 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDomainBench: Diagnosing Reasoning Collapse in High-Dimensional Scientific Knowledge Composition
May 14, 2026Large Language Models (LLMs) are increasingly deployed for knowledge synthesis, yet their capacity for compositional generalization in scientific knowledge remains under-characterized. Existing benchmarks primarily focus on single-turn restricted scenarios, failing to capture the capability boundaries exposed by real-world interactive scientific workflows. To address this, we introduce XDomainBench, a diagnostic benchmark for interactive interdisciplinary scientific reasoning. We formalize the composition order and mixture structure to enable systematic stress-testing from single-discipline to inter-disciplinary, comprising 8,598 interactive sessions across 20 domains and 4 task categories, with 8 realistic trajectory patterns covering difficulty and domain-mixture dynamics, simulating real AI4S scenarios. Large-scale evaluation of LLMs reveals a systematic reasoning collapse as composition order increases, stemming from two root causes: (i) direct difficulty increases induced by domain composition, and (ii) indirect interaction-amplified failures where trajectory patterns trigger error accumulation, reasoning breaks, and domain confusion, ultimately leading to session collapse.
ICON: Indirect Prompt Injection Defense for Agents based on Inference-Time Correction
Feb 24, 2026Large Language Model (LLM) agents are susceptible to Indirect Prompt Injection (IPI) attacks, where malicious instructions in retrieved content hijack the agent's execution. Existing defenses typically rely on strict filtering or refusal mechanisms, which suffer from a critical limitation: over-refusal, prematurely terminating valid agentic workflows. We propose ICON, a probing-to-mitigation framework that neutralizes attacks while preserving task continuity. Our key insight is that IPI attacks leave distinct over-focusing signatures in the latent space. We introduce a Latent Space Trace Prober to detect attacks based on high intensity scores. Subsequently, a Mitigating Rectifier performs surgical attention steering that selectively manipulate adversarial query key dependencies while amplifying task relevant elements to restore the LLM's functional trajectory. Extensive evaluations on multiple backbones show that ICON achieves a competitive 0.4% ASR, matching commercial grade detectors, while yielding a over 50% task utility gain. Furthermore, ICON demonstrates robust Out of Distribution(OOD) generalization and extends effectively to multi-modal agents, establishing a superior balance between security and efficiency.
Is the Trigger Essential? A Feature-Based Triggerless Backdoor Attack in Vertical Federated Learning
Feb 24, 2026As a distributed collaborative machine learning paradigm, vertical federated learning (VFL) allows multiple passive parties with distinct features and one active party with labels to collaboratively train a model. Although it is known for the privacy-preserving capabilities, VFL still faces significant privacy and security threats from backdoor attacks. Existing backdoor attacks typically involve an attacker implanting a trigger into the model during the training phase and executing the attack by adding the trigger to the samples during the inference phase. However, in this paper, we find that triggers are not essential for backdoor attacks in VFL. In light of this, we disclose a new backdoor attack pathway in VFL by introducing a feature-based triggerless backdoor attack. This attack operates under a more stringent security assumption, where the attacker is honest-but-curious rather than malicious during the training phase. It comprises three modules: label inference for the targeted backdoor attack, poison generation with amplification and perturbation mechanisms, and backdoor execution to implement the attack. Extensive experiments on five benchmark datasets demonstrate that our attack outperforms three baseline backdoor attacks by 2 to 50 times while minimally impacting the main task. Even in VFL scenarios with 32 passive parties and only one set of auxiliary data, our attack maintains high performance. Moreover, when confronted with distinct defense strategies, our attack remains largely unaffected and exhibits strong robustness. We hope that the disclosure of this triggerless backdoor attack pathway will encourage the community to revisit security threats in VFL scenarios and inspire researchers to develop more robust and practical defense strategies.
AdapTools: Adaptive Tool-based Indirect Prompt Injection Attacks on Agentic LLMs
Feb 24, 2026The integration of external data services (e.g., Model Context Protocol, MCP) has made large language model-based agents increasingly powerful for complex task execution. However, this advancement introduces critical security vulnerabilities, particularly indirect prompt injection (IPI) attacks. Existing attack methods are limited by their reliance on static patterns and evaluation on simple language models, failing to address the fast-evolving nature of modern AI agents. We introduce AdapTools, a novel adaptive IPI attack framework that selects stealthier attack tools and generates adaptive attack prompts to create a rigorous security evaluation environment. Our approach comprises two key components: (1) Adaptive Attack Strategy Construction, which develops transferable adversarial strategies for prompt optimization, and (2) Attack Enhancement, which identifies stealthy tools capable of circumventing task-relevance defenses. Comprehensive experimental evaluation shows that AdapTools achieves a 2.13 times improvement in attack success rate while degrading system utility by a factor of 1.78. Notably, the framework maintains its effectiveness even against state-of-the-art defense mechanisms. Our method advances the understanding of IPI attacks and provides a useful reference for future research.
Geometry-Aware Scene-Consistent Image Generation
Dec 14, 2025We study geometry-aware scene-consistent image generation: given a reference scene image and a text condition specifying an entity to be generated in the scene and its spatial relation to the scene, the goal is to synthesize an output image that preserves the same physical environment as the reference scene while correctly generating the entity according to the spatial relation described in the text. Existing methods struggle to balance scene preservation with prompt adherence: they either replicate the scene with high fidelity but poor responsiveness to the prompt, or prioritize prompt compliance at the expense of scene consistency. To resolve this trade-off, we introduce two key contributions: (i) a scene-consistent data construction pipeline that generates diverse, geometrically-grounded training pairs, and (ii) a novel geometry-guided attention loss that leverages cross-view cues to regularize the model's spatial reasoning. Experiments on our scene-consistent benchmark show that our approach achieves better scene alignment and text-image consistency than state-of-the-art baselines, according to both automatic metrics and human preference studies. Our method produces geometrically coherent images with diverse compositions that remain faithful to the textual instructions and the underlying scene structure.
Disrupting Hierarchical Reasoning: Adversarial Protection for Geographic Privacy in Multimodal Reasoning Models
Dec 09, 2025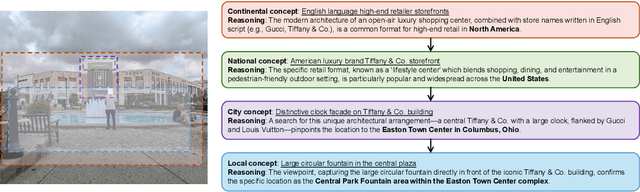
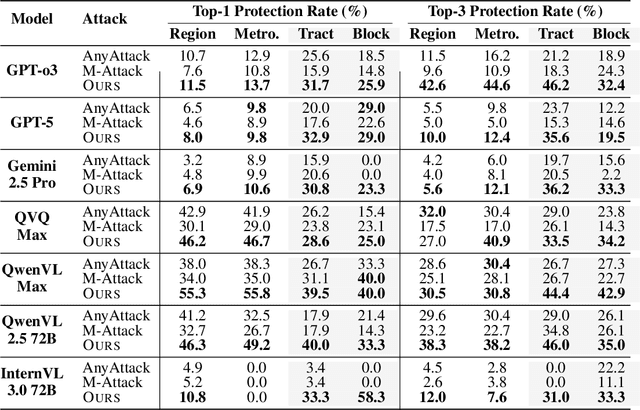
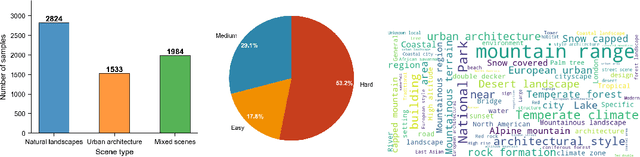
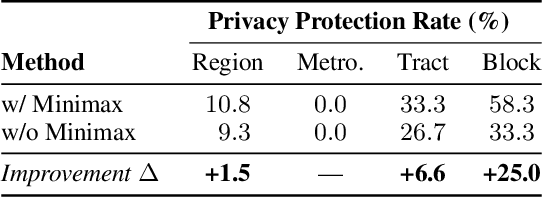
Multi-modal large reasoning models (MLRMs) pose significant privacy risks by inferring precise geographic locations from personal images through hierarchical chain-of-thought reasoning. Existing privacy protection techniques, primarily designed for perception-based models, prove ineffective against MLRMs' sophisticated multi-step reasoning processes that analyze environmental cues. We introduce \textbf{ReasonBreak}, a novel adversarial framework specifically designed to disrupt hierarchical reasoning in MLRMs through concept-aware perturbations. Our approach is founded on the key insight that effective disruption of geographic reasoning requires perturbations aligned with conceptual hierarchies rather than uniform noise. ReasonBreak strategically targets critical conceptual dependencies within reasoning chains, generating perturbations that invalidate specific inference steps and cascade through subsequent reasoning stages. To facilitate this approach, we contribute \textbf{GeoPrivacy-6K}, a comprehensive dataset comprising 6,341 ultra-high-resolution images ($\geq$2K) with hierarchical concept annotations. Extensive evaluation across seven state-of-the-art MLRMs (including GPT-o3, GPT-5, Gemini 2.5 Pro) demonstrates ReasonBreak's superior effectiveness, achieving a 14.4\% improvement in tract-level protection (33.8\% vs 19.4\%) and nearly doubling block-level protection (33.5\% vs 16.8\%). This work establishes a new paradigm for privacy protection against reasoning-based threats.
Demonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
Bridging Synthetic-to-Real Gaps: Frequency-Aware Perturbation and Selection for Single-shot Multi-Parametric Mapping Reconstruction
Mar 05, 2025Data-centric artificial intelligence (AI) has remarkably advanced medical imaging, with emerging methods using synthetic data to address data scarcity while introducing synthetic-to-real gaps. Unsupervised domain adaptation (UDA) shows promise in ground truth-scarce tasks, but its application in reconstruction remains underexplored. Although multiple overlapping-echo detachment (MOLED) achieves ultra-fast multi-parametric reconstruction, extending its application to various clinical scenarios, the quality suffers from deficiency in mitigating the domain gap, difficulty in maintaining structural integrity, and inadequacy in ensuring mapping accuracy. To resolve these issues, we proposed frequency-aware perturbation and selection (FPS), comprising Wasserstein distance-modulated frequency-aware perturbation (WDFP) and hierarchical frequency-aware selection network (HFSNet), which integrates frequency-aware adaptive selection (FAS), compact FAS (cFAS) and feature-aware architecture integration (FAI). Specifically, perturbation activates domain-invariant feature learning within uncertainty, while selection refines optimal solutions within perturbation, establishing a robust and closed-loop learning pathway. Extensive experiments on synthetic data, along with diverse real clinical cases from 5 healthy volunteers, 94 ischemic stroke patients, and 46 meningioma patients, demonstrate the superiority and clinical applicability of FPS. Furthermore, FPS is applied to diffusion tensor imaging (DTI), underscoring its versatility and potential for broader medical applications. The code is available at https://github.com/flyannie/FPS.
Evaluation of dynamic characteristics of power grid based on GNN and application on knowledge graph
Nov 28, 2023
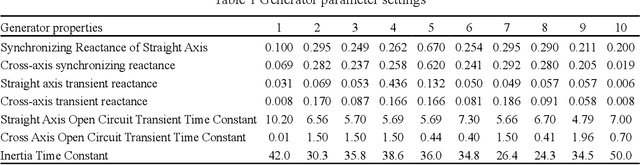
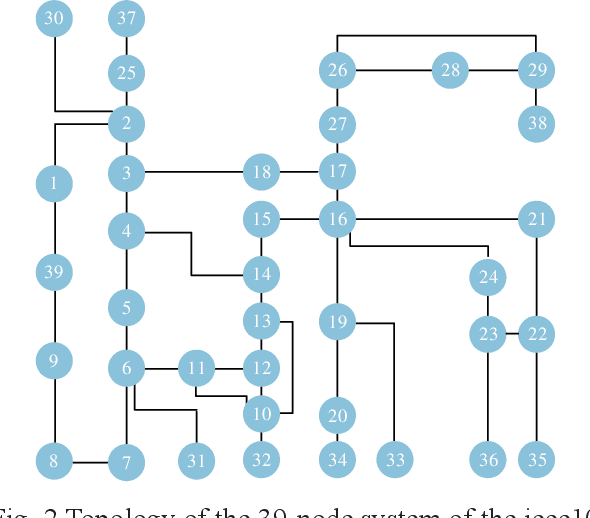

A novel method for detecting faults in power grids using a graph neural network (GNN) has been developed, aimed at enhancing intelligent fault diagnosis in network operation and maintenance. This GNN-based approach identifies faulty nodes within the power grid through a specialized electrical feature extraction model coupled with a knowledge graph. Incorporating temporal data, the method leverages the status of nodes from preceding and subsequent time periods to aid in current fault detection. To validate the effectiveness of this GNN in extracting node features, a correlation analysis of the output features from each node within the neural network layer was conducted. The results from experiments show that this method can accurately locate fault nodes in simulated scenarios with a remarkable 99.53% accuracy. Additionally, the graph neural network's feature modeling allows for a qualitative examination of how faults spread across nodes, providing valuable insights for analyzing fault nodes.
Method for Text Entity Linking in Power Distribution Scheduling Oriented to Power Distribution Network Knowledge Graph
Nov 15, 2023The proposed method for linking entities in power distribution dispatch texts to a power distribution network knowledge graph is based on a deep understanding of these networks. This method leverages the unique features of entities in both the power distribution network's knowledge graph and the dispatch texts, focusing on their semantic, phonetic, and syntactic characteristics. An enhanced model, the Lexical Semantic Feature-based Skip Convolutional Neural Network (LSF-SCNN), is utilized for effectively matching dispatch text entities with those in the knowledge graph. The efficacy of this model, compared to a control model, is evaluated through cross-validation methods in real-world power distribution dispatch scenarios. The results indicate that the LSF-SCNN model excels in accurately linking a variety of entity types, demonstrating high overall accuracy in entity linking when the process is conducted in English.