 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Analytic Classifiers with Associative Drift Compensation for Class-Incremental Learning of Vision Transformers
Jan 29, 2026Class-incremental learning (CIL) with Vision Transformers (ViTs) faces a major computational bottleneck during the classifier reconstruction phase, where most existing methods rely on costly iterative stochastic gradient descent (SGD). We observe that analytic Regularized Gaussian Discriminant Analysis (RGDA) provides a Bayes-optimal alternative with accuracy comparable to SGD-based classifiers; however, its quadratic inference complexity limits its use in large-scale CIL scenarios. To overcome this, we propose Low-Rank Factorized RGDA (LR-RGDA), a scalable classifier that combines RGDA's expressivity with the efficiency of linear classifiers. By exploiting the low-rank structure of the covariance via the Woodbury matrix identity, LR-RGDA decomposes the discriminant function into a global affine term refined by a low-rank quadratic perturbation, reducing the inference complexity from $\mathcal{O}(Cd^2)$ to $\mathcal{O}(d^2 + Crd^2)$, where $C$ is the class number, $d$ the feature dimension, and $r \ll d$ the subspace rank. To mitigate representation drift caused by backbone updates, we further introduce Hopfield-based Distribution Compensator (HopDC), a training-free mechanism that uses modern continuous Hopfield Networks to recalibrate historical class statistics through associative memory dynamics on unlabeled anchors, accompanied by a theoretical bound on the estimation error. Extensive experiments on diverse CIL benchmarks demonstrate that our framework achieves state-of-the-art performance, providing a scalable solution for large-scale class-incremental learning with ViTs. Code: https://github.com/raoxuan98-hash/lr_rgda_hopdc.
Compensating Distribution Drifts in Class-incremental Learning of Pre-trained Vision Transformers
Nov 13, 2025



Recent advances have shown that sequential fine-tuning (SeqFT) of pre-trained vision transformers (ViTs), followed by classifier refinement using approximate distributions of class features, can be an effective strategy for class-incremental learning (CIL). However, this approach is susceptible to distribution drift, caused by the sequential optimization of shared backbone parameters. This results in a mismatch between the distributions of the previously learned classes and that of the updater model, ultimately degrading the effectiveness of classifier performance over time. To address this issue, we introduce a latent space transition operator and propose Sequential Learning with Drift Compensation (SLDC). SLDC aims to align feature distributions across tasks to mitigate the impact of drift. First, we present a linear variant of SLDC, which learns a linear operator by solving a regularized least-squares problem that maps features before and after fine-tuning. Next, we extend this with a weakly nonlinear SLDC variant, which assumes that the ideal transition operator lies between purely linear and fully nonlinear transformations. This is implemented using learnable, weakly nonlinear mappings that balance flexibility and generalization. To further reduce representation drift, we apply knowledge distillation (KD) in both algorithmic variants. Extensive experiments on standard CIL benchmarks demonstrate that SLDC significantly improves the performance of SeqFT. Notably, by combining KD to address representation drift with SLDC to compensate distribution drift, SeqFT achieves performance comparable to joint training across all evaluated datasets. Code: https://github.com/raoxuan98-hash/sldc.git.
Selection and Exploitation of High-Quality Knowledge from Large Language Models for Recommendation
Aug 10, 2025In recent years, there has been growing interest in leveraging the impressive generalization capabilities and reasoning ability of large language models (LLMs) to improve the performance of recommenders. With this operation, recommenders can access and learn the additional world knowledge and reasoning information via LLMs. However, in general, for different users and items, the world knowledge derived from LLMs suffers from issues of hallucination, content redundant, and information homogenization. Directly feeding the generated response embeddings into the recommendation model can lead to unavoidable performance deterioration. To address these challenges, we propose a Knowledge Selection \& Exploitation Recommendation (KSER) framework, which effectively select and extracts the high-quality knowledge from LLMs. The framework consists of two key components: a knowledge filtering module and a embedding spaces alignment module. In the knowledge filtering module, a Embedding Selection Filter Network (ESFNet) is designed to assign adaptive weights to different knowledge chunks in different knowledge fields. In the space alignment module, an attention-based architecture is proposed to align the semantic embeddings from LLMs with the feature space used to train the recommendation models. In addition, two training strategies--\textbf{all-parameters training} and \textbf{extractor-only training}--are proposed to flexibly adapt to different downstream tasks and application scenarios, where the extractor-only training strategy offers a novel perspective on knowledge-augmented recommendation. Experimental results validate the necessity and effectiveness of both the knowledge filtering and alignment modules, and further demonstrate the efficiency and effectiveness of the extractor-only training strategy.
MoBE: Mixture-of-Basis-Experts for Compressing MoE-based LLMs
Aug 07, 2025The Mixture-of-Experts (MoE) architecture has become a predominant paradigm for scaling large language models (LLMs). Despite offering strong performance and computational efficiency, large MoE-based LLMs like DeepSeek-V3-0324 and Kimi-K2-Instruct present serious challenges due to substantial memory requirements in deployment. While recent works have explored MoE compression to address this issue, existing methods often suffer from considerable accuracy drops (e.g., 7-14% relatively) even at modest compression rates. This paper introduces a novel Mixture-of-Basis-Experts (MoBE) method that achieves model compression while incurring minimal accuracy drops. Specifically, each up/gate matrix in an expert is decomposed via a rank decomposition as W = AB, where matrix A is unique to each expert. The relatively larger matrix B is further re-parameterized as a linear combination of basis matrices {Bi} shared across all experts within a given MoE layer. The factorization is learned by minimizing the reconstruction error relative to the original weight matrices. Experiments demonstrate that MoBE achieves notably lower accuracy drops compared to prior works. For instance, MoBE can reduce the parameter counts of Qwen3-235B-A22B-2507, DeepSeek-V3-0324 (671B) and Kimi-K2-Instruct (1T) by 24%-30% with only 1%-2% accuracy drop (about 2% drops when measured relatively).
Information Maximization via Variational Autoencoders for Cross-Domain Recommendation
May 31, 2024



Cross-Domain Sequential Recommendation (CDSR) methods aim to address the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR methods typically rely on overlapping users, designing complex cross-domain modules to capture users' latent interests that can propagate across different domains. However, their propagated informative information is limited to the overlapping users and the users who have rich historical behavior records. As a result, these methods often underperform in real-world scenarios, where most users are non-overlapping (cold-start) and long-tailed. In this research, we introduce a new CDSR framework named Information Maximization Variational Autoencoder (\textbf{\texttt{IM-VAE}}). Here, we suggest using a Pseudo-Sequence Generator to enhance the user's interaction history input for downstream fine-grained CDSR models to alleviate the cold-start issues. We also propose a Generative Recommendation Framework combined with three regularizers inspired by the mutual information maximization (MIM) theory \cite{mcgill1954multivariate} to capture the semantic differences between a user's interests shared across domains and those specific to certain domains, as well as address the informational gap between a user's actual interaction sequences and the pseudo-sequences generated. To the best of our knowledge, this paper is the first CDSR work that considers the information disentanglement and denoising of pseudo-sequences in the open-world recommendation scenario. Empirical experiments illustrate that \texttt{IM-VAE} outperforms the state-of-the-art approaches on two real-world cross-domain datasets on all sorts of users, including cold-start and tailed users, demonstrating the effectiveness of \texttt{IM-VAE} in open-world recommendation.
Fine-Grained Dynamic Framework for Bias-Variance Joint Optimization on Data Missing Not at Random
May 24, 2024



In most practical applications such as recommendation systems, display advertising, and so forth, the collected data often contains missing values and those missing values are generally missing-not-at-random, which deteriorates the prediction performance of models. Some existing estimators and regularizers attempt to achieve unbiased estimation to improve the predictive performance. However, variances and generalization bound of these methods are generally unbounded when the propensity scores tend to zero, compromising their stability and robustness. In this paper, we first theoretically reveal that limitations of regularization techniques. Besides, we further illustrate that, for more general estimators, unbiasedness will inevitably lead to unbounded variance. These general laws inspire us that the estimator designs is not merely about eliminating bias, reducing variance, or simply achieve a bias-variance trade-off. Instead, it involves a quantitative joint optimization of bias and variance. Then, we develop a systematic fine-grained dynamic learning framework to jointly optimize bias and variance, which adaptively selects an appropriate estimator for each user-item pair according to the predefined objective function. With this operation, the generalization bounds and variances of models are reduced and bounded with theoretical guarantees. Extensive experiments are conducted to verify the theoretical results and the effectiveness of the proposed dynamic learning framework.
Towards Open-world Cross-Domain Sequential Recommendation: A Model-Agnostic Contrastive Denoising Approach
Nov 23, 2023



Cross-domain sequential recommendation (CDSR) aims to address the data sparsity problems that exist in traditional sequential recommendation (SR) systems. The existing approaches aim to design a specific cross-domain unit that can transfer and propagate information across multiple domains by relying on overlapping users with abundant behaviors. However, in real-world recommender systems, CDSR scenarios usually consist of a majority of long-tailed users with sparse behaviors and cold-start users who only exist in one domain. This leads to a drop in the performance of existing CDSR methods in the real-world industry platform. Therefore, improving the consistency and effectiveness of models in open-world CDSR scenarios is crucial for constructing CDSR models (\textit{1st} CH). Recently, some SR approaches have utilized auxiliary behaviors to complement the information for long-tailed users. However, these multi-behavior SR methods cannot deliver promising performance in CDSR, as they overlook the semantic gap between target and auxiliary behaviors, as well as user interest deviation across domains (\textit{2nd} CH).
Rethinking Cross-Domain Sequential Recommendation under Open-World Assumptions
Nov 08, 2023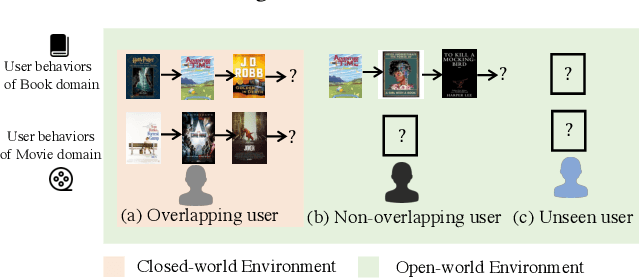
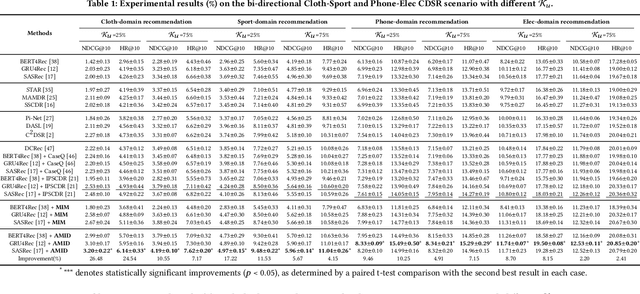
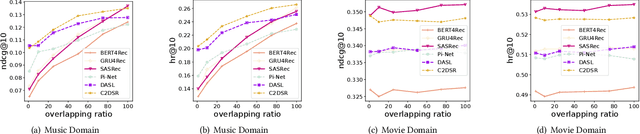
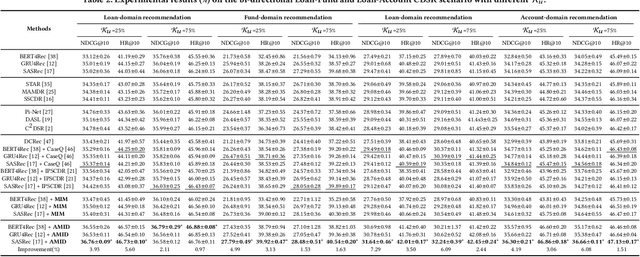
Cross-Domain Sequential Recommendation (CDSR) methods aim to tackle the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR works design their elaborate structures relying on overlapping users to propagate the cross-domain information. However, current CDSR methods make closed-world assumptions, assuming fully overlapping users across multiple domains and that the data distribution remains unchanged from the training environment to the test environment. As a result, these methods typically result in lower performance on online real-world platforms due to the data distribution shifts. To address these challenges under open-world assumptions, we design an \textbf{A}daptive \textbf{M}ulti-\textbf{I}nterest \textbf{D}ebiasing framework for cross-domain sequential recommendation (\textbf{AMID}), which consists of a multi-interest information module (\textbf{MIM}) and a doubly robust estimator (\textbf{DRE}). Our framework is adaptive for open-world environments and can improve the model of most off-the-shelf single-domain sequential backbone models for CDSR. Our MIM establishes interest groups that consider both overlapping and non-overlapping users, allowing us to effectively explore user intent and explicit interest. To alleviate biases across multiple domains, we developed the DRE for the CDSR methods. We also provide a theoretical analysis that demonstrates the superiority of our proposed estimator in terms of bias and tail bound, compared to the IPS estimator used in previous work.
Neural Node Matching for Multi-Target Cross Domain Recommendation
Feb 12, 2023



Multi-Target Cross Domain Recommendation(CDR) has attracted a surge of interest recently, which intends to improve the recommendation performance in multiple domains (or systems) simultaneously. Most existing multi-target CDR frameworks primarily rely on the existence of the majority of overlapped users across domains. However, general practical CDR scenarios cannot meet the strictly overlapping requirements and only share a small margin of common users across domains}. Additionally, the majority of users have quite a few historical behaviors in such small-overlapping CDR scenarios}. To tackle the aforementioned issues, we propose a simple-yet-effective neural node matching based framework for more general CDR settings, i.e., only (few) partially overlapped users exist across domains and most overlapped as well as non-overlapped users do have sparse interactions. The present framework} mainly contains two modules: (i) intra-to-inter node matching module, and (ii) intra node complementing module. Concretely, the first module conducts intra-knowledge fusion within each domain and subsequent inter-knowledge fusion across domains by fully connected user-user homogeneous graph information aggregating.
* 13pages
Adaptive Pattern Extraction Multi-Task Learning for Multi-Step Conversion Estimations
Jan 23, 2023Multi-task learning (MTL) has been successfully used in many real-world applications, which aims to simultaneously solve multiple tasks with a single model. The general idea of multi-task learning is designing kinds of global parameter sharing mechanism and task-specific feature extractor to improve the performance of all tasks. However, challenge still remains in balancing the trade-off of various tasks since model performance is sensitive to the relationships between them. Less correlated or even conflict tasks will deteriorate the performance by introducing unhelpful or negative information. Therefore, it is important to efficiently exploit and learn fine-grained feature representation corresponding to each task. In this paper, we propose an Adaptive Pattern Extraction Multi-task (APEM) framework, which is adaptive and flexible for large-scale industrial application. APEM is able to fully utilize the feature information by learning the interactions between the input feature fields and extracted corresponding tasks-specific information. We first introduce a DeepAuto Group Transformer module to automatically and efficiently enhance the feature expressivity with a modified set attention mechanism and a Squeeze-and-Excitation operation. Second, explicit Pattern Selector is introduced to further enable selectively feature representation learning by adaptive task-indicator vectors. Empirical evaluations show that APEM outperforms the state-of-the-art MTL methods on public and real-world financial services datasets. More importantly, we explore the online performance of APEM in a real industrial-level recommendation scenario.