 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensing Anomalies like Humans: A Hominine Framework to Detect Abnormal Events from Unlabeled Videos
Paper and Code
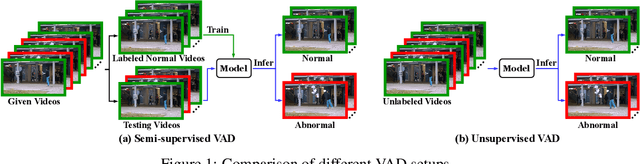
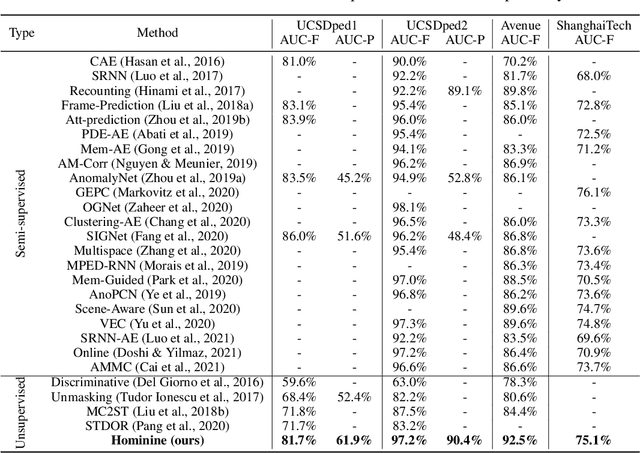
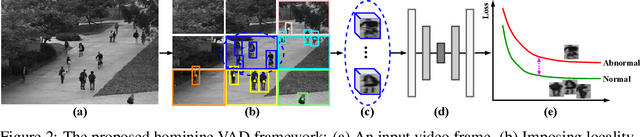

Video anomaly detection (VAD) has constantly been a vital topic in video analysis. As anomalies are often rare, it is typically addressed under a semi-supervised setup, which requires a training set with pure normal videos. To avoid exhausted manual labeling, we are inspired by how humans sense anomalies and propose a hominine framework that enables both unsupervised and end-to-end VAD. The framework is based on two key observations: 1) Human perception is usually local, i.e. focusing on local foreground and its context when sensing anomalies. Thus, we propose to impose locality-awareness by localizing foreground with generic knowledge, and a region localization strategy is designed to exploit local context. 2) Frequently-occurred events will mould humans' definition of normality, which motivates us to devise a surrogate training paradigm. It trains a deep neural network (DNN) to learn a surrogate task with unlabeled videos, and frequently-occurred events will play a dominant role in "moulding" the DNN. In this way, a training loss gap will automatically manifest rarely-seen novel events as anomalies. For implementation, we explore various surrogate tasks as well as both classic and emerging DNN models. Extensive evaluations on commonly-used VAD benchmarks justify the framework's applicability to different surrogate tasks or DNN models, and demonstrate its astonishing effectiveness: It not only outperforms existing unsupervised solutions by a wide margin (8% to 10% AUROC gain), but also achieves comparable or even superior performance to state-of-the-art semi-supervised counterparts.