 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Chain Mirror Descent On Data Federation
Paper and Code
Sep 26, 2023


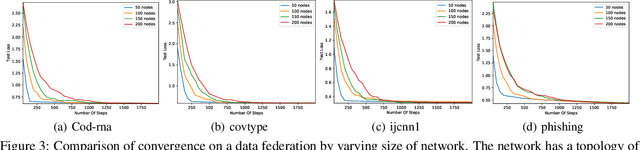
Stochastic optimization methods such as mirror descent have wide applications due to low computational cost. Those methods have been well studied under assumption of the independent and identical distribution, and usually achieve sublinear rate of convergence. However, this assumption may be too strong and unpractical in real application scenarios. Recent researches investigate stochastic gradient descent when instances are sampled from a Markov chain. Unfortunately, few results are known for stochastic mirror descent. In the paper, we propose a new version of stochastic mirror descent termed by MarchOn in the scenario of the federated learning. Given a distributed network, the model iteratively travels from a node to one of its neighbours randomly. Furthermore, we propose a new framework to analyze MarchOn, which yields best rates of convergence for convex, strongly convex, and non-convex loss. Finally, we conduct empirical studies to evaluate the convergence of MarchOn, and validate theoretical results.