 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Abnormal Event Detection by Learning to Complete Visual Cloze Tests
Paper and Code
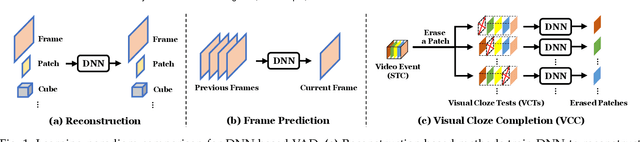
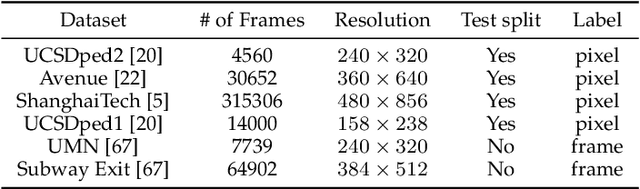
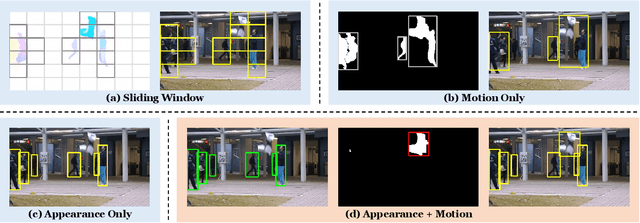
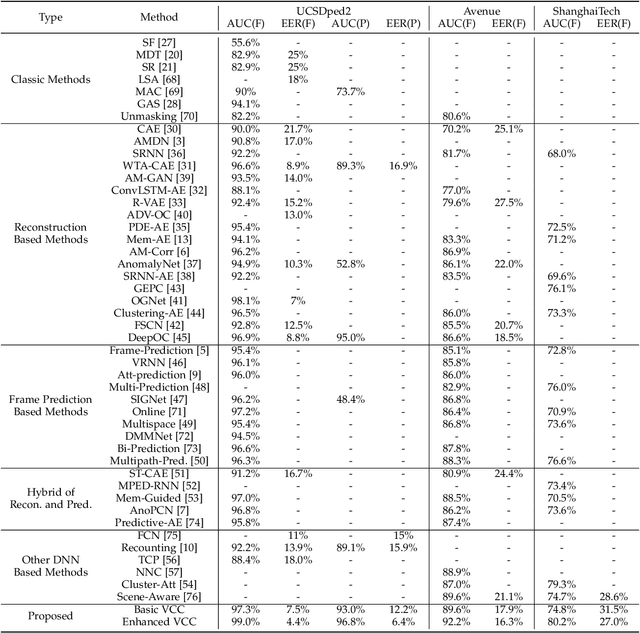
Video abnormal event detection (VAD) is a vital semi-supervised task that requires learning with only roughly labeled normal videos, as anomalies are often practically unavailable. Although deep neural networks (DNNs) enable great progress in VAD, existing solutions typically suffer from two issues: (1) The precise and comprehensive localization of video events is ignored. (2) The video semantics and temporal context are under-explored. To address those issues, we are motivated by the prevalent cloze test in education and propose a novel approach named visual cloze completion (VCC), which performs VAD by learning to complete "visual cloze tests" (VCTs). Specifically, VCC first localizes each video event and encloses it into a spatio-temporal cube (STC). To achieve both precise and comprehensive localization, appearance and motion are used as mutually complementary cues to mark the object region associated with each video event. For each marked region, a normalized patch sequence is extracted from temporally adjacent frames and stacked into the STC. By comparing each patch and the patch sequence of a STC to a visual "word" and "sentence" respectively, we can deliberately erase a certain "word" (patch) to yield a VCT. DNNs are then trained to infer the erased patch by video semantics, so as to complete the VCT. To fully exploit the temporal context, each patch in STC is alternatively erased to create multiple VCTs, and the erased patch's optical flow is also inferred to integrate richer motion clues. Meanwhile, a new DNN architecture is designed as a model-level solution to utilize video semantics and temporal context. Extensive experiments demonstrate that VCC achieves state-of-the-art VAD performance. Our codes and results are open at \url{https://github.com/yuguangnudt/VEC_VAD/tree/VCC}