 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGOT: A Physics-Geometry Operator Transformer for Complex PDEs
Dec 29, 2025While Transformers have demonstrated remarkable potential in modeling Partial Differential Equations (PDEs), modeling large-scale unstructured meshes with complex geometries remains a significant challenge. Existing efficient architectures often employ feature dimensionality reduction strategies, which inadvertently induces Geometric Aliasing, resulting in the loss of critical physical boundary information. To address this, we propose the Physics-Geometry Operator Transformer (PGOT), designed to reconstruct physical feature learning through explicit geometry awareness. Specifically, we propose Spectrum-Preserving Geometric Attention (SpecGeo-Attention). Utilizing a ``physics slicing-geometry injection" mechanism, this module incorporates multi-scale geometric encodings to explicitly preserve multi-scale geometric features while maintaining linear computational complexity $O(N)$. Furthermore, PGOT dynamically routes computations to low-order linear paths for smooth regions and high-order non-linear paths for shock waves and discontinuities based on spatial coordinates, enabling spatially adaptive and high-precision physical field modeling. PGOT achieves consistent state-of-the-art performance across four standard benchmarks and excels in large-scale industrial tasks including airfoil and car designs.
Temporal-Enhanced Multimodal Transformer for Referring Multi-Object Tracking and Segmentation
Oct 17, 2024



Referring multi-object tracking (RMOT) is an emerging cross-modal task that aims to locate an arbitrary number of target objects and maintain their identities referred by a language expression in a video. This intricate task involves the reasoning of linguistic and visual modalities, along with the temporal association of target objects. However, the seminal work employs only loose feature fusion and overlooks the utilization of long-term information on tracked objects. In this study, we introduce a compact Transformer-based method, termed TenRMOT. We conduct feature fusion at both encoding and decoding stages to fully exploit the advantages of Transformer architecture. Specifically, we incrementally perform cross-modal fusion layer-by-layer during the encoding phase. In the decoding phase, we utilize language-guided queries to probe memory features for accurate prediction of the desired objects. Moreover, we introduce a query update module that explicitly leverages temporal prior information of the tracked objects to enhance the consistency of their trajectories. In addition, we introduce a novel task called Referring Multi-Object Tracking and Segmentation (RMOTS) and construct a new dataset named Ref-KITTI Segmentation. Our dataset consists of 18 videos with 818 expressions, and each expression averages 10.7 masks, which poses a greater challenge compared to the typical single mask in most existing referring video segmentation datasets. TenRMOT demonstrates superior performance on both the referring multi-object tracking and the segmentation tasks.
HFN: Heterogeneous Feature Network for Multivariate Time Series Anomaly Detection
Nov 02, 2022Network or physical attacks on industrial equipment or computer systems may cause massive losses. Therefore, a quick and accurate anomaly detection (AD) based on monitoring data, especially the multivariate time-series (MTS) data, is of great significance. As the key step of anomaly detection for MTS data, learning the relations among different variables has been explored by many approaches. However, most of the existing approaches do not consider the heterogeneity between variables, that is, different types of variables (continuous numerical variables, discrete categorical variables or hybrid variables) may have different and distinctive edge distributions. In this paper, we propose a novel semi-supervised anomaly detection framework based on a heterogeneous feature network (HFN) for MTS, learning heterogeneous structure information from a mass of unlabeled time-series data to improve the accuracy of anomaly detection, and using attention coefficient to provide an explanation for the detected anomalies. Specifically, we first combine the embedding similarity subgraph generated by sensor embedding and feature value similarity subgraph generated by sensor values to construct a time-series heterogeneous graph, which fully utilizes the rich heterogeneous mutual information among variables. Then, a prediction model containing nodes and channel attentions is jointly optimized to obtain better time-series representations. This approach fuses the state-of-the-art technologies of heterogeneous graph structure learning (HGSL) and representation learning. The experiments on four sensor datasets from real-world applications demonstrate that our approach detects the anomalies more accurately than those baseline approaches, thus providing a basis for the rapid positioning of anomalies.
Optimizing Streaming Parallelism on Heterogeneous Many-Core Architectures: A Machine Learning Based Approach
Mar 05, 2020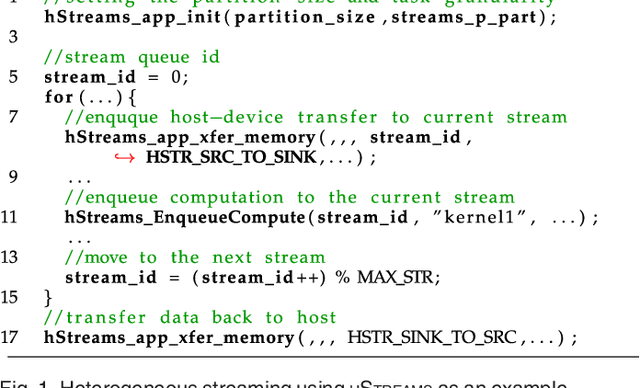

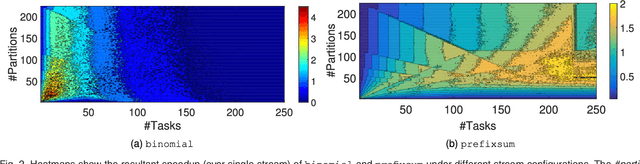
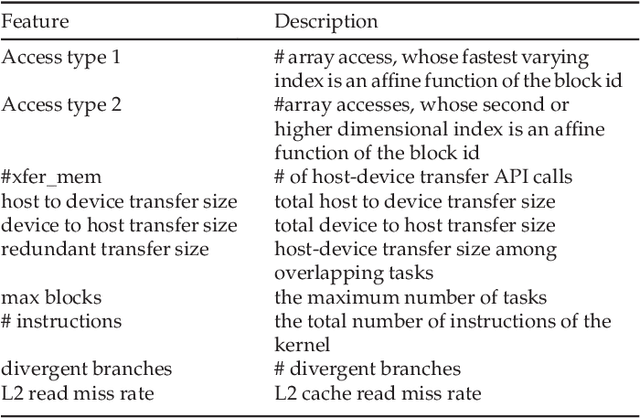
This article presents an automatic approach to quickly derive a good solution for hardware resource partition and task granularity for task-based parallel applications on heterogeneous many-core architectures. Our approach employs a performance model to estimate the resulting performance of the target application under a given resource partition and task granularity configuration. The model is used as a utility to quickly search for a good configuration at runtime. Instead of hand-crafting an analytical model that requires expert insights into low-level hardware details, we employ machine learning techniques to automatically learn it. We achieve this by first learning a predictive model offline using training programs. The learnt model can then be used to predict the performance of any unseen program at runtime. We apply our approach to 39 representative parallel applications and evaluate it on two representative heterogeneous many-core platforms: a CPU-XeonPhi platform and a CPU-GPU platform. Compared to the single-stream version, our approach achieves, on average, a 1.6x and 1.1x speedup on the XeonPhi and the GPU platform, respectively. These results translate to over 93% of the performance delivered by a theoretically perfect predictor.