 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalPre: Scalable and Effective Data Pre-processing for Causal Fairness
Sep 18, 2025Causal fairness in databases is crucial to preventing biased and inaccurate outcomes in downstream tasks. While most prior work assumes a known causal model, recent efforts relax this assumption by enforcing additional constraints. However, these approaches often fail to capture broader attribute relationships that are critical to maintaining utility. This raises a fundamental question: Can we harness the benefits of causal reasoning to design efficient and effective fairness solutions without relying on strong assumptions about the underlying causal model? In this paper, we seek to answer this question by introducing CausalPre, a scalable and effective causality-guided data pre-processing framework that guarantees justifiable fairness, a strong causal notion of fairness. CausalPre extracts causally fair relationships by reformulating the originally complex and computationally infeasible extraction task into a tailored distribution estimation problem. To ensure scalability, CausalPre adopts a carefully crafted variant of low-dimensional marginal factorization to approximate the joint distribution, complemented by a heuristic algorithm that efficiently tackles the associated computational challenge. Extensive experiments on benchmark datasets demonstrate that CausalPre is both effective and scalable, challenging the conventional belief that achieving causal fairness requires trading off relationship coverage for relaxed model assumptions.
Mining Platoon Patterns from Traffic Videos
Dec 28, 2024Discovering co-movement patterns from urban-scale video data sources has emerged as an attractive topic. This task aims to identify groups of objects that travel together along a common route, which offers effective support for government agencies in enhancing smart city management. However, the previous work has made a strong assumption on the accuracy of recovered trajectories from videos and their co-movement pattern definition requires the group of objects to appear across consecutive cameras along the common route. In practice, this often leads to missing patterns if a vehicle is not correctly identified from a certain camera due to object occlusion or vehicle mis-matching. To address this challenge, we propose a relaxed definition of co-movement patterns from video data, which removes the consecutiveness requirement in the common route and accommodates a certain number of missing captured cameras for objects within the group. Moreover, a novel enumeration framework called MaxGrowth is developed to efficiently retrieve the relaxed patterns. Unlike previous filter-and-refine frameworks comprising both candidate enumeration and subsequent candidate verification procedures, MaxGrowth incurs no verification cost for the candidate patterns. It treats the co-movement pattern as an equivalent sequence of clusters, enumerating candidates with increasing sequence length while avoiding the generation of any false positives. Additionally, we also propose two effective pruning rules to efficiently filter the non-maximal patterns. Extensive experiments are conducted to validate the efficiency of MaxGrowth and the quality of its generated co-movement patterns. Our MaxGrowth runs up to two orders of magnitude faster than the baseline algorithm. It also demonstrates high accuracy in real video dataset when the trajectory recovery algorithm is not perfect.
Sense The Physical, Walkthrough The Virtual, Manage The Metaverse: A Data-centric Perspective
Jun 14, 2022
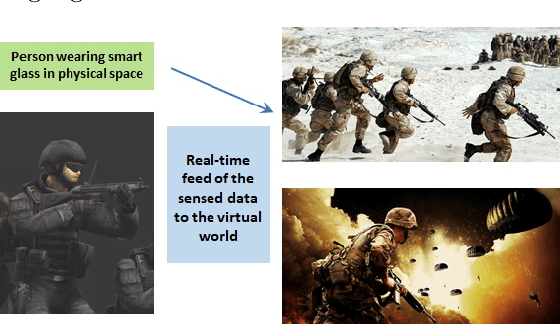
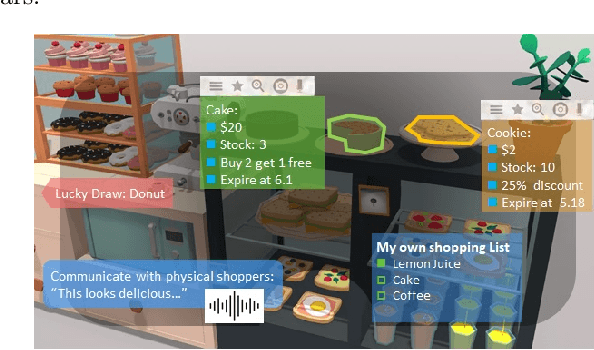

In the Metaverse, the physical space and the virtual space co-exist, and interact simultaneously. While the physical space is virtually enhanced with information, the virtual space is continuously refreshed with real-time, real-world information. To allow users to process and manipulate information seamlessly between the real and digital spaces, novel technologies must be developed. These include smart interfaces, new augmented realities, efficient storage and data management and dissemination techniques. In this paper, we first discuss some promising co-space applications. These applications offer experiences and opportunities that neither of the spaces can realize on its own. We then argue that the database community has much to offer to this field. Finally, we present several challenges that we, as a community, can contribute towards managing the Metaverse.
Enhancing Balanced Graph Edge Partition with Effective Local Search
Dec 17, 2020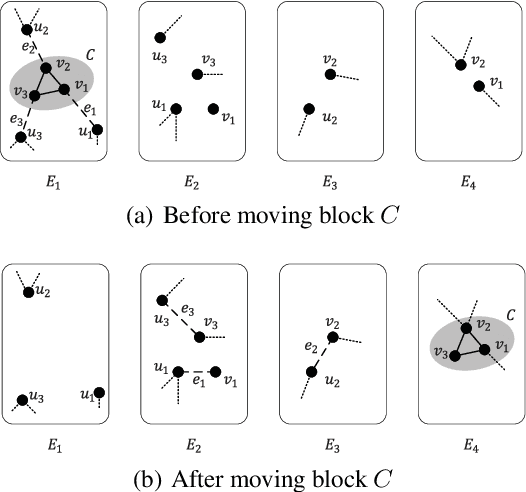
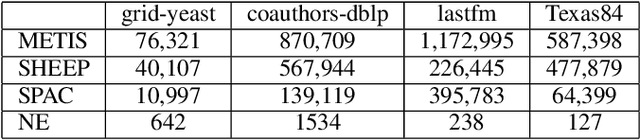
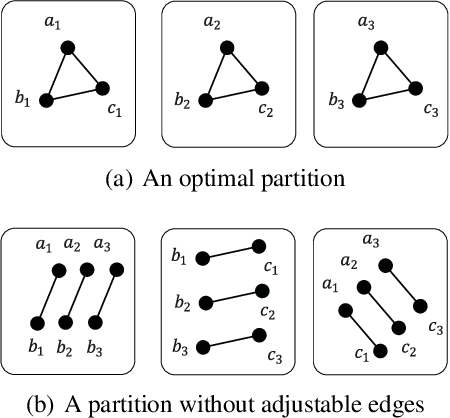
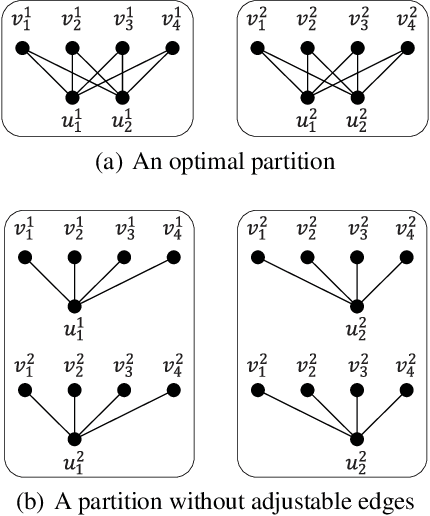
Graph partition is a key component to achieve workload balance and reduce job completion time in parallel graph processing systems. Among the various partition strategies, edge partition has demonstrated more promising performance in power-law graphs than vertex partition and thereby has been more widely adopted as the default partition strategy by existing graph systems. The graph edge partition problem, which is to split the edge set into multiple balanced parts to minimize the total number of copied vertices, has been widely studied from the view of optimization and algorithms. In this paper, we study local search algorithms for this problem to further improve the partition results from existing methods. More specifically, we propose two novel concepts, namely adjustable edges and blocks. Based on these, we develop a greedy heuristic as well as an improved search algorithm utilizing the property of the max-flow model. To evaluate the performance of our algorithms, we first provide adequate theoretical analysis in terms of the approximation quality. We significantly improve the previously known approximation ratio for this problem. Then we conduct extensive experiments on a large number of benchmark datasets and state-of-the-art edge partition strategies. The results show that our proposed local search framework can further improve the quality of graph partition by a wide margin.
Efficient Sampling Algorithms for Approximate Temporal Motif Counting (Extended Version)
Jul 28, 2020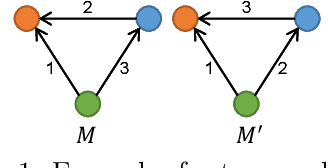

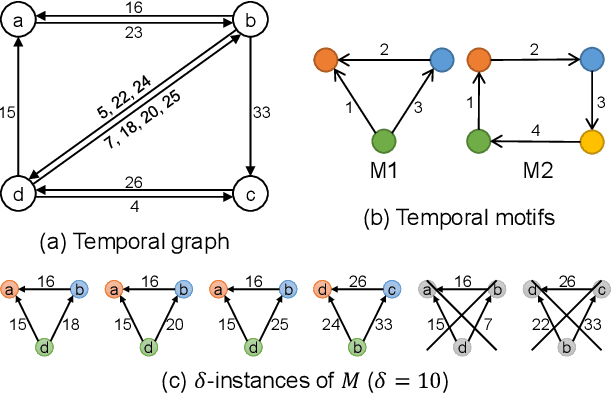
A great variety of complex systems ranging from user interactions in communication networks to transactions in financial markets can be modeled as temporal graphs, which consist of a set of vertices and a series of timestamped and directed edges. Temporal motifs in temporal graphs are generalized from subgraph patterns in static graphs which take into account edge orderings and durations in addition to structures. Counting the number of occurrences of temporal motifs is a fundamental problem for temporal network analysis. However, existing methods either cannot support temporal motifs or suffer from performance issues. In this paper, we focus on approximate temporal motif counting via random sampling. We first propose a generic edge sampling (ES) algorithm for estimating the number of instances of any temporal motif. Furthermore, we devise an improved EWS algorithm that hybridizes edge sampling with wedge sampling for counting temporal motifs with 3 vertices and 3 edges. We provide comprehensive analyses of the theoretical bounds and complexities of our proposed algorithms. Finally, we conduct extensive experiments on several real-world datasets, and the results show that our ES and EWS algorithms have higher efficiency, better accuracy, and greater scalability than the state-of-the-art sampling method for temporal motif counting.
Database Meets Deep Learning: Challenges and Opportunities
Jun 21, 2019

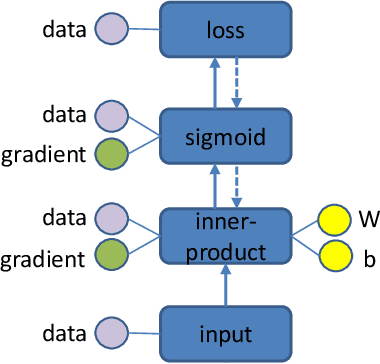
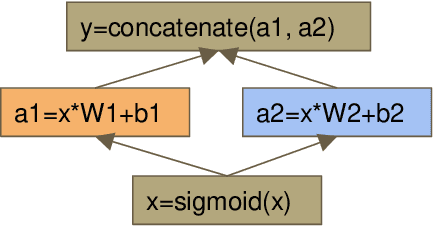
Deep learning has recently become very popular on account of its incredible success in many complex data-driven applications, such as image classification and speech recognition. The database community has worked on data-driven applications for many years, and therefore should be playing a lead role in supporting this new wave. However, databases and deep learning are different in terms of both techniques and applications. In this paper, we discuss research problems at the intersection of the two fields. In particular, we discuss possible improvements for deep learning systems from a database perspective, and analyze database applications that may benefit from deep learning techniques.
* The previous version of this paper has appeared in SIGMOD Record. In this version, we extend it to include the recent developments in this field and references to recent work
Coresets for Minimum Enclosing Balls over Sliding Windows
May 10, 2019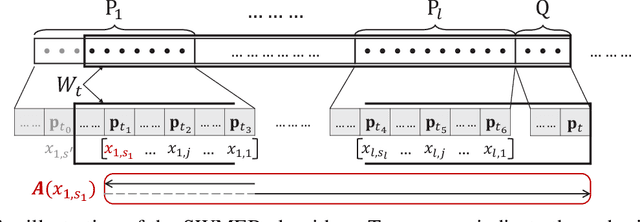
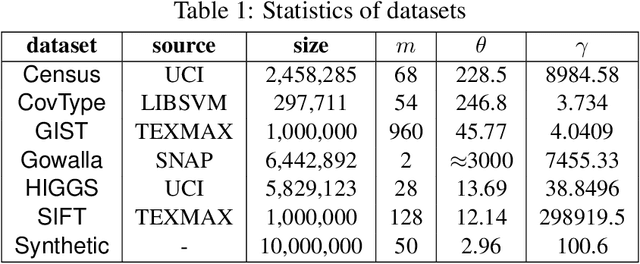
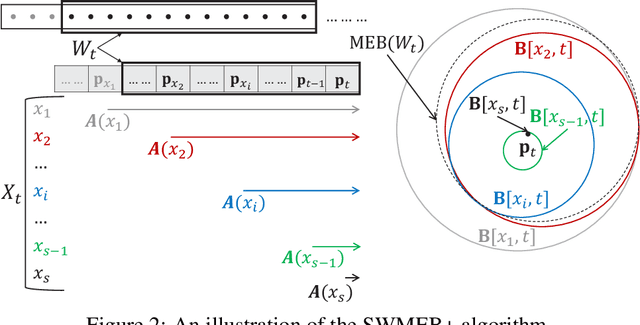
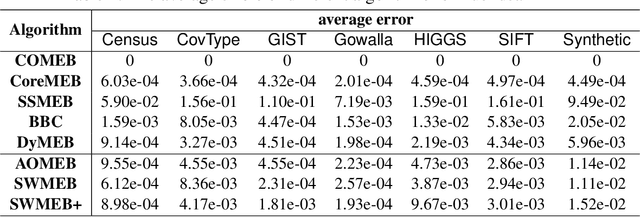
\emph{Coresets} are important tools to generate concise summaries of massive datasets for approximate analysis. A coreset is a small subset of points extracted from the original point set such that certain geometric properties are preserved with provable guarantees. This paper investigates the problem of maintaining a coreset to preserve the minimum enclosing ball (MEB) for a sliding window of points that are continuously updated in a data stream. Although the problem has been extensively studied in batch and append-only streaming settings, no efficient sliding-window solution is available yet. In this work, we first introduce an algorithm, called AOMEB, to build a coreset for MEB in an append-only stream. AOMEB improves the practical performance of the state-of-the-art algorithm while having the same approximation ratio. Furthermore, using AOMEB as a building block, we propose two novel algorithms, namely SWMEB and SWMEB+, to maintain coresets for MEB over the sliding window with constant approximation ratios. The proposed algorithms also support coresets for MEB in a reproducing kernel Hilbert space (RKHS). Finally, extensive experiments on real-world and synthetic datasets demonstrate that SWMEB and SWMEB+ achieve speedups of up to four orders of magnitude over the state-of-the-art batch algorithm while providing coresets for MEB with rather small errors compared to the optimal ones.
Efficient Representative Subset Selection over Sliding Windows
Sep 03, 2018
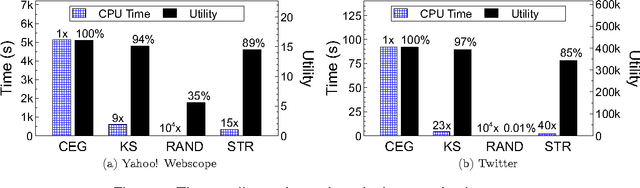
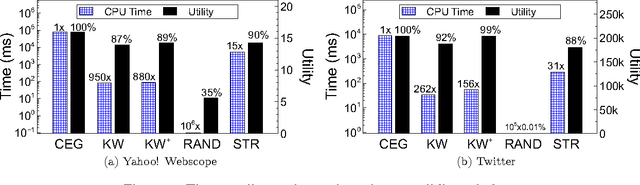
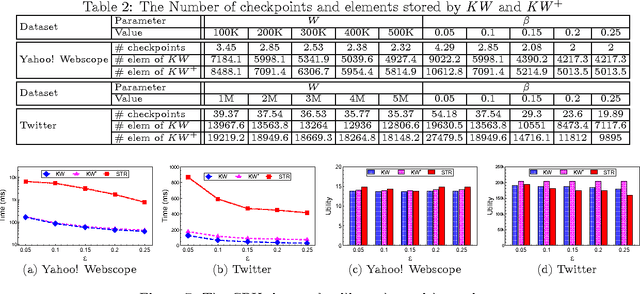
Representative subset selection (RSS) is an important tool for users to draw insights from massive datasets. Existing literature models RSS as the submodular maximization problem to capture the "diminishing returns" property of the representativeness of selected subsets, but often only has a single constraint (e.g., cardinality), which limits its applications in many real-world problems. To capture the data recency issue and support different types of constraints, we formulate dynamic RSS in data streams as maximizing submodular functions subject to general $d$-knapsack constraints (SMDK) over sliding windows. We propose a \textsc{KnapWindow} framework (KW) for SMDK. KW utilizes the \textsc{KnapStream} algorithm (KS) for SMDK in append-only streams as a subroutine. It maintains a sequence of checkpoints and KS instances over the sliding window. Theoretically, KW is $\frac{1-\varepsilon}{1+d}$-approximate for SMDK. Furthermore, we propose a \textsc{KnapWindowPlus} framework (KW$^{+}$) to improve upon KW. KW$^{+}$ builds an index \textsc{SubKnapChk} to manage the checkpoints and KS instances. \textsc{SubKnapChk} deletes a checkpoint whenever it can be approximated by its successors. By keeping much fewer checkpoints, KW$^{+}$ achieves higher efficiency than KW while still guaranteeing a $\frac{1-\varepsilon'}{2+2d}$-approximate solution for SMDK. Finally, we evaluate the efficiency and solution quality of KW and KW$^{+}$ in real-world datasets. The experimental results demonstrate that KW achieves more than two orders of magnitude speedups over the batch baseline and preserves high-quality solutions for SMDK over sliding windows. KW$^{+}$ further runs 5-10 times faster than KW while providing solutions with equivalent or even better utilities.
Deep Learning At Scale and At Ease
Mar 25, 2016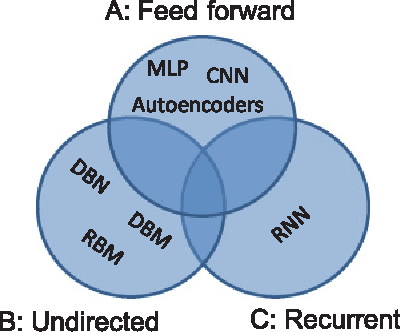
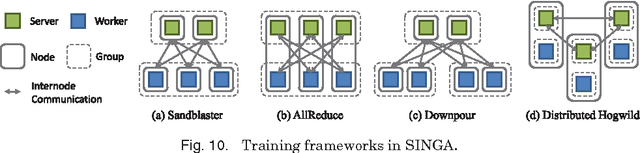
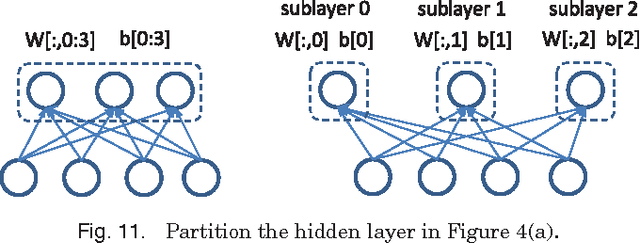
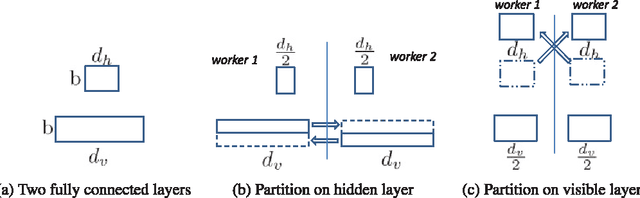
Recently, deep learning techniques have enjoyed success in various multimedia applications, such as image classification and multi-modal data analysis. Large deep learning models are developed for learning rich representations of complex data. There are two challenges to overcome before deep learning can be widely adopted in multimedia and other applications. One is usability, namely the implementation of different models and training algorithms must be done by non-experts without much effort especially when the model is large and complex. The other is scalability, that is the deep learning system must be able to provision for a huge demand of computing resources for training large models with massive datasets. To address these two challenges, in this paper, we design a distributed deep learning platform called SINGA which has an intuitive programming model based on the common layer abstraction of deep learning models. Good scalability is achieved through flexible distributed training architecture and specific optimization techniques. SINGA runs on GPUs as well as on CPUs, and we show that it outperforms many other state-of-the-art deep learning systems. Our experience with developing and training deep learning models for real-life multimedia applications in SINGA shows that the platform is both usable and scalable.