 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Soft Actor-Critic with LLM-Based Action-Level Guidance for Continuous Control
Mar 18, 2026We present GuidedSAC, a novel reinforcement learning (RL) algorithm that facilitates efficient exploration in vast state-action spaces. GuidedSAC leverages large language models (LLMs) as intelligent supervisors that provide action-level guidance for the Soft Actor-Critic (SAC) algorithm. The LLM-based supervisor analyzes the most recent trajectory using state information and visual replays, offering action-level interventions that enable targeted exploration. Furthermore, we provide a theoretical analysis of GuidedSAC, proving that it preserves the convergence guarantees of SAC while improving convergence speed. Through experiments in both discrete and continuous control environments, including toy text tasks and complex MuJoCo benchmarks, we demonstrate that GuidedSAC consistently outperforms standard SAC and state-of-the-art exploration-enhanced variants (e.g., RND, ICM, and E3B) in terms of sample efficiency and final performance.
Enhancing Reinforcement Learning Fine-Tuning with an Online Refiner
Mar 18, 2026Constraints are essential for stabilizing reinforcement learning fine-tuning (RFT) and preventing degenerate outputs, yet they inherently conflict with the optimization objective because stronger constraints limit the ability of a fine-tuned model to discover better solutions. We propose \textit{dynamic constraints} that resolve this tension by adapting to the evolving capabilities of the fine-tuned model based on the insight that constraints should only intervene when degenerate outputs occur. We implement this by using a reference model as an \textit{online refiner} that takes the response from the fine-tuned model and generates a minimally corrected version which preserves correct content verbatim while fixing errors. A supervised fine-tuning loss then trains the fine-tuned model to produce the refined output. This mechanism yields a constraint that automatically strengthens or relaxes based on output quality. Experiments on dialogue and code generation show that dynamic constraints outperform both KL regularization and unconstrained baselines, achieving substantially higher task rewards while maintaining training stability.
Vision-Based Generic Potential Function for Policy Alignment in Multi-Agent Reinforcement Learning
Feb 19, 2025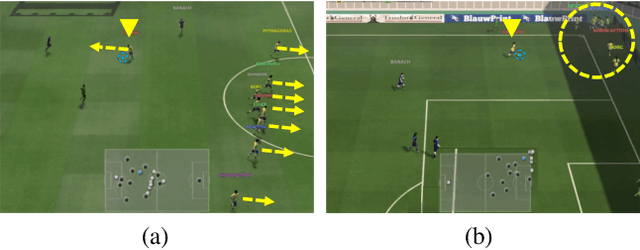
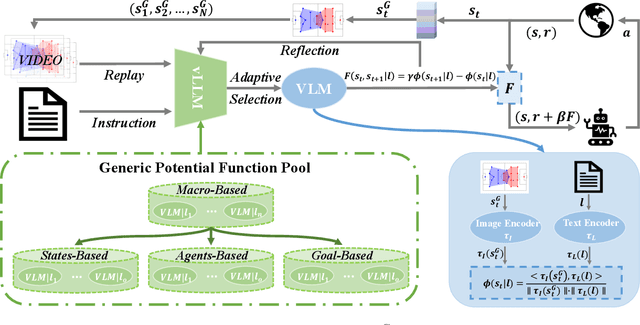
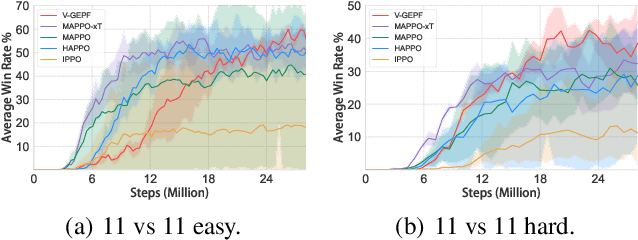
Guiding the policy of multi-agent reinforcement learning to align with human common sense is a difficult problem, largely due to the complexity of modeling common sense as a reward, especially in complex and long-horizon multi-agent tasks. Recent works have shown the effectiveness of reward shaping, such as potential-based rewards, to enhance policy alignment. The existing works, however, primarily rely on experts to design rule-based rewards, which are often labor-intensive and lack a high-level semantic understanding of common sense. To solve this problem, we propose a hierarchical vision-based reward shaping method. At the bottom layer, a visual-language model (VLM) serves as a generic potential function, guiding the policy to align with human common sense through its intrinsic semantic understanding. To help the policy adapts to uncertainty and changes in long-horizon tasks, the top layer features an adaptive skill selection module based on a visual large language model (vLLM). The module uses instructions, video replays, and training records to dynamically select suitable potential function from a pre-designed pool. Besides, our method is theoretically proven to preserve the optimal policy. Extensive experiments conducted in the Google Research Football environment demonstrate that our method not only achieves a higher win rate but also effectively aligns the policy with human common sense.
OMoE: Diversifying Mixture of Low-Rank Adaptation by Orthogonal Finetuning
Jan 17, 2025



Building mixture-of-experts (MoE) architecture for Low-rank adaptation (LoRA) is emerging as a potential direction in parameter-efficient fine-tuning (PEFT) for its modular design and remarkable performance. However, simply stacking the number of experts cannot guarantee significant improvement. In this work, we first conduct qualitative analysis to indicate that experts collapse to similar representations in vanilla MoE, limiting the capacity of modular design and computational efficiency. Ulteriorly, Our analysis reveals that the performance of previous MoE variants maybe limited by a lack of diversity among experts. Motivated by these findings, we propose Orthogonal Mixture-of-Experts (OMoE), a resource-efficient MoE variant that trains experts in an orthogonal manner to promote diversity. In OMoE, a Gram-Schmidt process is leveraged to enforce that the experts' representations lie within the Stiefel manifold. By applying orthogonal constraints directly to the architecture, OMoE keeps the learning objective unchanged, without compromising optimality. Our method is simple and alleviates memory bottlenecks, as it incurs minimal experts compared to vanilla MoE models. Experiments on diverse commonsense reasoning benchmarks demonstrate that OMoE can consistently achieve stable and efficient performance improvement when compared with the state-of-the-art methods while significantly reducing the number of required experts.
Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning
Oct 08, 2024



Reinforcement learning (RL) has emerged as a pivotal technique for fine-tuning large language models (LLMs) on specific tasks. However, prevailing RL fine-tuning methods predominantly rely on PPO and its variants. Though these algorithms are effective in general RL settings, they often exhibit suboptimal performance and vulnerability to distribution collapse when applied to the fine-tuning of LLMs. In this paper, we propose CORY, extending the RL fine-tuning of LLMs to a sequential cooperative multi-agent reinforcement learning framework, to leverage the inherent coevolution and emergent capabilities of multi-agent systems. In CORY, the LLM to be fine-tuned is initially duplicated into two autonomous agents: a pioneer and an observer. The pioneer generates responses based on queries, while the observer generates responses using both the queries and the pioneer's responses. The two agents are trained together. During training, the agents exchange roles periodically, fostering cooperation and coevolution between them. Experiments evaluate CORY's performance by fine-tuning GPT-2 and Llama-2 under subjective and objective reward functions on the IMDB Review and GSM8K datasets, respectively. Results show that CORY outperforms PPO in terms of policy optimality, resistance to distribution collapse, and training robustness, thereby underscoring its potential as a superior methodology for refining LLMs in real-world applications.
Self-Clustering Hierarchical Multi-Agent Reinforcement Learning with Extensible Cooperation Graph
Mar 26, 2024



Multi-Agent Reinforcement Learning (MARL) has been successful in solving many cooperative challenges. However, classic non-hierarchical MARL algorithms still cannot address various complex multi-agent problems that require hierarchical cooperative behaviors. The cooperative knowledge and policies learned in non-hierarchical algorithms are implicit and not interpretable, thereby restricting the integration of existing knowledge. This paper proposes a novel hierarchical MARL model called Hierarchical Cooperation Graph Learning (HCGL) for solving general multi-agent problems. HCGL has three components: a dynamic Extensible Cooperation Graph (ECG) for achieving self-clustering cooperation; a group of graph operators for adjusting the topology of ECG; and an MARL optimizer for training these graph operators. HCGL's key distinction from other MARL models is that the behaviors of agents are guided by the topology of ECG instead of policy neural networks. ECG is a three-layer graph consisting of an agent node layer, a cluster node layer, and a target node layer. To manipulate the ECG topology in response to changing environmental conditions, four graph operators are trained to adjust the edge connections of ECG dynamically. The hierarchical feature of ECG provides a unique approach to merge primitive actions (actions executed by the agents) and cooperative actions (actions executed by the clusters) into a unified action space, allowing us to integrate fundamental cooperative knowledge into an extensible interface. In our experiments, the HCGL model has shown outstanding performance in multi-agent benchmarks with sparse rewards. We also verify that HCGL can easily be transferred to large-scale scenarios with high zero-shot transfer success rates.
Measuring Policy Distance for Multi-Agent Reinforcement Learning
Jan 28, 2024



Diversity plays a crucial role in improving the performance of multi-agent reinforcement learning (MARL). Currently, many diversity-based methods have been developed to overcome the drawbacks of excessive parameter sharing in traditional MARL. However, there remains a lack of a general metric to quantify policy differences among agents. Such a metric would not only facilitate the evaluation of the diversity evolution in multi-agent systems, but also provide guidance for the design of diversity-based MARL algorithms. In this paper, we propose the multi-agent policy distance (MAPD), a general tool for measuring policy differences in MARL. By learning the conditional representations of agents' decisions, MAPD can computes the policy distance between any pair of agents. Furthermore, we extend MAPD to a customizable version, which can quantify differences among agent policies on specified aspects. Based on the online deployment of MAPD, we design a multi-agent dynamic parameter sharing (MADPS) algorithm as an example of the MAPD's applications. Extensive experiments demonstrate that our method is effective in measuring differences in agent policies and specific behavioral tendencies. Moreover, in comparison to other methods of parameter sharing, MADPS exhibits superior performance.
Learning Heterogeneous Agent Cooperation via Multiagent League Training
Nov 13, 2022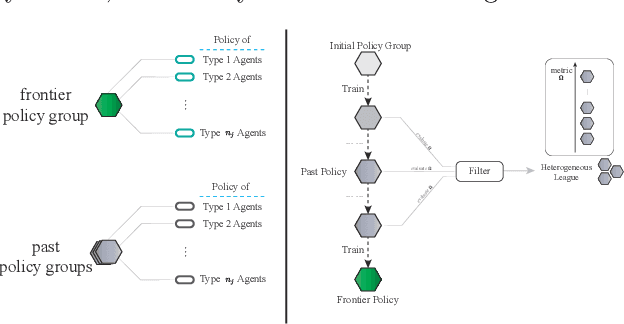
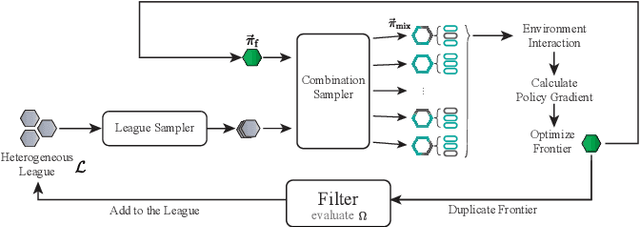
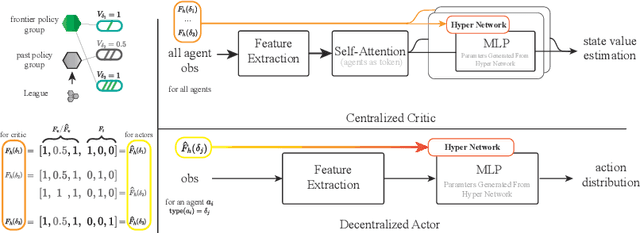
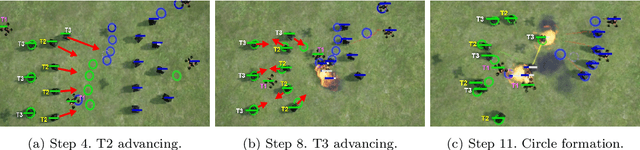
Many multiagent systems in the real world include multiple types of agents with different abilities and functionality. Such heterogeneous multiagent systems have significant practical advantages. However, they also come with challenges compared with homogeneous systems for multiagent reinforcement learning, such as the non-stationary problem and the policy version iteration issue. This work proposes a general-purpose reinforcement learning algorithm named as Heterogeneous League Training (HLT) to address heterogeneous multiagent problems. HLT keeps track of a pool of policies that agents have explored during training, gathering a league of heterogeneous policies to facilitate future policy optimization. Moreover, a hyper-network is introduced to increase the diversity of agent behaviors when collaborating with teammates having different levels of cooperation skills. We use heterogeneous benchmark tasks to demonstrate that (1) HLT promotes the success rate in cooperative heterogeneous tasks; (2) HLT is an effective approach to solving the policy version iteration problem; (3) HLT provides a practical way to assess the difficulty of learning each role in a heterogeneous team.
Solving the Diffusion of Responsibility Problem in Multiagent Reinforcement Learning with a Policy Resonance Approach
Aug 19, 2022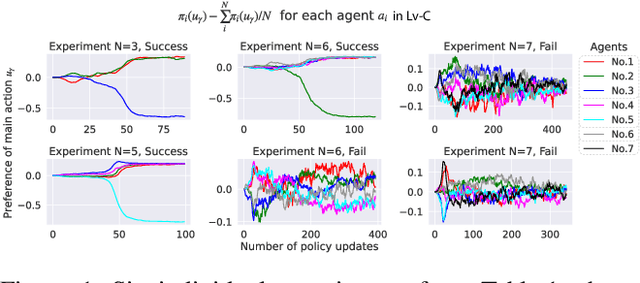
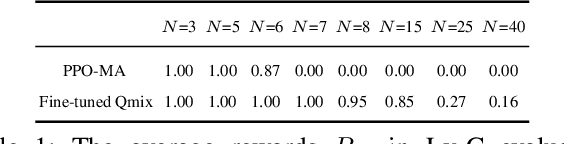
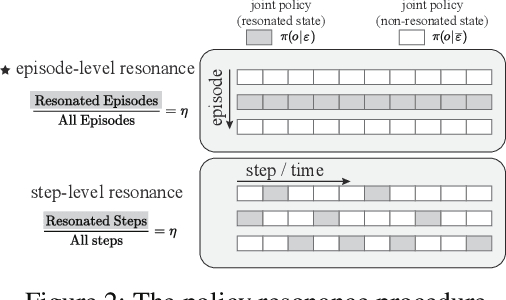
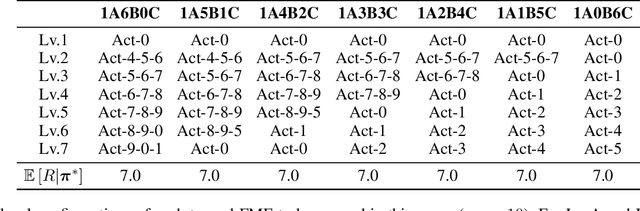
SOTA multiagent reinforcement algorithms distinguish themselves in many ways from their single-agent equivalences, except that they still totally inherit the single-agent exploration-exploitation strategy. We report that naively inheriting this strategy from single-agent algorithms causes potential collaboration failures, in which the agents blindly follow mainstream behaviors and reject taking minority responsibility. We named this problem the diffusion of responsibility (DR) as it shares similarities with a same-name social psychology effect. In this work, we start by theoretically analyzing the cause of the DR problem, emphasizing it is not relevant to the reward crafting or the credit assignment problems. We propose a Policy Resonance approach to address the DR problem by modifying the multiagent exploration-exploitation strategy. Next, we show that most SOTA algorithms can equip this approach to promote collaborative agent performance in complex cooperative tasks. Experiments are performed in multiple test benchmark tasks to illustrate the effectiveness of this approach.