 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Trajectory Prediction under Unstructured Constraints
Mar 18, 2025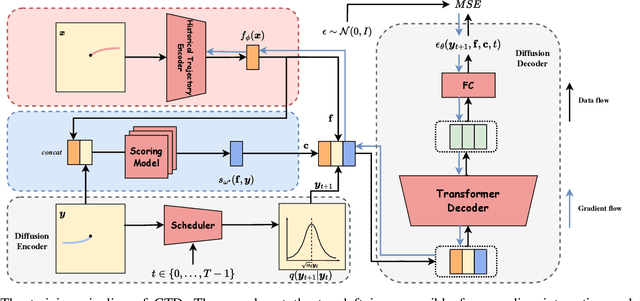
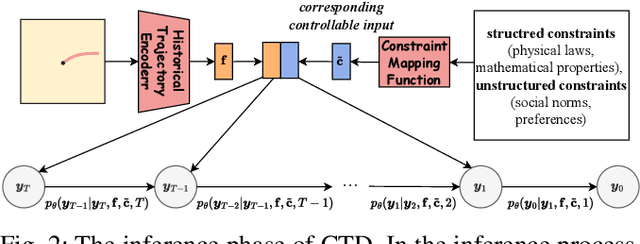
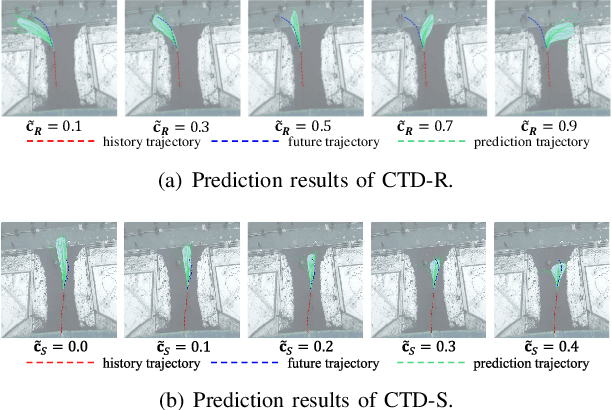
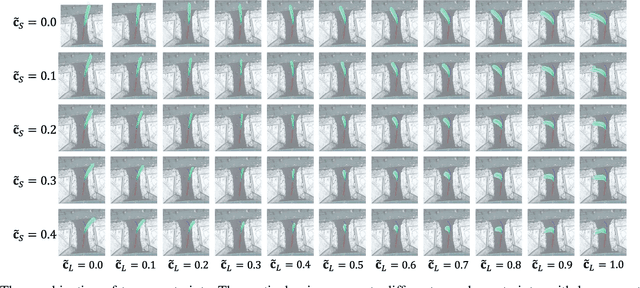
Trajectory prediction facilitates effective planning and decision-making, while constrained trajectory prediction integrates regulation into prediction. Recent advances in constrained trajectory prediction focus on structured constraints by constructing optimization objectives. However, handling unstructured constraints is challenging due to the lack of differentiable formal definitions. To address this, we propose a novel method for constrained trajectory prediction using a conditional generative paradigm, named Controllable Trajectory Diffusion (CTD). The key idea is that any trajectory corresponds to a degree of conformity to a constraint. By quantifying this degree and treating it as a condition, a model can implicitly learn to predict trajectories under unstructured constraints. CTD employs a pre-trained scoring model to predict the degree of conformity (i.e., a score), and uses this score as a condition for a conditional diffusion model to generate trajectories. Experimental results demonstrate that CTD achieves high accuracy on the ETH/UCY and SDD benchmarks. Qualitative analysis confirms that CTD ensures adherence to unstructured constraints and can predict trajectories that satisfy combinatorial constraints.
Efficient Multi-Task Reinforcement Learning via Task-Specific Action Correction
Apr 09, 2024



Multi-task reinforcement learning (MTRL) demonstrate potential for enhancing the generalization of a robot, enabling it to perform multiple tasks concurrently. However, the performance of MTRL may still be susceptible to conflicts between tasks and negative interference. To facilitate efficient MTRL, we propose Task-Specific Action Correction (TSAC), a general and complementary approach designed for simultaneous learning of multiple tasks. TSAC decomposes policy learning into two separate policies: a shared policy (SP) and an action correction policy (ACP). To alleviate conflicts resulting from excessive focus on specific tasks' details in SP, ACP incorporates goal-oriented sparse rewards, enabling an agent to adopt a long-term perspective and achieve generalization across tasks. Additional rewards transform the original problem into a multi-objective MTRL problem. Furthermore, to convert the multi-objective MTRL into a single-objective formulation, TSAC assigns a virtual expected budget to the sparse rewards and employs Lagrangian method to transform a constrained single-objective optimization into an unconstrained one. Experimental evaluations conducted on Meta-World's MT10 and MT50 benchmarks demonstrate that TSAC outperforms existing state-of-the-art methods, achieving significant improvements in both sample efficiency and effective action execution.
Prioritized League Reinforcement Learning for Large-Scale Heterogeneous Multiagent Systems
Mar 26, 2024Large-scale heterogeneous multiagent systems feature various realistic factors in the real world, such as agents with diverse abilities and overall system cost. In comparison to homogeneous systems, heterogeneous systems offer significant practical advantages. Nonetheless, they also present challenges for multiagent reinforcement learning, including addressing the non-stationary problem and managing an imbalanced number of agents with different types. We propose a Prioritized Heterogeneous League Reinforcement Learning (PHLRL) method to address large-scale heterogeneous cooperation problems. PHLRL maintains a record of various policies that agents have explored during their training and establishes a heterogeneous league consisting of diverse policies to aid in future policy optimization. Furthermore, we design a prioritized policy gradient approach to compensate for the gap caused by differences in the number of different types of agents. Next, we use Unreal Engine to design a large-scale heterogeneous cooperation benchmark named Large-Scale Multiagent Operation (LSMO), which is a complex two-team competition scenario that requires collaboration from both ground and airborne agents. We use experiments to show that PHLRL outperforms state-of-the-art methods, including QTRAN and QPLEX in LSMO.
Self-Clustering Hierarchical Multi-Agent Reinforcement Learning with Extensible Cooperation Graph
Mar 26, 2024



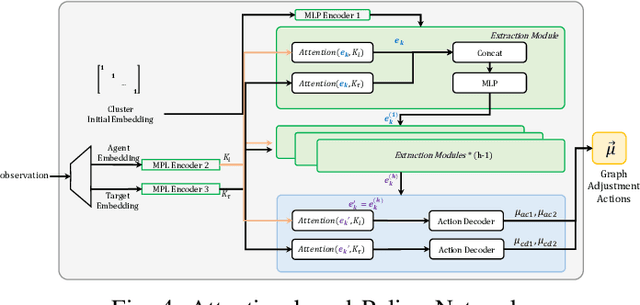
Multi-Agent Reinforcement Learning (MARL) has been successful in solving many cooperative challenges. However, classic non-hierarchical MARL algorithms still cannot address various complex multi-agent problems that require hierarchical cooperative behaviors. The cooperative knowledge and policies learned in non-hierarchical algorithms are implicit and not interpretable, thereby restricting the integration of existing knowledge. This paper proposes a novel hierarchical MARL model called Hierarchical Cooperation Graph Learning (HCGL) for solving general multi-agent problems. HCGL has three components: a dynamic Extensible Cooperation Graph (ECG) for achieving self-clustering cooperation; a group of graph operators for adjusting the topology of ECG; and an MARL optimizer for training these graph operators. HCGL's key distinction from other MARL models is that the behaviors of agents are guided by the topology of ECG instead of policy neural networks. ECG is a three-layer graph consisting of an agent node layer, a cluster node layer, and a target node layer. To manipulate the ECG topology in response to changing environmental conditions, four graph operators are trained to adjust the edge connections of ECG dynamically. The hierarchical feature of ECG provides a unique approach to merge primitive actions (actions executed by the agents) and cooperative actions (actions executed by the clusters) into a unified action space, allowing us to integrate fundamental cooperative knowledge into an extensible interface. In our experiments, the HCGL model has shown outstanding performance in multi-agent benchmarks with sparse rewards. We also verify that HCGL can easily be transferred to large-scale scenarios with high zero-shot transfer success rates.
Measuring Policy Distance for Multi-Agent Reinforcement Learning
Jan 28, 2024



Diversity plays a crucial role in improving the performance of multi-agent reinforcement learning (MARL). Currently, many diversity-based methods have been developed to overcome the drawbacks of excessive parameter sharing in traditional MARL. However, there remains a lack of a general metric to quantify policy differences among agents. Such a metric would not only facilitate the evaluation of the diversity evolution in multi-agent systems, but also provide guidance for the design of diversity-based MARL algorithms. In this paper, we propose the multi-agent policy distance (MAPD), a general tool for measuring policy differences in MARL. By learning the conditional representations of agents' decisions, MAPD can computes the policy distance between any pair of agents. Furthermore, we extend MAPD to a customizable version, which can quantify differences among agent policies on specified aspects. Based on the online deployment of MAPD, we design a multi-agent dynamic parameter sharing (MADPS) algorithm as an example of the MAPD's applications. Extensive experiments demonstrate that our method is effective in measuring differences in agent policies and specific behavioral tendencies. Moreover, in comparison to other methods of parameter sharing, MADPS exhibits superior performance.
Learning Heterogeneous Agent Cooperation via Multiagent League Training
Nov 13, 2022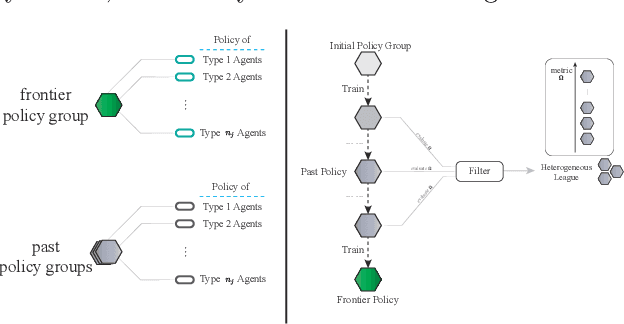
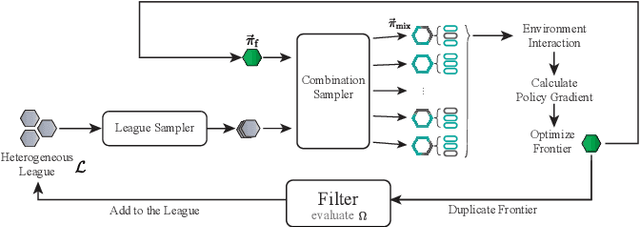
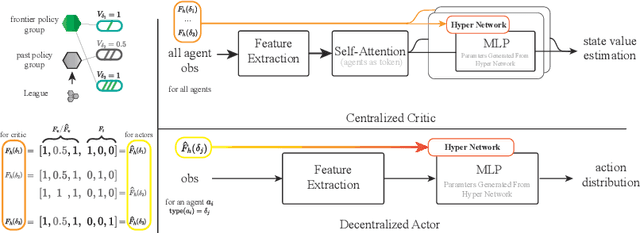
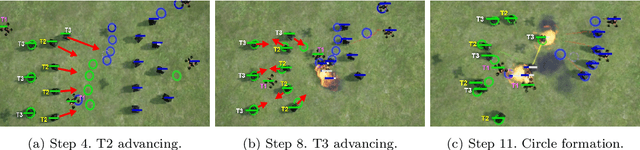
Many multiagent systems in the real world include multiple types of agents with different abilities and functionality. Such heterogeneous multiagent systems have significant practical advantages. However, they also come with challenges compared with homogeneous systems for multiagent reinforcement learning, such as the non-stationary problem and the policy version iteration issue. This work proposes a general-purpose reinforcement learning algorithm named as Heterogeneous League Training (HLT) to address heterogeneous multiagent problems. HLT keeps track of a pool of policies that agents have explored during training, gathering a league of heterogeneous policies to facilitate future policy optimization. Moreover, a hyper-network is introduced to increase the diversity of agent behaviors when collaborating with teammates having different levels of cooperation skills. We use heterogeneous benchmark tasks to demonstrate that (1) HLT promotes the success rate in cooperative heterogeneous tasks; (2) HLT is an effective approach to solving the policy version iteration problem; (3) HLT provides a practical way to assess the difficulty of learning each role in a heterogeneous team.
Solving the Diffusion of Responsibility Problem in Multiagent Reinforcement Learning with a Policy Resonance Approach
Aug 19, 2022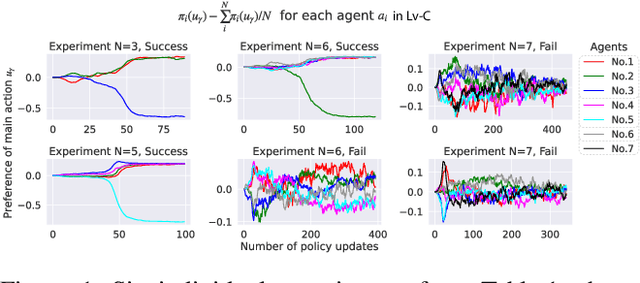
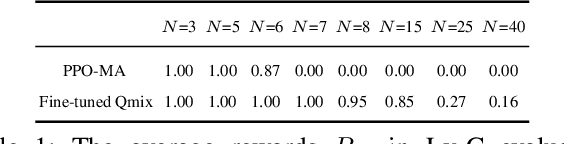
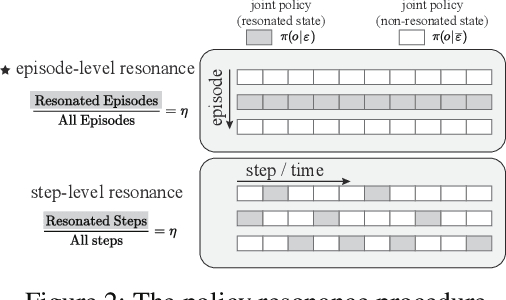
SOTA multiagent reinforcement algorithms distinguish themselves in many ways from their single-agent equivalences, except that they still totally inherit the single-agent exploration-exploitation strategy. We report that naively inheriting this strategy from single-agent algorithms causes potential collaboration failures, in which the agents blindly follow mainstream behaviors and reject taking minority responsibility. We named this problem the diffusion of responsibility (DR) as it shares similarities with a same-name social psychology effect. In this work, we start by theoretically analyzing the cause of the DR problem, emphasizing it is not relevant to the reward crafting or the credit assignment problems. We propose a Policy Resonance approach to address the DR problem by modifying the multiagent exploration-exploitation strategy. Next, we show that most SOTA algorithms can equip this approach to promote collaborative agent performance in complex cooperative tasks. Experiments are performed in multiple test benchmark tasks to illustrate the effectiveness of this approach.
A Cooperation Graph Approach for Multiagent Sparse Reward Reinforcement Learning
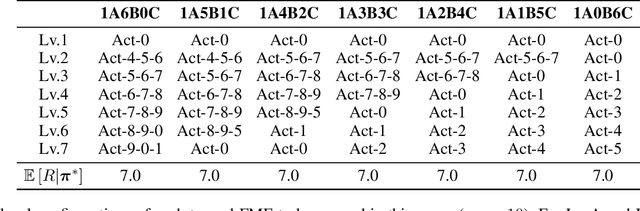
Aug 05, 2022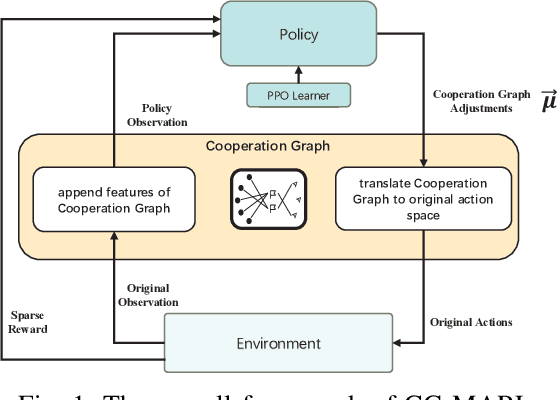
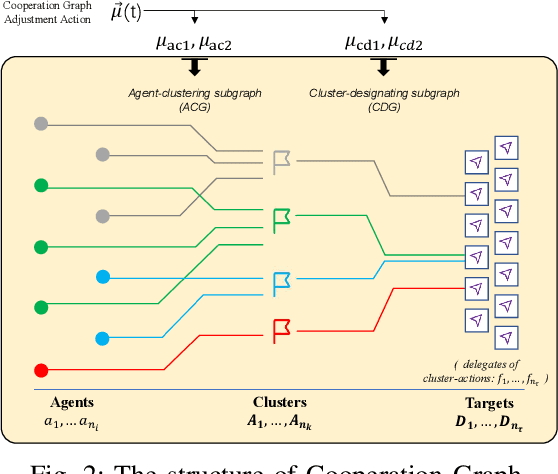
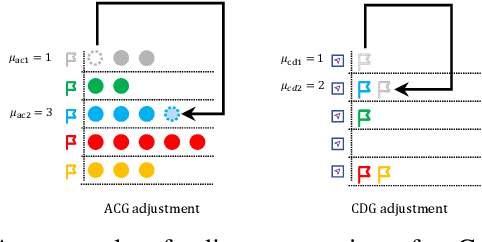
Multiagent reinforcement learning (MARL) can solve complex cooperative tasks. However, the efficiency of existing MARL methods relies heavily on well-defined reward functions. Multiagent tasks with sparse reward feedback are especially challenging not only because of the credit distribution problem, but also due to the low probability of obtaining positive reward feedback. In this paper, we design a graph network called Cooperation Graph (CG). The Cooperation Graph is the combination of two simple bipartite graphs, namely, the Agent Clustering subgraph (ACG) and the Cluster Designating subgraph (CDG). Next, based on this novel graph structure, we propose a Cooperation Graph Multiagent Reinforcement Learning (CG-MARL) algorithm, which can efficiently deal with the sparse reward problem in multiagent tasks. In CG-MARL, agents are directly controlled by the Cooperation Graph. And a policy neural network is trained to manipulate this Cooperation Graph, guiding agents to achieve cooperation in an implicit way. This hierarchical feature of CG-MARL provides space for customized cluster-actions, an extensible interface for introducing fundamental cooperation knowledge. In experiments, CG-MARL shows state-of-the-art performance in sparse reward multiagent benchmarks, including the anti-invasion interception task and the multi-cargo delivery task.
Concentration Network for Reinforcement Learning of Large-Scale Multi-Agent Systems
Apr 07, 2022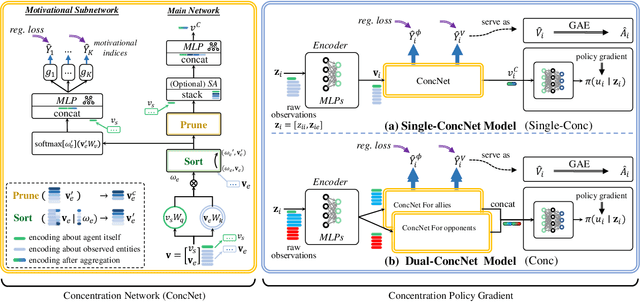
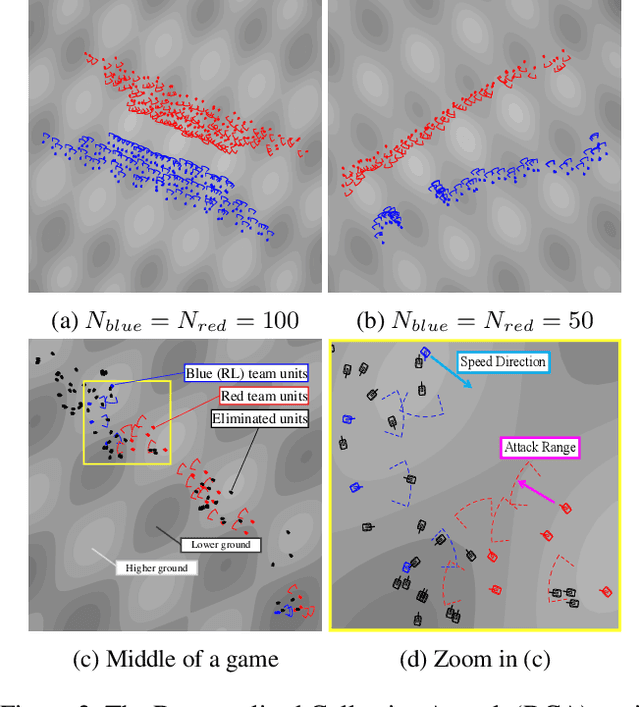

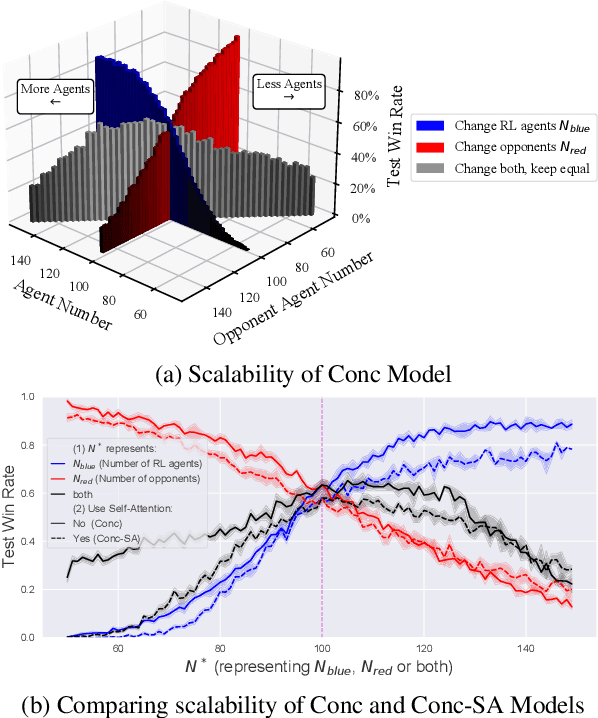
When dealing with a series of imminent issues, humans can naturally concentrate on a subset of these concerning issues by prioritizing them according to their contributions to motivational indices, e.g., the probability of winning a game. This idea of concentration offers insights into reinforcement learning of sophisticated Large-scale Multi-Agent Systems (LMAS) participated by hundreds of agents. In such an LMAS, each agent receives a long series of entity observations at each step, which can overwhelm existing aggregation networks such as graph attention networks and cause inefficiency. In this paper, we propose a concentration network called ConcNet. First, ConcNet scores the observed entities considering several motivational indices, e.g., expected survival time and state value of the agents, and then ranks, prunes, and aggregates the encodings of observed entities to extract features. Second, distinct from the well-known attention mechanism, ConcNet has a unique motivational subnetwork to explicitly consider the motivational indices when scoring the observed entities. Furthermore, we present a concentration policy gradient architecture that can learn effective policies in LMAS from scratch. Extensive experiments demonstrate that the presented architecture has excellent scalability and flexibility, and significantly outperforms existing methods on LMAS benchmarks.