 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARTI-MARS$^2$: Scaling Multi-Agent Self-Search via Reinforcement Learning for Code Generation
Feb 08, 2026While the complex reasoning capability of Large Language Models (LLMs) has attracted significant attention, single-agent systems often encounter inherent performance ceilings in complex tasks such as code generation. Multi-agent collaboration offers a promising avenue to transcend these boundaries. However, existing frameworks typically rely on prompt-based test-time interactions or multi-role configurations trained with homogeneous parameters, limiting error correction capabilities and strategic diversity. In this paper, we propose a Multi-Agent Reinforced Training and Inference Framework with Self-Search Scaling (MARTI-MARS2), which integrates policy learning with multi-agent tree search by formulating the multi-agent collaborative exploration process as a dynamic and learnable environment. By allowing agents to iteratively explore and refine within the environment, the framework facilitates evolution from parameter-sharing homogeneous multi-role training to heterogeneous multi-agent training, breaking through single-agent capability limits. We also introduce an efficient inference strategy MARTI-MARS2-T+ to fully exploit the scaling potential of multi-agent collaboration at test time. We conduct extensive experiments across varied model scales (8B, 14B, and 32B) on challenging code generation benchmarks. Utilizing two collaborating 32B models, MARTI-MARS2 achieves 77.7%, outperforming strong baselines like GPT-5.1. Furthermore, MARTI-MARS2 reveals a novel scaling law: shifting from single-agent to homogeneous multi-role and ultimately to heterogeneous multi-agent paradigms progressively yields higher RL performance ceilings, robust TTS capabilities, and greater policy diversity, suggesting that policy diversity is critical for scaling intelligence via multi-agent reinforcement learning.
TacEleven: generative tactic discovery for football open play
Nov 18, 2025Creating offensive advantages during open play is fundamental to football success. However, due to the highly dynamic and long-sequence nature of open play, the potential tactic space grows exponentially as the sequence progresses, making automated tactic discovery extremely challenging. To address this, we propose TacEleven, a generative framework for football open-play tactic discovery developed in close collaboration with domain experts from AJ Auxerre, designed to assist coaches and analysts in tactical decision-making. TacEleven consists of two core components: a language-controlled tactical generator that produces diverse tactical proposals, and a multimodal large language model-based tactical critic that selects the optimal proposal aligned with a high-level stylistic tactical instruction. The two components enables rapid exploration of tactical proposals and discovery of alternative open-play offensive tactics. We evaluate TacEleven across three tasks with progressive tactical complexity: counterfactual exploration, single-step discovery, and multi-step discovery, through both quantitative metrics and a questionnaire-based qualitative assessment. The results show that the TacEleven-discovered tactics exhibit strong realism and tactical creativity, with 52.50% of the multi-step tactical alternatives rated adoptable in real-world elite football scenarios, highlighting the framework's ability to rapidly generate numerous high-quality tactics for complex long-sequence open-play situations. TacEleven demonstrates the potential of creatively leveraging domain data and generative models to advance tactical analysis in sports.
Vision-Based Generic Potential Function for Policy Alignment in Multi-Agent Reinforcement Learning
Feb 19, 2025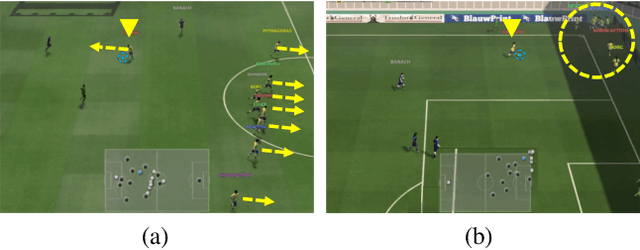
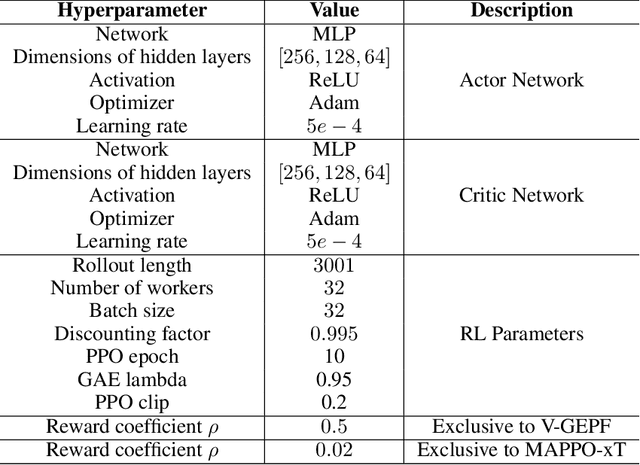
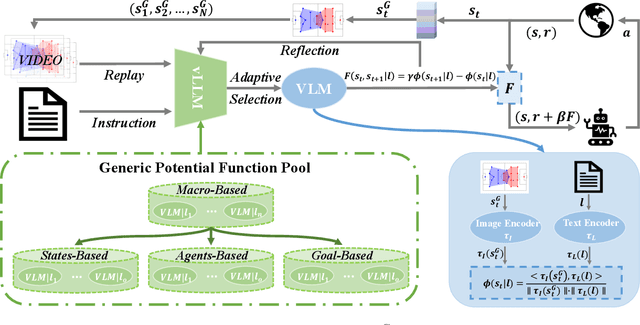
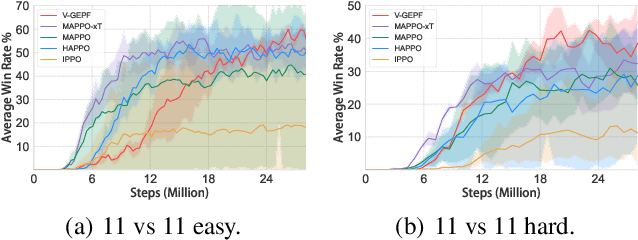
Guiding the policy of multi-agent reinforcement learning to align with human common sense is a difficult problem, largely due to the complexity of modeling common sense as a reward, especially in complex and long-horizon multi-agent tasks. Recent works have shown the effectiveness of reward shaping, such as potential-based rewards, to enhance policy alignment. The existing works, however, primarily rely on experts to design rule-based rewards, which are often labor-intensive and lack a high-level semantic understanding of common sense. To solve this problem, we propose a hierarchical vision-based reward shaping method. At the bottom layer, a visual-language model (VLM) serves as a generic potential function, guiding the policy to align with human common sense through its intrinsic semantic understanding. To help the policy adapts to uncertainty and changes in long-horizon tasks, the top layer features an adaptive skill selection module based on a visual large language model (vLLM). The module uses instructions, video replays, and training records to dynamically select suitable potential function from a pre-designed pool. Besides, our method is theoretically proven to preserve the optimal policy. Extensive experiments conducted in the Google Research Football environment demonstrate that our method not only achieves a higher win rate but also effectively aligns the policy with human common sense.