 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Streaming Parallelism on Heterogeneous Many-Core Architectures: A Machine Learning Based Approach
Mar 05, 2020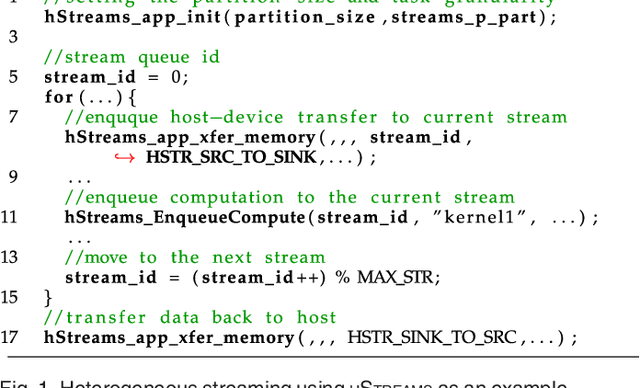

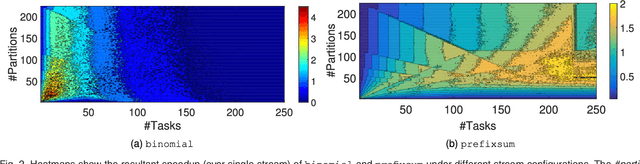
This article presents an automatic approach to quickly derive a good solution for hardware resource partition and task granularity for task-based parallel applications on heterogeneous many-core architectures. Our approach employs a performance model to estimate the resulting performance of the target application under a given resource partition and task granularity configuration. The model is used as a utility to quickly search for a good configuration at runtime. Instead of hand-crafting an analytical model that requires expert insights into low-level hardware details, we employ machine learning techniques to automatically learn it. We achieve this by first learning a predictive model offline using training programs. The learnt model can then be used to predict the performance of any unseen program at runtime. We apply our approach to 39 representative parallel applications and evaluate it on two representative heterogeneous many-core platforms: a CPU-XeonPhi platform and a CPU-GPU platform. Compared to the single-stream version, our approach achieves, on average, a 1.6x and 1.1x speedup on the XeonPhi and the GPU platform, respectively. These results translate to over 93% of the performance delivered by a theoretically perfect predictor.
Characterizing Scalability of Sparse Matrix-Vector Multiplications on Phytium FT-2000+ Many-cores
Nov 20, 2019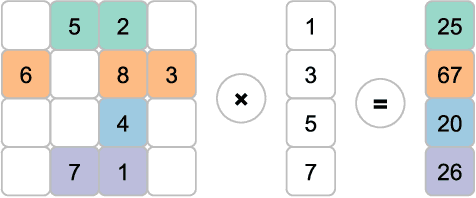
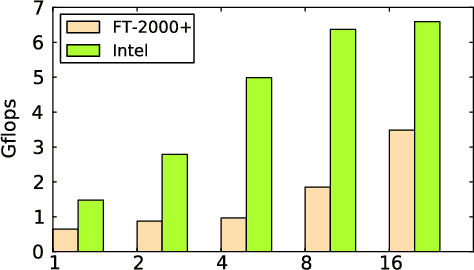

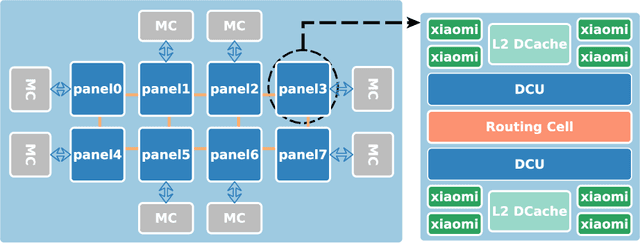
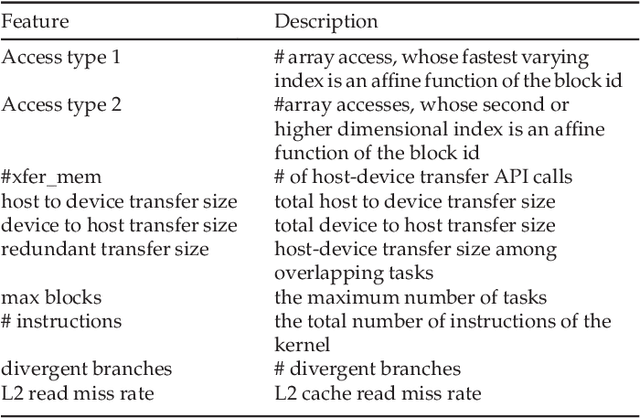
Understanding the scalability of parallel programs is crucial for software optimization and hardware architecture design. As HPC hardware is moving towards many-core design, it becomes increasingly difficult for a parallel program to make effective use of all available processor cores. This makes scalability analysis increasingly important. This paper presents a quantitative study for characterizing the scalability of sparse matrix-vector multiplications (SpMV) on Phytium FT-2000+, an ARM-based many-core architecture for HPC computing. We choose to study SpMV as it is a common operation in scientific and HPC applications. Due to the newness of ARM-based many-core architectures, there is little work on understanding the SpMV scalability on such hardware design. To close the gap, we carry out a large-scale empirical evaluation involved over 1,000 representative SpMV datasets. We show that, while many computation-intensive SpMV applications contain extensive parallelism, achieving a linear speedup is non-trivial on Phytium FT-2000+. To better understand what software and hardware parameters are most important for determining the scalability of a given SpMV kernel, we develop a performance analytical model based on the regression tree. We show that our model is highly effective in characterizing SpMV scalability, offering useful insights to help application developers for better optimizing SpMV on an emerging HPC architecture.
To Compress, or Not to Compress: Characterizing Deep Learning Model Compression for Embedded Inference
Oct 21, 2018
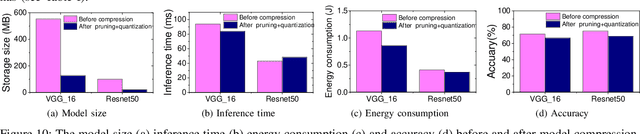

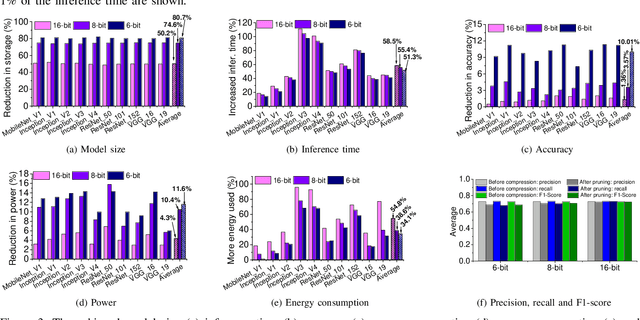
The recent advances in deep neural networks (DNNs) make them attractive for embedded systems. However, it can take a long time for DNNs to make an inference on resource-constrained computing devices. Model compression techniques can address the computation issue of deep inference on embedded devices. This technique is highly attractive, as it does not rely on specialized hardware, or computation-offloading that is often infeasible due to privacy concerns or high latency. However, it remains unclear how model compression techniques perform across a wide range of DNNs. To design efficient embedded deep learning solutions, we need to understand their behaviors. This work develops a quantitative approach to characterize model compression techniques on a representative embedded deep learning architecture, the NVIDIA Jetson Tx2. We perform extensive experiments by considering 11 influential neural network architectures from the image classification and the natural language processing domains. We experimentally show that how two mainstream compression techniques, data quantization and pruning, perform on these network architectures and the implications of compression techniques to the model storage size, inference time, energy consumption and performance metrics. We demonstrate that there are opportunities to achieve fast deep inference on embedded systems, but one must carefully choose the compression settings. Our results provide insights on when and how to apply model compression techniques and guidelines for designing efficient embedded deep learning systems.