 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-UNet-v2: Adaptive Denoising Method and Training Strategy for Medical Image Segmentation with Small Training Data
Sep 07, 2023



Models based on U-like structures have improved the performance of medical image segmentation. However, the single-layer decoder structure of U-Net is too "thin" to exploit enough information, resulting in large semantic differences between the encoder and decoder parts. Things get worse if the number of training sets of data is not sufficiently large, which is common in medical image processing tasks where annotated data are more difficult to obtain than other tasks. Based on this observation, we propose a novel U-Net model named MS-UNet for the medical image segmentation task in this study. Instead of the single-layer U-Net decoder structure used in Swin-UNet and TransUnet, we specifically design a multi-scale nested decoder based on the Swin Transformer for U-Net. The proposed multi-scale nested decoder structure allows the feature mapping between the decoder and encoder to be semantically closer, thus enabling the network to learn more detailed features. In addition, we propose a novel edge loss and a plug-and-play fine-tuning Denoising module, which not only effectively improves the segmentation performance of MS-UNet, but could also be applied to other models individually. Experimental results show that MS-UNet could effectively improve the network performance with more efficient feature learning capability and exhibit more advanced performance, especially in the extreme case with a small amount of training data, and the proposed Edge loss and Denoising module could significantly enhance the segmentation performance of MS-UNet.
Video Abnormal Event Detection by Learning to Complete Visual Cloze Tests
Aug 05, 2021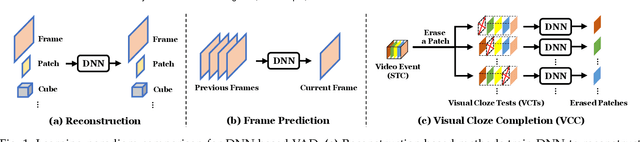
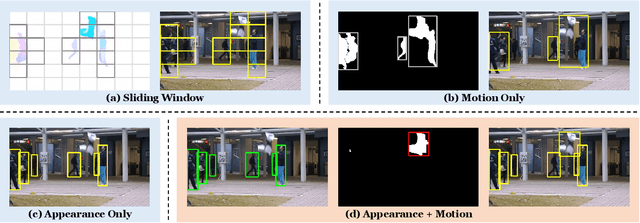
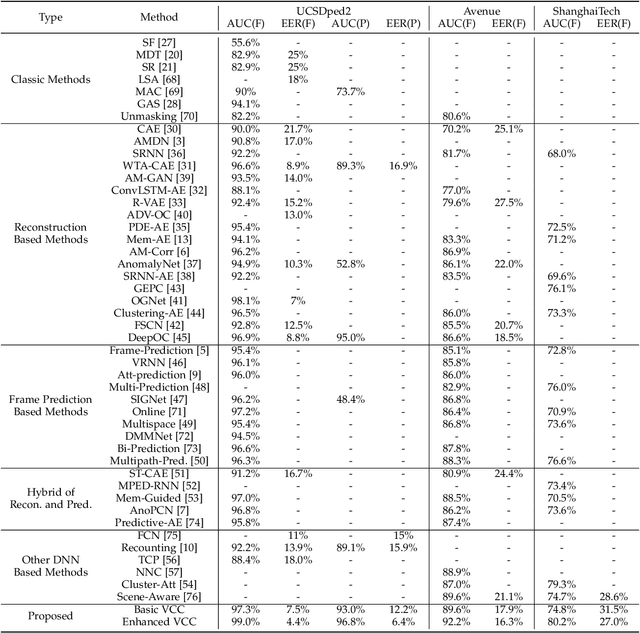
Video abnormal event detection (VAD) is a vital semi-supervised task that requires learning with only roughly labeled normal videos, as anomalies are often practically unavailable. Although deep neural networks (DNNs) enable great progress in VAD, existing solutions typically suffer from two issues: (1) The precise and comprehensive localization of video events is ignored. (2) The video semantics and temporal context are under-explored. To address those issues, we are motivated by the prevalent cloze test in education and propose a novel approach named visual cloze completion (VCC), which performs VAD by learning to complete "visual cloze tests" (VCTs). Specifically, VCC first localizes each video event and encloses it into a spatio-temporal cube (STC). To achieve both precise and comprehensive localization, appearance and motion are used as mutually complementary cues to mark the object region associated with each video event. For each marked region, a normalized patch sequence is extracted from temporally adjacent frames and stacked into the STC. By comparing each patch and the patch sequence of a STC to a visual "word" and "sentence" respectively, we can deliberately erase a certain "word" (patch) to yield a VCT. DNNs are then trained to infer the erased patch by video semantics, so as to complete the VCT. To fully exploit the temporal context, each patch in STC is alternatively erased to create multiple VCTs, and the erased patch's optical flow is also inferred to integrate richer motion clues. Meanwhile, a new DNN architecture is designed as a model-level solution to utilize video semantics and temporal context. Extensive experiments demonstrate that VCC achieves state-of-the-art VAD performance. Our codes and results are open at \url{https://github.com/yuguangnudt/VEC_VAD/tree/VCC}
Sensing Anomalies like Humans: A Hominine Framework to Detect Abnormal Events from Unlabeled Videos
Aug 04, 2021
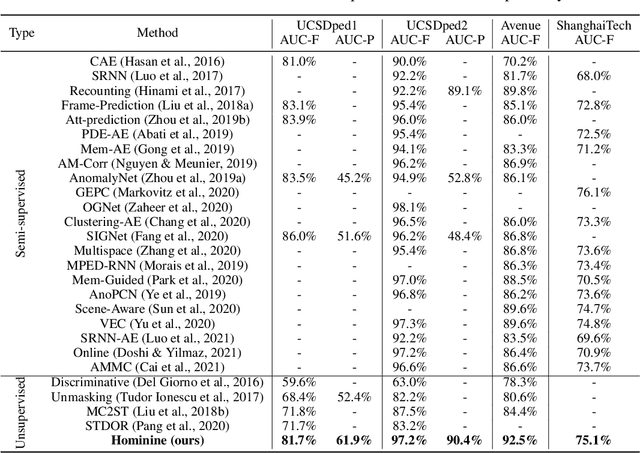
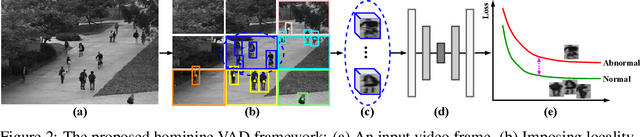

Video anomaly detection (VAD) has constantly been a vital topic in video analysis. As anomalies are often rare, it is typically addressed under a semi-supervised setup, which requires a training set with pure normal videos. To avoid exhausted manual labeling, we are inspired by how humans sense anomalies and propose a hominine framework that enables both unsupervised and end-to-end VAD. The framework is based on two key observations: 1) Human perception is usually local, i.e. focusing on local foreground and its context when sensing anomalies. Thus, we propose to impose locality-awareness by localizing foreground with generic knowledge, and a region localization strategy is designed to exploit local context. 2) Frequently-occurred events will mould humans' definition of normality, which motivates us to devise a surrogate training paradigm. It trains a deep neural network (DNN) to learn a surrogate task with unlabeled videos, and frequently-occurred events will play a dominant role in "moulding" the DNN. In this way, a training loss gap will automatically manifest rarely-seen novel events as anomalies. For implementation, we explore various surrogate tasks as well as both classic and emerging DNN models. Extensive evaluations on commonly-used VAD benchmarks justify the framework's applicability to different surrogate tasks or DNN models, and demonstrate its astonishing effectiveness: It not only outperforms existing unsupervised solutions by a wide margin (8% to 10% AUROC gain), but also achieves comparable or even superior performance to state-of-the-art semi-supervised counterparts.
Multi-view Deep One-class Classification: A Systematic Exploration
Apr 27, 2021
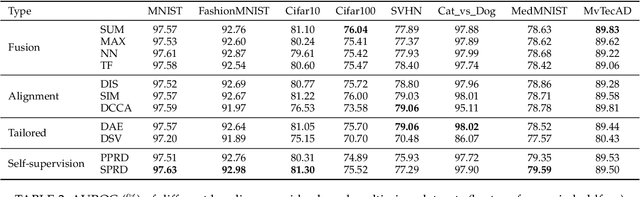
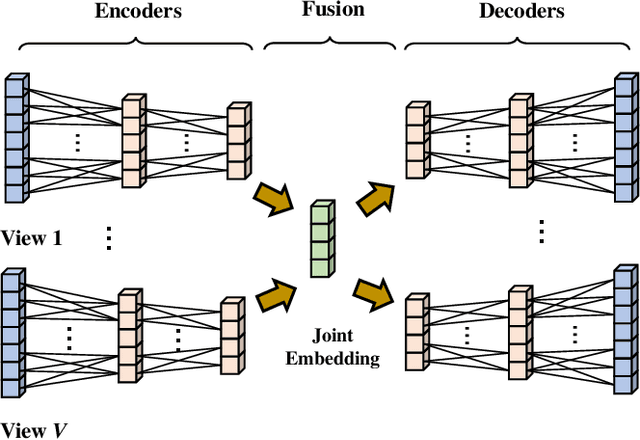
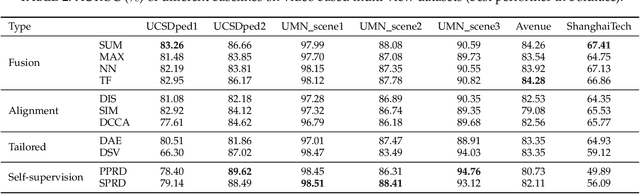
One-class classification (OCC), which models one single positive class and distinguishes it from the negative class, has been a long-standing topic with pivotal application to realms like anomaly detection. As modern society often deals with massive high-dimensional complex data spawned by multiple sources, it is natural to consider OCC from the perspective of multi-view deep learning. However, it has not been discussed by the literature and remains an unexplored topic. Motivated by this blank, this paper makes four-fold contributions: First, to our best knowledge, this is the first work that formally identifies and formulates the multi-view deep OCC problem. Second, we take recent advances in relevant areas into account and systematically devise eleven different baseline solutions for multi-view deep OCC, which lays the foundation for research on multi-view deep OCC. Third, to remedy the problem that limited benchmark datasets are available for multi-view deep OCC, we extensively collect existing public data and process them into more than 30 new multi-view benchmark datasets via multiple means, so as to provide a publicly available evaluation platform for multi-view deep OCC. Finally, by comprehensively evaluating the devised solutions on benchmark datasets, we conduct a thorough analysis on the effectiveness of the designed baselines, and hopefully provide other researchers with beneficial guidance and insight to multi-view deep OCC. Our data and codes are opened at https://github.com/liujiyuan13/MvDOCC-datasets and https://github.com/liujiyuan13/MvDOCC-code respectively to facilitate future research.
Cloze Test Helps: Effective Video Anomaly Detection via Learning to Complete Video Events
Aug 27, 2020
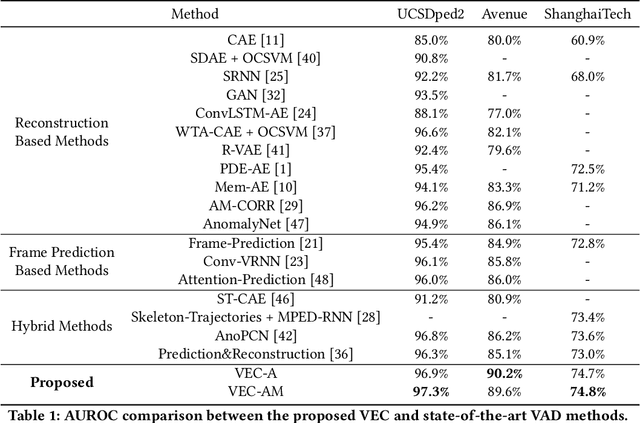
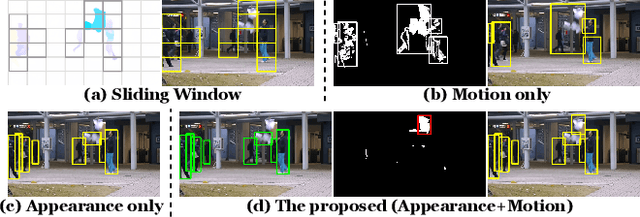

As a vital topic in media content interpretation, video anomaly detection (VAD) has made fruitful progress via deep neural network (DNN). However, existing methods usually follow a reconstruction or frame prediction routine. They suffer from two gaps: (1) They cannot localize video activities in a both precise and comprehensive manner. (2) They lack sufficient abilities to utilize high-level semantics and temporal context information. Inspired by frequently-used cloze test in language study, we propose a brand-new VAD solution named Video Event Completion (VEC) to bridge gaps above: First, we propose a novel pipeline to achieve both precise and comprehensive enclosure of video activities. Appearance and motion are exploited as mutually complimentary cues to localize regions of interest (RoIs). A normalized spatio-temporal cube (STC) is built from each RoI as a video event, which lays the foundation of VEC and serves as a basic processing unit. Second, we encourage DNN to capture high-level semantics by solving a visual cloze test. To build such a visual cloze test, a certain patch of STC is erased to yield an incomplete event (IE). The DNN learns to restore the original video event from the IE by inferring the missing patch. Third, to incorporate richer motion dynamics, another DNN is trained to infer erased patches' optical flow. Finally, two ensemble strategies using different types of IE and modalities are proposed to boost VAD performance, so as to fully exploit the temporal context and modality information for VAD. VEC can consistently outperform state-of-the-art methods by a notable margin (typically 1.5%-5% AUROC) on commonly-used VAD benchmarks. Our codes and results can be verified at github.com/yuguangnudt/VEC_VAD.
Unsupervised Heterogeneous Coupling Learning for Categorical Representation
Jul 21, 2020
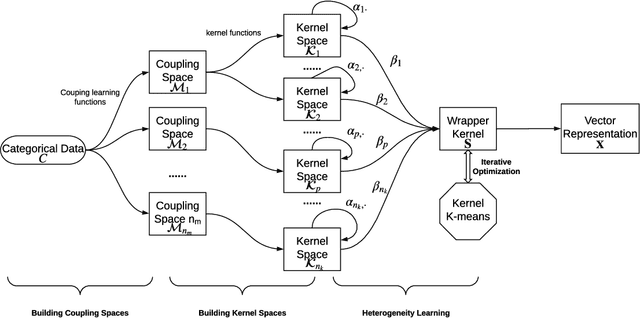

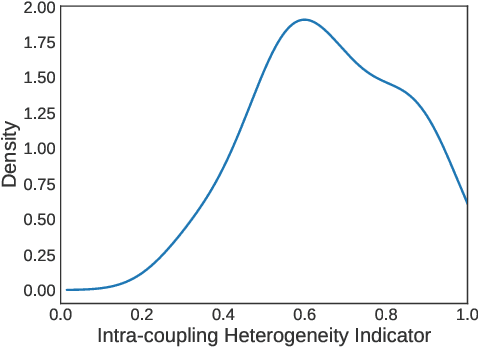
Complex categorical data is often hierarchically coupled with heterogeneous relationships between attributes and attribute values and the couplings between objects. Such value-to-object couplings are heterogeneous with complementary and inconsistent interactions and distributions. Limited research exists on unlabeled categorical data representations, ignores the heterogeneous and hierarchical couplings, underestimates data characteristics and complexities, and overuses redundant information, etc. The deep representation learning of unlabeled categorical data is challenging, overseeing such value-to-object couplings, complementarity and inconsistency, and requiring large data, disentanglement, and high computational power. This work introduces a shallow but powerful UNsupervised heTerogeneous couplIng lEarning (UNTIE) approach for representing coupled categorical data by untying the interactions between couplings and revealing heterogeneous distributions embedded in each type of couplings. UNTIE is efficiently optimized w.r.t. a kernel k-means objective function for unsupervised representation learning of heterogeneous and hierarchical value-to-object couplings. Theoretical analysis shows that UNTIE can represent categorical data with maximal separability while effectively represent heterogeneous couplings and disclose their roles in categorical data. The UNTIE-learned representations make significant performance improvement against the state-of-the-art categorical representations and deep representation models on 25 categorical data sets with diversified characteristics.
Understand Dynamic Regret with Switching Cost for Online Decision Making
Nov 28, 2019
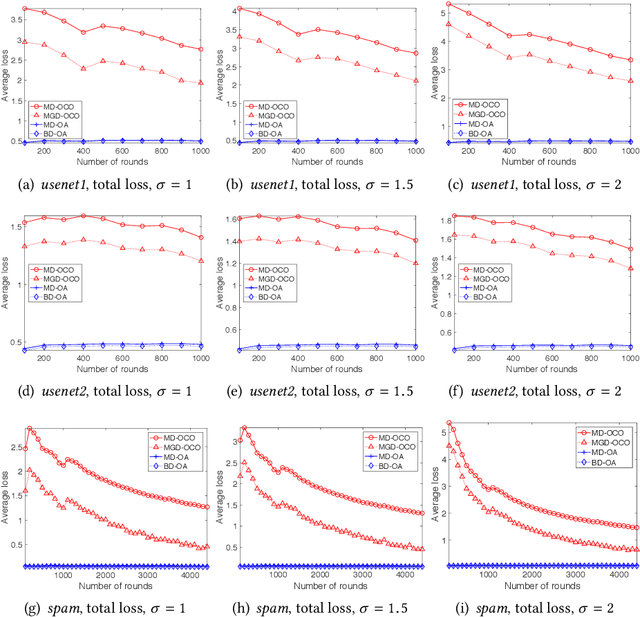
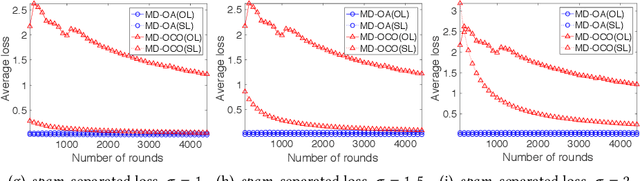
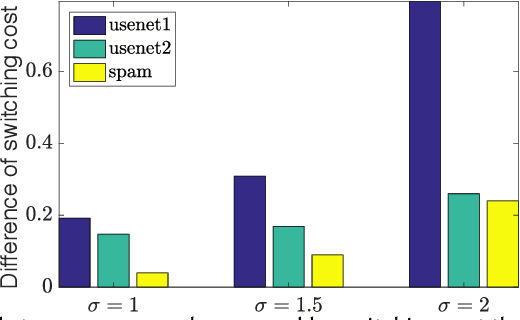
As a metric to measure the performance of an online method, dynamic regret with switching cost has drawn much attention for online decision making problems. Although the sublinear regret has been provided in many previous researches, we still have little knowledge about the relation between the dynamic regret and the switching cost. In the paper, we investigate the relation for two classic online settings: Online Algorithms (OA) and Online Convex Optimization (OCO). We provide a new theoretical analysis framework, which shows an interesting observation, that is, the relation between the switching cost and the dynamic regret is different for settings of OA and OCO. Specifically, the switching cost has significant impact on the dynamic regret in the setting of OA. But, it does not have an impact on the dynamic regret in the setting of OCO. Furthermore, we provide a lower bound of regret for the setting of OCO, which is same with the lower bound in the case of no switching cost. It shows that the switching cost does not change the difficulty of online decision making problems in the setting of OCO.
Simultaneous Clustering and Optimization for Evolving Datasets
Aug 04, 2019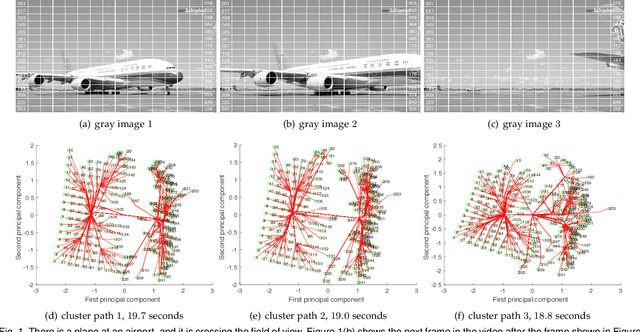

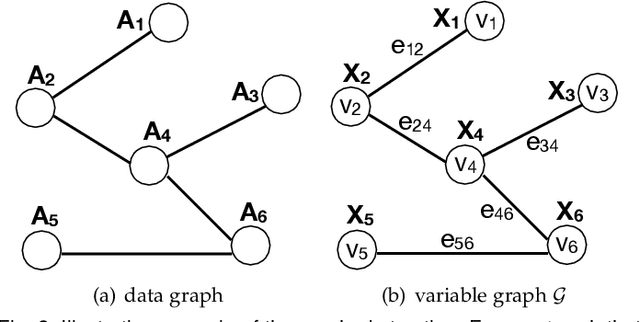

Simultaneous clustering and optimization (SCO) has recently drawn much attention due to its wide range of practical applications. Many methods have been previously proposed to solve this problem and obtain the optimal model. However, when a dataset evolves over time, those existing methods have to update the model frequently to guarantee accuracy; such updating is computationally infeasible. In this paper, we propose a new formulation of SCO to handle evolving datasets. Specifically, we propose a new variant of the alternating direction method of multipliers (ADMM) to solve this problem efficiently. The guarantee of model accuracy is analyzed theoretically for two specific tasks: ridge regression and convex clustering. Extensive empirical studies confirm the effectiveness of our method.
Dynamic Online Gradient Descent with Improved Query Complexity: A Theoretical Revisit
Jan 08, 2019
We provide a new theoretical analysis framework to investigate online gradient descent in the dynamic environment. Comparing with the previous work, the new framework recovers the state-of-the-art dynamic regret, but does not require extra gradient queries for every iteration. Specifically, when functions are $\alpha$ strongly convex and $\beta$ smooth, to achieve the state-of-the-art dynamic regret, the previous work requires $O(\kappa)$ with $\kappa = \frac{\beta}{\alpha}$ queries of gradients at every iteration. But, our framework shows that the query complexity can be improved to be $O(1)$, which does not depend on $\kappa$. The improvement is significant for ill-conditioned problems because that their objective function usually has a large $\kappa$.
Triangle Lasso for Simultaneous Clustering and Optimization in Graph Datasets
Aug 20, 2018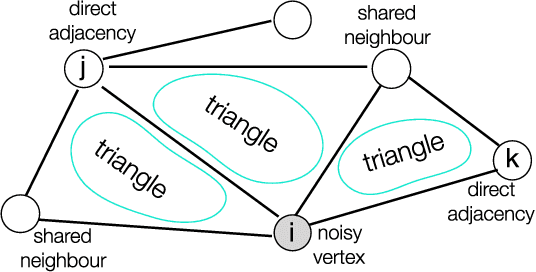

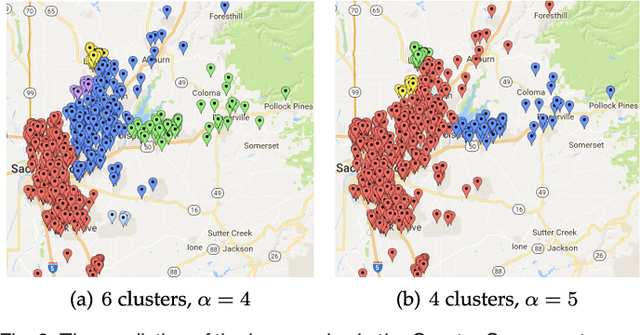
Recently, network lasso has drawn many attentions due to its remarkable performance on simultaneous clustering and optimization. However, it usually suffers from the imperfect data (noise, missing values etc), and yields sub-optimal solutions. The reason is that it finds the similar instances according to their features directly, which is usually impacted by the imperfect data, and thus returns sub-optimal results. In this paper, we propose triangle lasso to avoid its disadvantage. Triangle lasso finds the similar instances according to their neighbours. If two instances have many common neighbours, they tend to become similar. Although some instances are profiled by the imperfect data, it is still able to find the similar counterparts. Furthermore, we develop an efficient algorithm based on Alternating Direction Method of Multipliers (ADMM) to obtain a moderately accurate solution. In addition, we present a dual method to obtain the accurate solution with the low additional time consumption. We demonstrate through extensive numerical experiments that triangle lasso is robust to the imperfect data. It usually yields a better performance than the state-of-the-art method when performing data analysis tasks in practical scenarios.