 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Large Language Models with Graphical Session-Based Recommendation
Feb 26, 2024

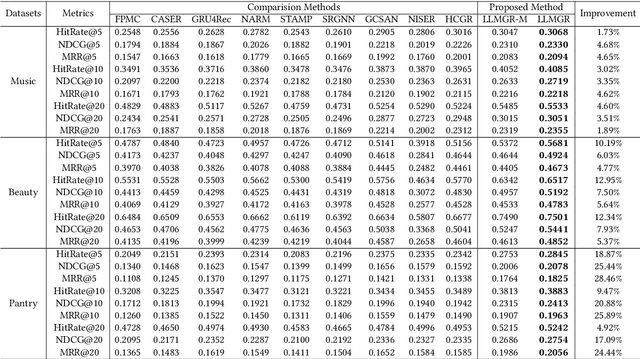
With the rapid development of Large Language Models (LLMs), various explorations have arisen to utilize LLMs capability of context understanding on recommender systems. While pioneering strategies have primarily transformed traditional recommendation tasks into challenges of natural language generation, there has been a relative scarcity of exploration in the domain of session-based recommendation (SBR) due to its specificity. SBR has been primarily dominated by Graph Neural Networks, which have achieved many successful outcomes due to their ability to capture both the implicit and explicit relationships between adjacent behaviors. The structural nature of graphs contrasts with the essence of natural language, posing a significant adaptation gap for LLMs. In this paper, we introduce large language models with graphical Session-Based recommendation, named LLMGR, an effective framework that bridges the aforementioned gap by harmoniously integrating LLMs with Graph Neural Networks (GNNs) for SBR tasks. This integration seeks to leverage the complementary strengths of LLMs in natural language understanding and GNNs in relational data processing, leading to a more powerful session-based recommender system that can understand and recommend items within a session. Moreover, to endow the LLM with the capability to empower SBR tasks, we design a series of prompts for both auxiliary and major instruction tuning tasks. These prompts are crafted to assist the LLM in understanding graph-structured data and align textual information with nodes, effectively translating nuanced user interactions into a format that can be understood and utilized by LLM architectures. Extensive experiments on three real-world datasets demonstrate that LLMGR outperforms several competitive baselines, indicating its effectiveness in enhancing SBR tasks and its potential as a research direction for future exploration.
Towards Open-world Cross-Domain Sequential Recommendation: A Model-Agnostic Contrastive Denoising Approach
Nov 23, 2023



Cross-domain sequential recommendation (CDSR) aims to address the data sparsity problems that exist in traditional sequential recommendation (SR) systems. The existing approaches aim to design a specific cross-domain unit that can transfer and propagate information across multiple domains by relying on overlapping users with abundant behaviors. However, in real-world recommender systems, CDSR scenarios usually consist of a majority of long-tailed users with sparse behaviors and cold-start users who only exist in one domain. This leads to a drop in the performance of existing CDSR methods in the real-world industry platform. Therefore, improving the consistency and effectiveness of models in open-world CDSR scenarios is crucial for constructing CDSR models (\textit{1st} CH). Recently, some SR approaches have utilized auxiliary behaviors to complement the information for long-tailed users. However, these multi-behavior SR methods cannot deliver promising performance in CDSR, as they overlook the semantic gap between target and auxiliary behaviors, as well as user interest deviation across domains (\textit{2nd} CH).
Adaptive Portfolio by Solving Multi-armed Bandit via Thompson Sampling
Nov 14, 2019
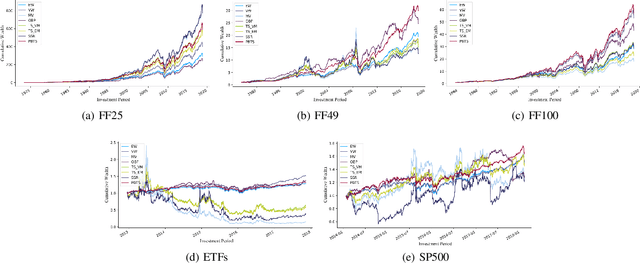

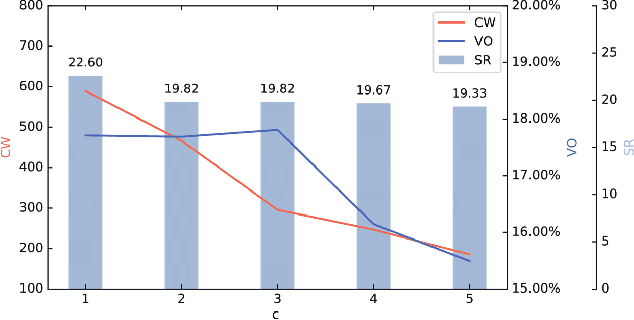
As the cornerstone of modern portfolio theory, Markowitz's mean-variance optimization is considered a major model adopted in portfolio management. However, due to the difficulty of estimating its parameters, it cannot be applied to all periods. In some cases, naive strategies such as Equally-weighted and Value-weighted portfolios can even get better performance. Under these circumstances, we can use multiple classic strategies as multiple strategic arms in multi-armed bandit to naturally establish a connection with the portfolio selection problem. This can also help to maximize the rewards in the bandit algorithm by the trade-off between exploration and exploitation. In this paper, we present a portfolio bandit strategy through Thompson sampling which aims to make online portfolio choices by effectively exploiting the performances among multiple arms. Also, by constructing multiple strategic arms, we can obtain the optimal investment portfolio to adapt different investment periods. Moreover, we devise a novel reward function based on users' different investment risk preferences, which can be adaptive to various investment styles. Our experimental results demonstrate that our proposed portfolio strategy has marked superiority across representative real-world market datasets in terms of extensive evaluation criteria.