 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKU-Bench: A Multimodal Update Benchmark for Diverse Visual Knowledge
Mar 16, 2026As real-world knowledge continues to evolve, the parametric knowledge acquired by multimodal models during pretraining becomes increasingly difficult to remain consistent with real-world knowledge. Existing research on multimodal knowledge updating focuses only on learning previously unknown knowledge, while overlooking the need to update knowledge that the model has already mastered but that later changes; moreover, evaluation is limited to the same modality, lacking a systematic analysis of cross-modal consistency. To address these issues, this paper proposes MMKU-Bench, a comprehensive evaluation benchmark for multimodal knowledge updating, which contains over 25k knowledge instances and more than 49k images, covering two scenarios, updated knowledge and unknown knowledge, thereby enabling comparative analysis of learning across different knowledge types. On this benchmark, we evaluate a variety of representative approaches, including supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and knowledge editing (KE). Experimental results show that SFT and RLHF are prone to catastrophic forgetting, while KE better preserve general capabilities but exhibit clear limitations in continual updating. Overall, MMKU-Bench provides a reliable and comprehensive evaluation benchmark for multimodal knowledge updating, advancing progress in this field.
Dynamic Graph Condensation
Jun 16, 2025Recent research on deep graph learning has shifted from static to dynamic graphs, motivated by the evolving behaviors observed in complex real-world systems. However, the temporal extension in dynamic graphs poses significant data efficiency challenges, including increased data volume, high spatiotemporal redundancy, and reliance on costly dynamic graph neural networks (DGNNs). To alleviate the concerns, we pioneer the study of dynamic graph condensation (DGC), which aims to substantially reduce the scale of dynamic graphs for data-efficient DGNN training. Accordingly, we propose DyGC, a novel framework that condenses the real dynamic graph into a compact version while faithfully preserving the inherent spatiotemporal characteristics. Specifically, to endow synthetic graphs with realistic evolving structures, a novel spiking structure generation mechanism is introduced. It draws on the dynamic behavior of spiking neurons to model temporally-aware connectivity in dynamic graphs. Given the tightly coupled spatiotemporal dependencies, DyGC proposes a tailored distribution matching approach that first constructs a semantically rich state evolving field for dynamic graphs, and then performs fine-grained spatiotemporal state alignment to guide the optimization of the condensed graph. Experiments across multiple dynamic graph datasets and representative DGNN architectures demonstrate the effectiveness of DyGC. Notably, our method retains up to 96.2% DGNN performance with only 0.5% of the original graph size, and achieves up to 1846 times training speedup.
FlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024

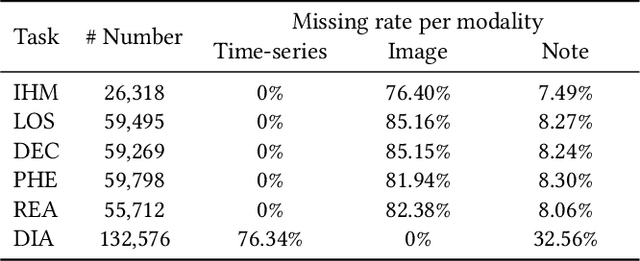
Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.
Discriminative Feature Learning Framework with Gradient Preference for Anomaly Detection
Apr 23, 2022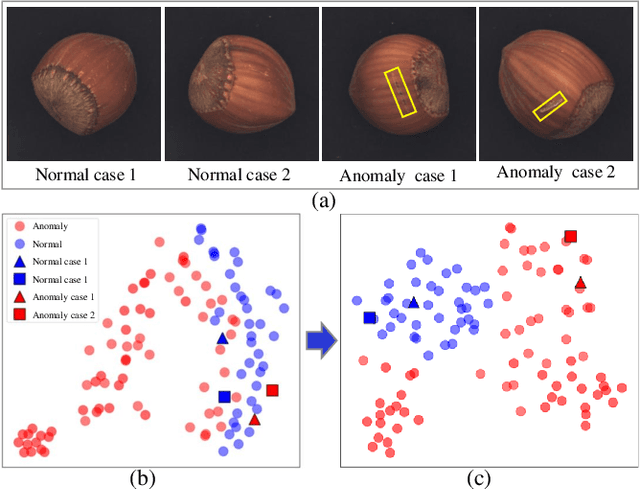
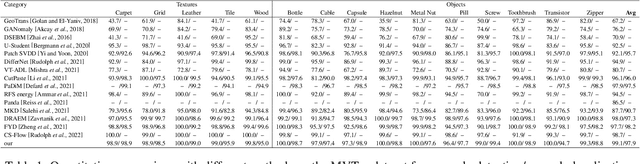
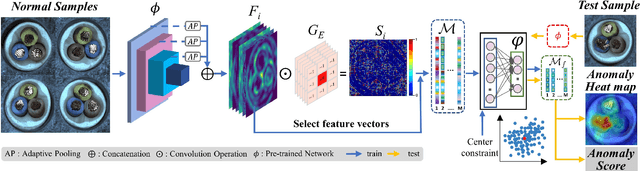
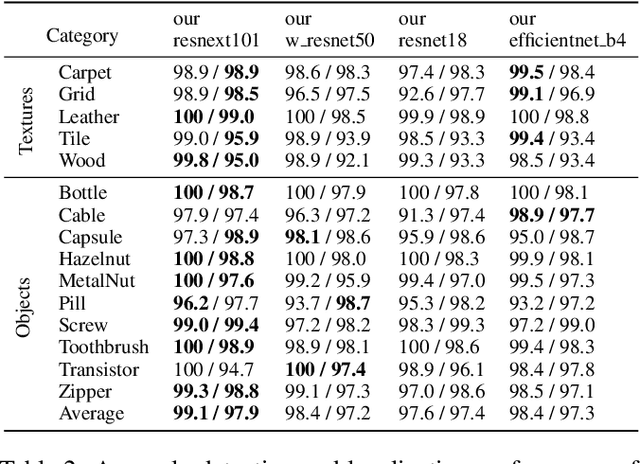
Unsupervised representation learning has been extensively employed in anomaly detection, achieving impressive performance. Extracting valuable feature vectors that can remarkably improve the performance of anomaly detection are essential in unsupervised representation learning. To this end, we propose a novel discriminative feature learning framework with gradient preference for anomaly detection. Specifically, we firstly design a gradient preference based selector to store powerful feature points in space and then construct a feature repository, which alleviate the interference of redundant feature vectors and improve inference efficiency. To overcome the looseness of feature vectors, secondly, we present a discriminative feature learning with center constrain to map the feature repository to a compact subspace, so that the anomalous samples are more distinguishable from the normal ones. Moreover, our method can be easily extended to anomaly localization. Extensive experiments on popular industrial and medical anomaly detection datasets demonstrate our proposed framework can achieve competitive results in both anomaly detection and localization. More important, our method outperforms the state-of-the-art in few shot anomaly detection.