between inputs and the two types of experts. Experiments on several benchmarks and in multi-task settings demonstrate that CoMoE can consistently enhance MoE's capacity and promote modularization among the experts.
Unreal-MAP: Unreal-Engine-Based General Platform for Multi-Agent Reinforcement Learning
Mar 20, 2025In this paper, we propose Unreal Multi-Agent Playground (Unreal-MAP), an MARL general platform based on the Unreal-Engine (UE). Unreal-MAP allows users to freely create multi-agent tasks using the vast visual and physical resources available in the UE community, and deploy state-of-the-art (SOTA) MARL algorithms within them. Unreal-MAP is user-friendly in terms of deployment, modification, and visualization, and all its components are open-source. We also develop an experimental framework compatible with algorithms ranging from rule-based to learning-based provided by third-party frameworks. Lastly, we deploy several SOTA algorithms in example tasks developed via Unreal-MAP, and conduct corresponding experimental analyses. We believe Unreal-MAP can play an important role in the MARL field by closely integrating existing algorithms with user-customized tasks, thus advancing the field of MARL.
Stochastic Trajectory Prediction under Unstructured Constraints
Mar 18, 2025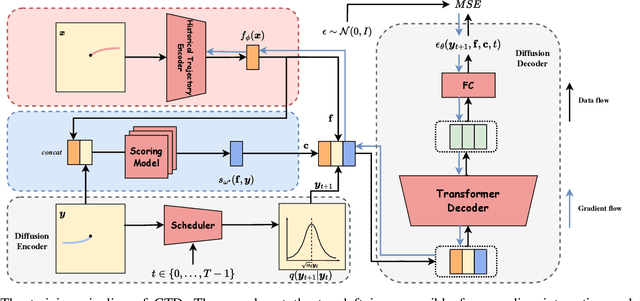
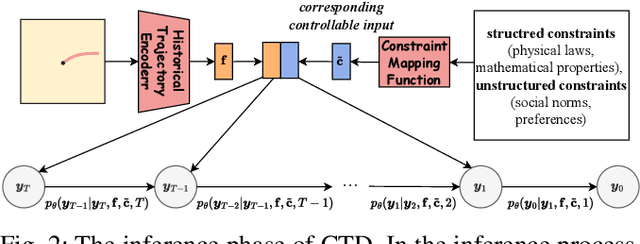
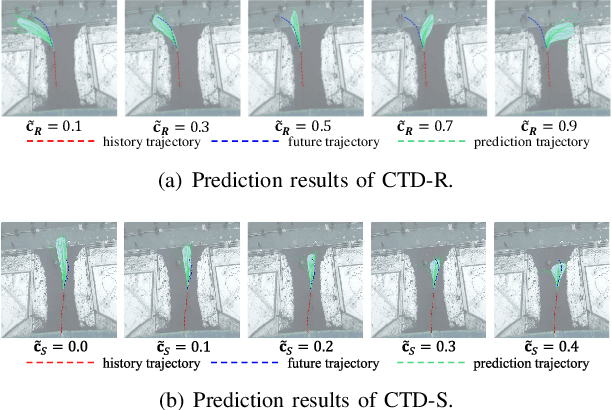
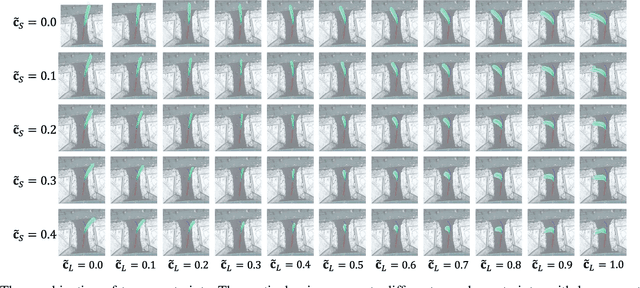
Trajectory prediction facilitates effective planning and decision-making, while constrained trajectory prediction integrates regulation into prediction. Recent advances in constrained trajectory prediction focus on structured constraints by constructing optimization objectives. However, handling unstructured constraints is challenging due to the lack of differentiable formal definitions. To address this, we propose a novel method for constrained trajectory prediction using a conditional generative paradigm, named Controllable Trajectory Diffusion (CTD). The key idea is that any trajectory corresponds to a degree of conformity to a constraint. By quantifying this degree and treating it as a condition, a model can implicitly learn to predict trajectories under unstructured constraints. CTD employs a pre-trained scoring model to predict the degree of conformity (i.e., a score), and uses this score as a condition for a conditional diffusion model to generate trajectories. Experimental results demonstrate that CTD achieves high accuracy on the ETH/UCY and SDD benchmarks. Qualitative analysis confirms that CTD ensures adherence to unstructured constraints and can predict trajectories that satisfy combinatorial constraints.
Causal Mean Field Multi-Agent Reinforcement Learning
Feb 20, 2025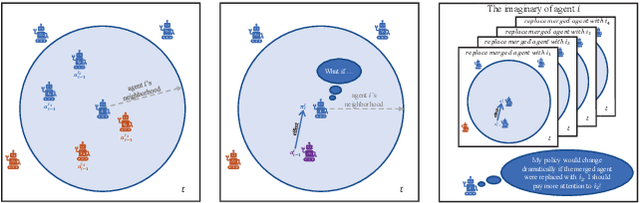
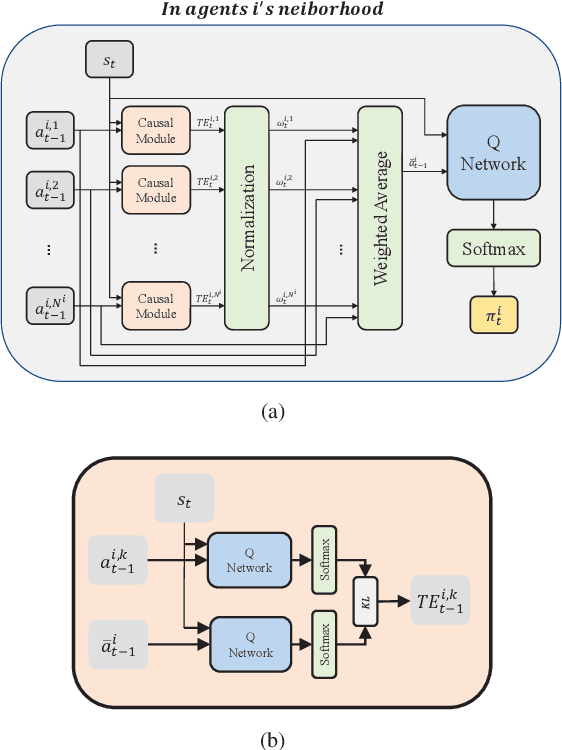
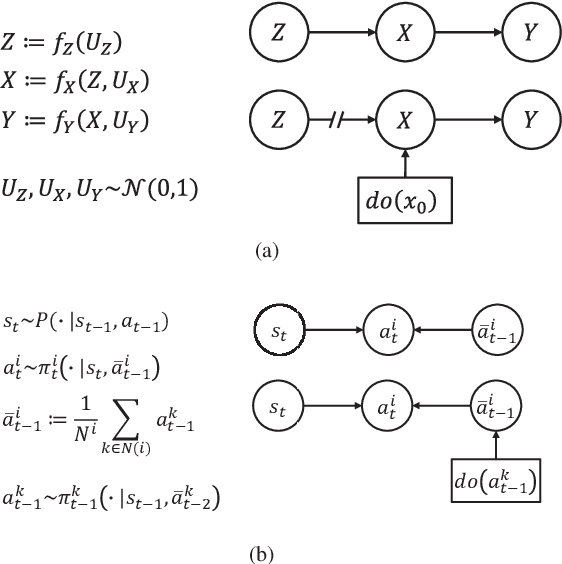
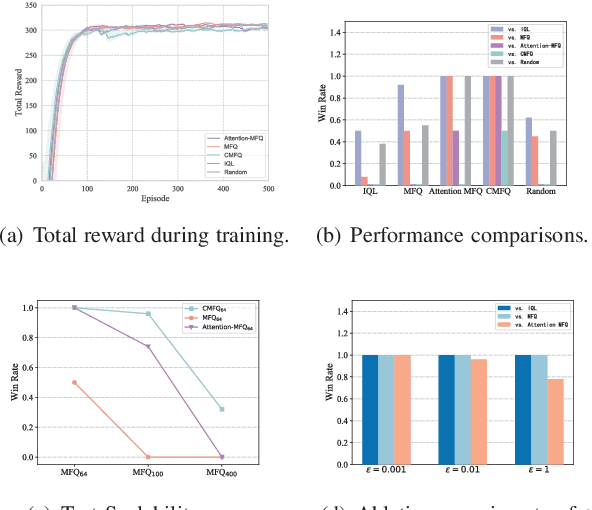
Scalability remains a challenge in multi-agent reinforcement learning and is currently under active research. A framework named mean-field reinforcement learning (MFRL) could alleviate the scalability problem by employing the Mean Field Theory to turn a many-agent problem into a two-agent problem. However, this framework lacks the ability to identify essential interactions under nonstationary environments. Causality contains relatively invariant mechanisms behind interactions, though environments are nonstationary. Therefore, we propose an algorithm called causal mean-field Q-learning (CMFQ) to address the scalability problem. CMFQ is ever more robust toward the change of the number of agents though inheriting the compressed representation of MFRL's action-state space. Firstly, we model the causality behind the decision-making process of MFRL into a structural causal model (SCM). Then the essential degree of each interaction is quantified via intervening on the SCM. Furthermore, we design the causality-aware compact representation for behavioral information of agents as the weighted sum of all behavioral information according to their causal effects. We test CMFQ in a mixed cooperative-competitive game and a cooperative game. The result shows that our method has excellent scalability performance in both training in environments containing a large number of agents and testing in environments containing much more agents.