 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVRL3: A Data-Driven Framework for Visual Deep Reinforcement Learning
Paper and Code
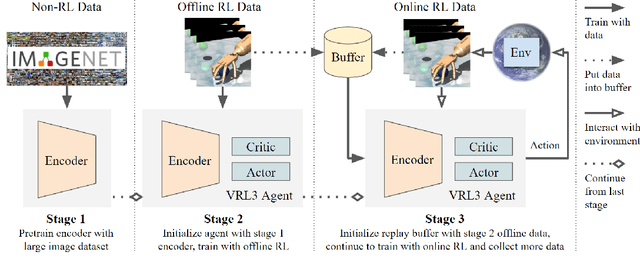
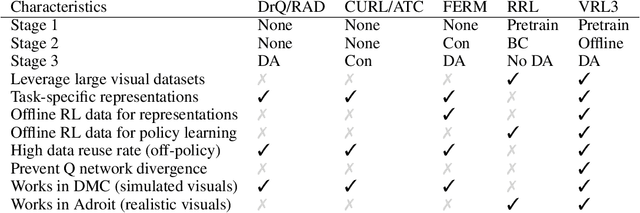

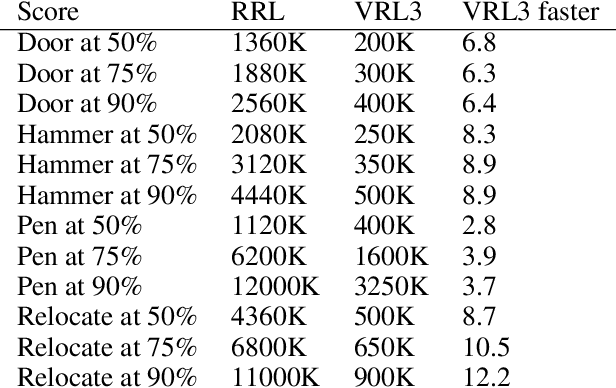
We propose a simple but powerful data-driven framework for solving highly challenging visual deep reinforcement learning (DRL) tasks. We analyze a number of major obstacles in taking a data-driven approach, and present a suite of design principles, training strategies, and critical insights about data-driven visual DRL. Our framework has three stages: in stage 1, we leverage non-RL datasets (e.g. ImageNet) to learn task-agnostic visual representations; in stage 2, we use offline RL data (e.g. a limited number of expert demonstrations) to convert the task-agnostic representations into more powerful task-specific representations; in stage 3, we fine-tune the agent with online RL. On a set of highly challenging hand manipulation tasks with sparse reward and realistic visual inputs, our framework learns 370%-1200% faster than the previous SOTA method while using an encoder that is 50 times smaller, fully demonstrating the potential of data-driven deep reinforcement learning.