 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointTuner: Appearance-Motion Adaptive Joint Training for Customized Video Generation
Mar 31, 2025Recent text-to-video advancements have enabled coherent video synthesis from prompts and expanded to fine-grained control over appearance and motion. However, existing methods either suffer from concept interference due to feature domain mismatch caused by naive decoupled optimizations or exhibit appearance contamination induced by spatial feature leakage resulting from the entanglement of motion and appearance in reference video reconstructions. In this paper, we propose JointTuner, a novel adaptive joint training framework, to alleviate these issues. Specifically, we develop Adaptive LoRA, which incorporates a context-aware gating mechanism, and integrate the gated LoRA components into the spatial and temporal Transformers within the diffusion model. These components enable simultaneous optimization of appearance and motion, eliminating concept interference. In addition, we introduce the Appearance-independent Temporal Loss, which decouples motion patterns from intrinsic appearance in reference video reconstructions through an appearance-agnostic noise prediction task. The key innovation lies in adding frame-wise offset noise to the ground-truth Gaussian noise, perturbing its distribution, thereby disrupting spatial attributes associated with frames while preserving temporal coherence. Furthermore, we construct a benchmark comprising 90 appearance-motion customized combinations and 10 multi-type automatic metrics across four dimensions, facilitating a more comprehensive evaluation for this customization task. Extensive experiments demonstrate the superior performance of our method compared to current advanced approaches.
"Stones from Other Hills can Polish Jade": Zero-shot Anomaly Image Synthesis via Cross-domain Anomaly Injection
Jan 25, 2025



Industrial image anomaly detection (IAD) is a pivotal topic with huge value. Due to anomaly's nature, real anomalies in a specific modern industrial domain (i.e. domain-specific anomalies) are usually too rare to collect, which severely hinders IAD. Thus, zero-shot anomaly synthesis (ZSAS), which synthesizes pseudo anomaly images without any domain-specific anomaly, emerges as a vital technique for IAD. However, existing solutions are either unable to synthesize authentic pseudo anomalies, or require cumbersome training. Thus, we focus on ZSAS and propose a brand-new paradigm that can realize both authentic and training-free ZSAS. It is based on a chronically-ignored fact: Although domain-specific anomalies are rare, real anomalies from other domains (i.e. cross-domain anomalies) are actually abundant and directly applicable to ZSAS. Specifically, our new ZSAS paradigm makes three-fold contributions: First, we propose a novel method named Cross-domain Anomaly Injection (CAI), which directly exploits cross-domain anomalies to enable highly authentic ZSAS in a training-free manner. Second, to supply CAI with sufficient cross-domain anomalies, we build the first domain-agnostic anomaly dataset within our best knowledge, which provides ZSAS with abundant real anomaly patterns. Third, we propose a CAI-guided Diffusion Mechanism, which further breaks the quantity limit of real anomalies and enable unlimited anomaly synthesis. Our head-to-head comparison with existing ZSAS solutions justifies our paradigm's superior performance for IAD and demonstrates it as an effective and pragmatic ZSAS solution.
An Unsupervised Short- and Long-Term Mask Representation for Multivariate Time Series Anomaly Detection
Aug 19, 2022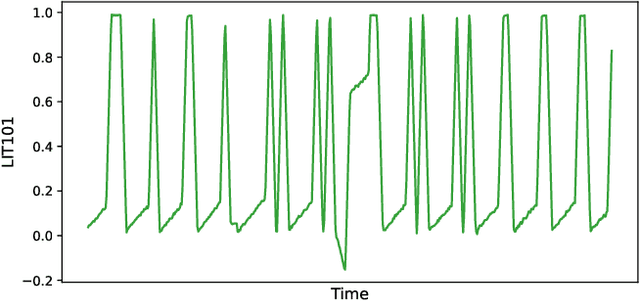
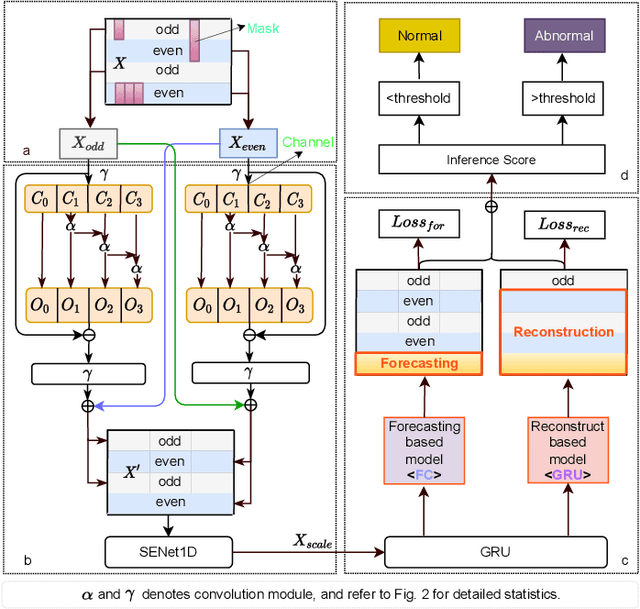

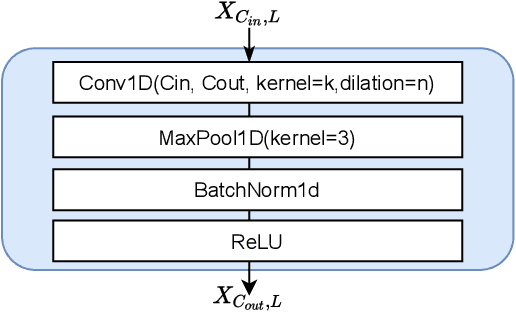
Anomaly detection of multivariate time series is meaningful for system behavior monitoring. This paper proposes an anomaly detection method based on unsupervised Short- and Long-term Mask Representation learning (SLMR). The main idea is to extract short-term local dependency patterns and long-term global trend patterns of the multivariate time series by using multi-scale residual dilated convolution and Gated Recurrent Unit(GRU) respectively. Furthermore, our approach can comprehend temporal contexts and feature correlations by combining spatial-temporal masked self-supervised representation learning and sequence split. It considers the importance of features is different, and we introduce the attention mechanism to adjust the contribution of each feature. Finally, a forecasting-based model and a reconstruction-based model are integrated to focus on single timestamp prediction and latent representation of time series. Experiments show that the performance of our method outperforms other state-of-the-art models on three real-world datasets. Further analysis shows that our method is good at interpretability.
Cloze Test Helps: Effective Video Anomaly Detection via Learning to Complete Video Events
Aug 27, 2020
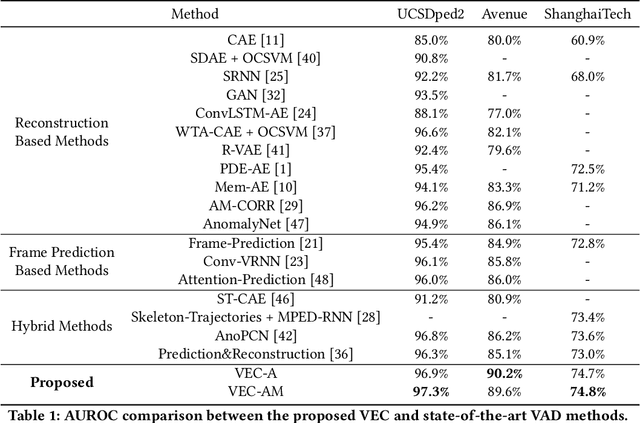
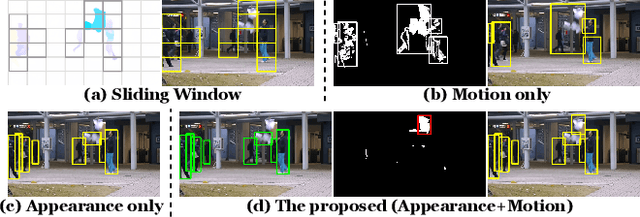

As a vital topic in media content interpretation, video anomaly detection (VAD) has made fruitful progress via deep neural network (DNN). However, existing methods usually follow a reconstruction or frame prediction routine. They suffer from two gaps: (1) They cannot localize video activities in a both precise and comprehensive manner. (2) They lack sufficient abilities to utilize high-level semantics and temporal context information. Inspired by frequently-used cloze test in language study, we propose a brand-new VAD solution named Video Event Completion (VEC) to bridge gaps above: First, we propose a novel pipeline to achieve both precise and comprehensive enclosure of video activities. Appearance and motion are exploited as mutually complimentary cues to localize regions of interest (RoIs). A normalized spatio-temporal cube (STC) is built from each RoI as a video event, which lays the foundation of VEC and serves as a basic processing unit. Second, we encourage DNN to capture high-level semantics by solving a visual cloze test. To build such a visual cloze test, a certain patch of STC is erased to yield an incomplete event (IE). The DNN learns to restore the original video event from the IE by inferring the missing patch. Third, to incorporate richer motion dynamics, another DNN is trained to infer erased patches' optical flow. Finally, two ensemble strategies using different types of IE and modalities are proposed to boost VAD performance, so as to fully exploit the temporal context and modality information for VAD. VEC can consistently outperform state-of-the-art methods by a notable margin (typically 1.5%-5% AUROC) on commonly-used VAD benchmarks. Our codes and results can be verified at github.com/yuguangnudt/VEC_VAD.
Characterizing Scalability of Sparse Matrix-Vector Multiplications on Phytium FT-2000+ Many-cores
Nov 20, 2019
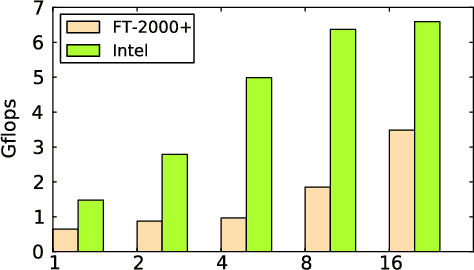

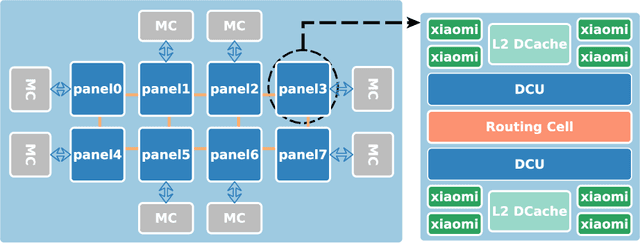
Understanding the scalability of parallel programs is crucial for software optimization and hardware architecture design. As HPC hardware is moving towards many-core design, it becomes increasingly difficult for a parallel program to make effective use of all available processor cores. This makes scalability analysis increasingly important. This paper presents a quantitative study for characterizing the scalability of sparse matrix-vector multiplications (SpMV) on Phytium FT-2000+, an ARM-based many-core architecture for HPC computing. We choose to study SpMV as it is a common operation in scientific and HPC applications. Due to the newness of ARM-based many-core architectures, there is little work on understanding the SpMV scalability on such hardware design. To close the gap, we carry out a large-scale empirical evaluation involved over 1,000 representative SpMV datasets. We show that, while many computation-intensive SpMV applications contain extensive parallelism, achieving a linear speedup is non-trivial on Phytium FT-2000+. To better understand what software and hardware parameters are most important for determining the scalability of a given SpMV kernel, we develop a performance analytical model based on the regression tree. We show that our model is highly effective in characterizing SpMV scalability, offering useful insights to help application developers for better optimizing SpMV on an emerging HPC architecture.