 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Depthwise Separable Convolution for Lightweight Joint Source-Channel Coding in Wireless Image Transmission
Apr 24, 2026Depthwise separable convolutional (DSConv) layers have been successfully applied to deep learning (DL)-based joint source-channel coding (JSCC) schemes to reduce computational complexity. However, a systematic investigation of the layerwise and ratio-wise replacement of standard convolutional (Conv) layers with DSConv layers in JSCC systems for wireless image transmission remains largely unexplored. In this letter, we propose a configurable lightweight JSCC framework that incorporates a selective replacement strategy, enabling flexible substitution of standard Conv layers with DSConv layers at various layer positions and replacement ratios. By adjusting the proportion of layers replaced, we achieve different model compression levels and analyze their impact on reconstruction performance. Furthermore, we investigate how replacements at different encoder and decoder depths influence reconstruction quality under a fixed replacement ratio. Our results show that Conv-to-DSConv replacement at intermediate layers achieves a favorable complexity-performance trade-off, revealing layer-wise redundancy in DL-based JSCC systems. Extensive experiments further demonstrate that the proposed framework achieves substantial parameter reduction with only slight performance degradation, enabling flexible complexity-performance trade-offs for resource-constrained edge devices.
U-Net-Based Generative Joint Source-Channel Coding for Wireless Image Transmission
Feb 26, 2026Deep learning (DL)-based joint source-channel coding (JSCC) methods have achieved remarkable success in wireless image transmission. However, these methods either focus on conventional distortion metrics that do not necessarily yield high perceptual quality or incur high computational complexity. In this paper, we propose two DL-based JSCC (DeepJSCC) methods that leverage deep generative architectures for wireless image transmission. Specifically, we propose G-UNet-JSCC, a scheme comprising an encoder and a U-Net-based generator serving as the decoder. Its skip connections enable multi-scale feature fusion to improve both pixel-level fidelity and perceptual quality of reconstructed images by integrating low- and high-level features. To further enhance pixel-level fidelity, the encoder and the U-Net-based decoder are jointly optimized using a weighted sum of structural similarity and mean-squared error (MSE) losses. Building upon G-UNet-JSCC, we further develop a DeepJSCC method called cGAN-JSCC, where the decoder is enhanced through adversarial training. In this scheme, we retain the encoder of G-UNet-JSCC and adversarially train the decoder's generator against a patch-based discriminator. cGAN-JSCC employs a two-stage training procedure. The outer stage trains the encoder and the decoder end-to-end using an MSE loss, while the inner stage adversarially trains the decoder's generator and the discriminator by minimizing a joint loss combining adversarial and distortion losses. Simulation results demonstrate that the proposed methods achieve superior pixel-level fidelity and perceptual quality on both high- and low-resolution images. For low-resolution images, cGAN-JSCC achieves better reconstruction performance and greater robustness to channel variations than G-UNet-JSCC.
Bridging Synthetic-to-Real Gaps: Frequency-Aware Perturbation and Selection for Single-shot Multi-Parametric Mapping Reconstruction
Mar 05, 2025Data-centric artificial intelligence (AI) has remarkably advanced medical imaging, with emerging methods using synthetic data to address data scarcity while introducing synthetic-to-real gaps. Unsupervised domain adaptation (UDA) shows promise in ground truth-scarce tasks, but its application in reconstruction remains underexplored. Although multiple overlapping-echo detachment (MOLED) achieves ultra-fast multi-parametric reconstruction, extending its application to various clinical scenarios, the quality suffers from deficiency in mitigating the domain gap, difficulty in maintaining structural integrity, and inadequacy in ensuring mapping accuracy. To resolve these issues, we proposed frequency-aware perturbation and selection (FPS), comprising Wasserstein distance-modulated frequency-aware perturbation (WDFP) and hierarchical frequency-aware selection network (HFSNet), which integrates frequency-aware adaptive selection (FAS), compact FAS (cFAS) and feature-aware architecture integration (FAI). Specifically, perturbation activates domain-invariant feature learning within uncertainty, while selection refines optimal solutions within perturbation, establishing a robust and closed-loop learning pathway. Extensive experiments on synthetic data, along with diverse real clinical cases from 5 healthy volunteers, 94 ischemic stroke patients, and 46 meningioma patients, demonstrate the superiority and clinical applicability of FPS. Furthermore, FPS is applied to diffusion tensor imaging (DTI), underscoring its versatility and potential for broader medical applications. The code is available at https://github.com/flyannie/FPS.
GAN Based Near-Field Channel Estimation for Extremely Large-Scale MIMO Systems
Feb 27, 2024Extremely large-scale multiple-input-multiple-output (XL-MIMO) is a promising technique to achieve ultra-high spectral efficiency for future 6G communications. The mixed line-of-sight (LoS) and non-line-of-sight (NLoS) XL-MIMO near-field channel model is adopted to describe the XL-MIMO near-field channel accurately. In this paper, a generative adversarial network (GAN) variant based channel estimation method is proposed for XL-MIMO systems. Specifically, the GAN variant is developed to simultaneously estimate the LoS and NLoS path components of the XL-MIMO channel. The initially estimated channels instead of the received signals are input into the GAN variant as the conditional input to generate the XL-MIMO channels more efficiently. The GAN variant not only learns the mapping from the initially estimated channels to the XL-MIMO channels but also learns an adversarial loss. Moreover, we combine the adversarial loss with a conventional loss function to ensure the correct direction of training the generator. To further enhance the estimation performance, we investigate the impact of the hyper-parameter of the loss function on the performance of our method. Simulation results show that the proposed method outperforms the existing channel estimation approaches in the adopted channel model. In addition, the proposed method surpasses the Cram$\acute{\mathbf{e}}$r-Rao lower bound (CRLB) under low pilot overhead.
Cascade Feature Aggregation for Human Pose Estimation
Apr 08, 2019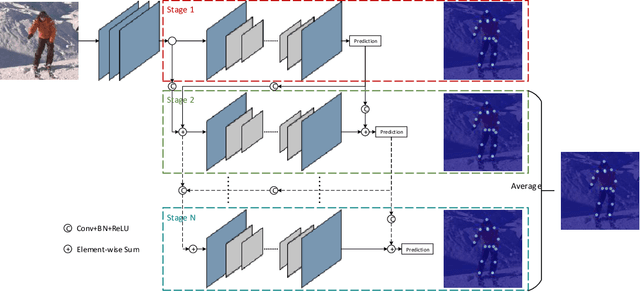
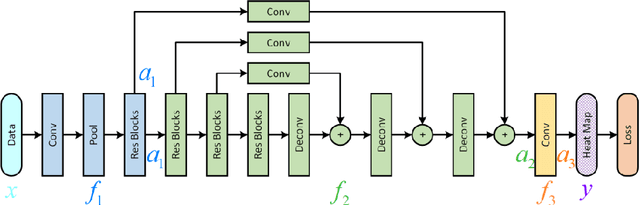
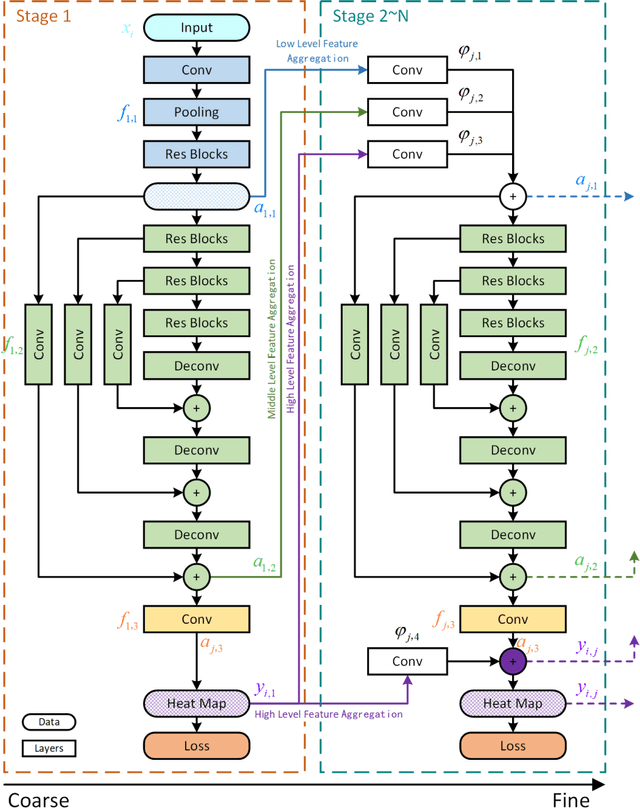
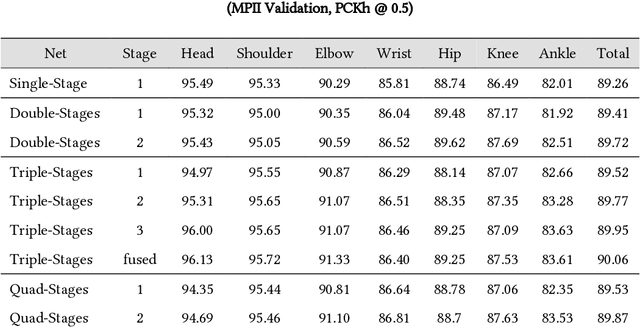
Human pose estimation plays an important role in many computer vision tasks and has been studied for many decades. However, due to complex appearance variations from poses, illuminations, occlusions and low resolutions, it still remains a challenging problem. Taking the advantage of high-level semantic information from deep convolutional neural networks is an effective way to improve the accuracy of human pose estimation. In this paper, we propose a novel Cascade Feature Aggregation (CFA) method, which cascades several hourglass networks for robust human pose estimation. Features from different stages are aggregated to obtain abundant contextual information, leading to robustness to poses, partial occlusions and low resolution. Moreover, results from different stages are fused to further improve the localization accuracy. The extensive experiments on MPII datasets and LIP datasets demonstrate that our proposed CFA outperforms the state-of-the-art and achieves the best performance on the state-of-the-art benchmark MPII.