 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
CoMoE: Contrastive Representation for Mixture-of-Experts in Parameter-Efficient Fine-tuning
May 23, 2025In parameter-efficient fine-tuning, mixture-of-experts (MoE), which involves specializing functionalities into different experts and sparsely activating them appropriately, has been widely adopted as a promising approach to trade-off between model capacity and computation overhead. However, current MoE variants fall short on heterogeneous datasets, ignoring the fact that experts may learn similar knowledge, resulting in the underutilization of MoE's capacity. In this paper, we propose Contrastive Representation for MoE (CoMoE), a novel method to promote modularization and specialization in MoE, where the experts are trained along with a contrastive objective by sampling from activated and inactivated experts in top-k routing. We demonstrate that such a contrastive objective recovers the mutual-information gap between inputs and the two types of experts. Experiments on several benchmarks and in multi-task settings demonstrate that CoMoE can consistently enhance MoE's capacity and promote modularization among the experts.
OMoE: Diversifying Mixture of Low-Rank Adaptation by Orthogonal Finetuning
Jan 17, 2025



Building mixture-of-experts (MoE) architecture for Low-rank adaptation (LoRA) is emerging as a potential direction in parameter-efficient fine-tuning (PEFT) for its modular design and remarkable performance. However, simply stacking the number of experts cannot guarantee significant improvement. In this work, we first conduct qualitative analysis to indicate that experts collapse to similar representations in vanilla MoE, limiting the capacity of modular design and computational efficiency. Ulteriorly, Our analysis reveals that the performance of previous MoE variants maybe limited by a lack of diversity among experts. Motivated by these findings, we propose Orthogonal Mixture-of-Experts (OMoE), a resource-efficient MoE variant that trains experts in an orthogonal manner to promote diversity. In OMoE, a Gram-Schmidt process is leveraged to enforce that the experts' representations lie within the Stiefel manifold. By applying orthogonal constraints directly to the architecture, OMoE keeps the learning objective unchanged, without compromising optimality. Our method is simple and alleviates memory bottlenecks, as it incurs minimal experts compared to vanilla MoE models. Experiments on diverse commonsense reasoning benchmarks demonstrate that OMoE can consistently achieve stable and efficient performance improvement when compared with the state-of-the-art methods while significantly reducing the number of required experts.
Efficient Multi-Task Reinforcement Learning via Task-Specific Action Correction
Apr 09, 2024



Multi-task reinforcement learning (MTRL) demonstrate potential for enhancing the generalization of a robot, enabling it to perform multiple tasks concurrently. However, the performance of MTRL may still be susceptible to conflicts between tasks and negative interference. To facilitate efficient MTRL, we propose Task-Specific Action Correction (TSAC), a general and complementary approach designed for simultaneous learning of multiple tasks. TSAC decomposes policy learning into two separate policies: a shared policy (SP) and an action correction policy (ACP). To alleviate conflicts resulting from excessive focus on specific tasks' details in SP, ACP incorporates goal-oriented sparse rewards, enabling an agent to adopt a long-term perspective and achieve generalization across tasks. Additional rewards transform the original problem into a multi-objective MTRL problem. Furthermore, to convert the multi-objective MTRL into a single-objective formulation, TSAC assigns a virtual expected budget to the sparse rewards and employs Lagrangian method to transform a constrained single-objective optimization into an unconstrained one. Experimental evaluations conducted on Meta-World's MT10 and MT50 benchmarks demonstrate that TSAC outperforms existing state-of-the-art methods, achieving significant improvements in both sample efficiency and effective action execution.
TSI: Temporal Saliency Integration for Video Action Recognition
Jun 02, 2021



Efficient spatiotemporal modeling is an important yet challenging problem for video action recognition. Existing state-of-the-art methods exploit motion clues to assist in short-term temporal modeling through temporal difference over consecutive frames. However, background noises will be inevitably introduced due to the camera movement. Besides, movements of different actions can vary greatly. In this paper, we propose a Temporal Saliency Integration (TSI) block, which mainly contains a Salient Motion Excitation (SME) module and a Cross-scale Temporal Integration (CTI) module. Specifically, SME aims to highlight the motion-sensitive area through local-global motion modeling, where the background suppression and pyramidal feature difference are conducted successively between neighboring frames to capture motion dynamics with less background noises. CTI is designed to perform multi-scale temporal modeling through a group of separate 1D convolutions respectively. Meanwhile, temporal interactions across different scales are integrated with attention mechanism. Through these two modules, long short-term temporal relationships can be encoded efficiently by introducing limited additional parameters. Extensive experiments are conducted on several popular benchmarks (i.e., Something-Something v1 & v2, Kinetics-400, UCF-101, and HMDB-51), which demonstrate the effectiveness and superiority of our proposed method.
Complementary Boundary Generator with Scale-Invariant Relation Modeling for Temporal Action Localization: Submission to ActivityNet Challenge 2020
Aug 26, 2020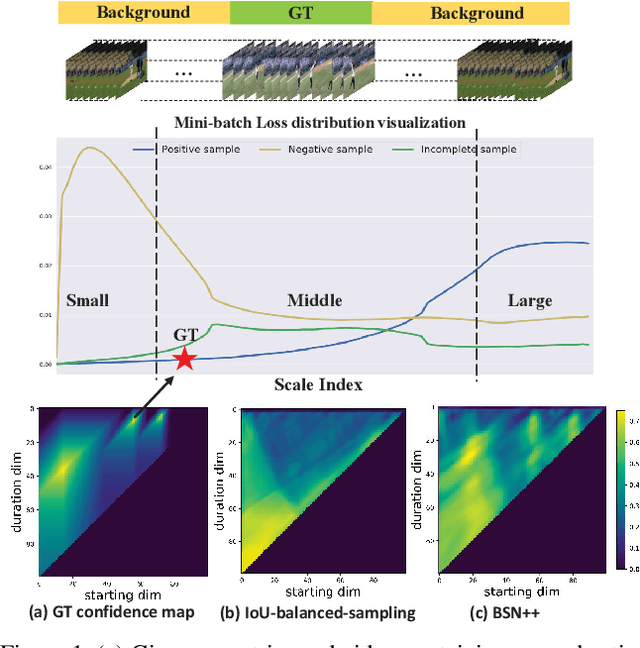
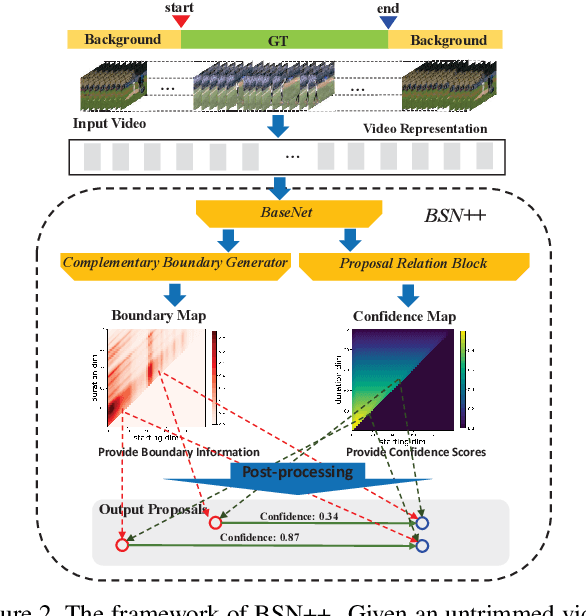
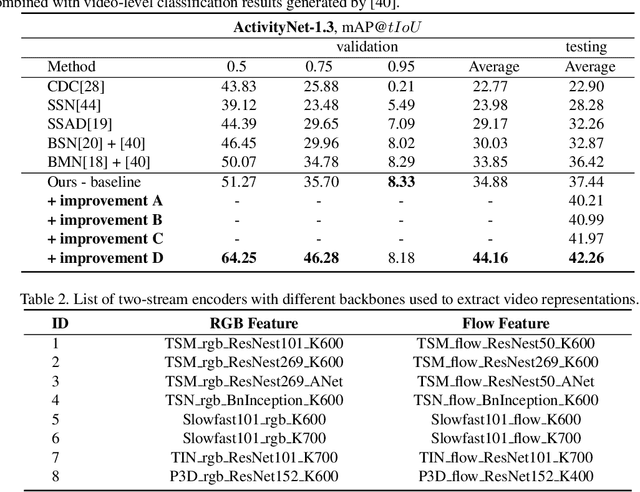
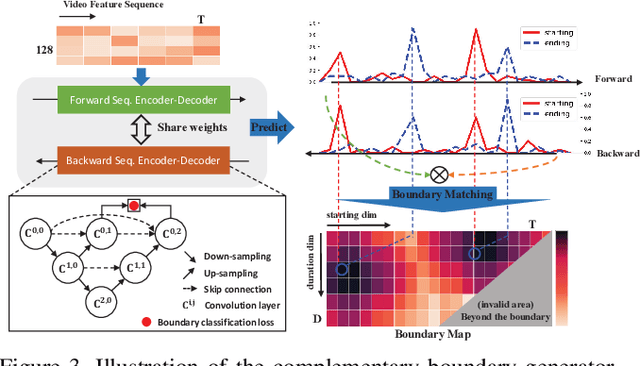
This technical report presents an overview of our solution used in the submission to ActivityNet Challenge 2020 Task 1 (\textbf{temporal action localization/detection}). Temporal action localization requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. In this paper, we decouple the temporal action localization task into two stages (i.e. proposal generation and classification) and enrich the proposal diversity through exhaustively exploring the influences of multiple components from different but complementary perspectives. Specifically, in order to generate high-quality proposals, we consider several factors including the video feature encoder, the proposal generator, the proposal-proposal relations, the scale imbalance, and ensemble strategy. Finally, in order to obtain accurate detections, we need to further train an optimal video classifier to recognize the generated proposals. Our proposed scheme achieves the state-of-the-art performance on the temporal action localization task with \textbf{42.26} average mAP on the challenge testing set.