 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance
Nov 17, 2021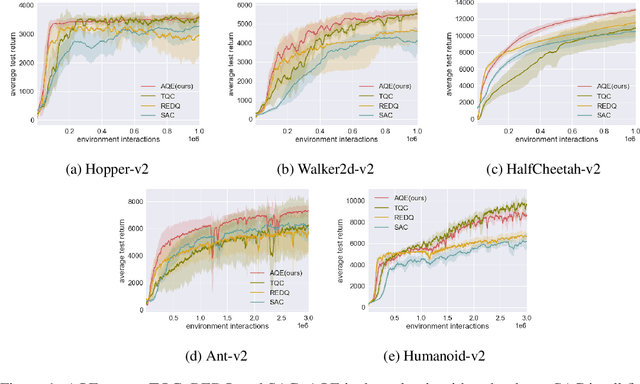


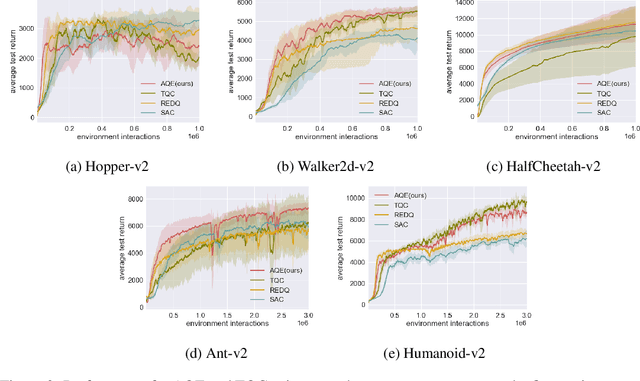
Recently, Truncated Quantile Critics (TQC), using distributional representation of critics, was shown to provide state-of-the-art asymptotic training performance on all environments from the MuJoCo continuous control benchmark suite. Also recently, Randomized Ensemble Double Q-Learning (REDQ), using a high update-to-data ratio and target randomization, was shown to achieve high sample efficiency that is competitive with state-of-the-art model-based methods. In this paper, we propose a novel model-free algorithm, Aggressive Q-Learning with Ensembles (AQE), which improves the sample-efficiency performance of REDQ and the asymptotic performance of TQC, thereby providing overall state-of-the-art performance during all stages of training. Moreover, AQE is very simple, requiring neither distributional representation of critics nor target randomization.
On-Policy Deep Reinforcement Learning for the Average-Reward Criterion
Jun 14, 2021



We develop theory and algorithms for average-reward on-policy Reinforcement Learning (RL). We first consider bounding the difference of the long-term average reward for two policies. We show that previous work based on the discounted return (Schulman et al., 2015; Achiam et al., 2017) results in a non-meaningful bound in the average-reward setting. By addressing the average-reward criterion directly, we then derive a novel bound which depends on the average divergence between the two policies and Kemeny's constant. Based on this bound, we develop an iterative procedure which produces a sequence of monotonically improved policies for the average reward criterion. This iterative procedure can then be combined with classic DRL (Deep Reinforcement Learning) methods, resulting in practical DRL algorithms that target the long-run average reward criterion. In particular, we demonstrate that Average-Reward TRPO (ATRPO), which adapts the on-policy TRPO algorithm to the average-reward criterion, significantly outperforms TRPO in the most challenging MuJuCo environments.
First Order Optimization in Policy Space for Constrained Deep Reinforcement Learning
Feb 16, 2020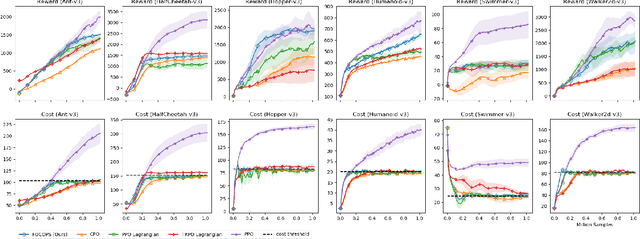
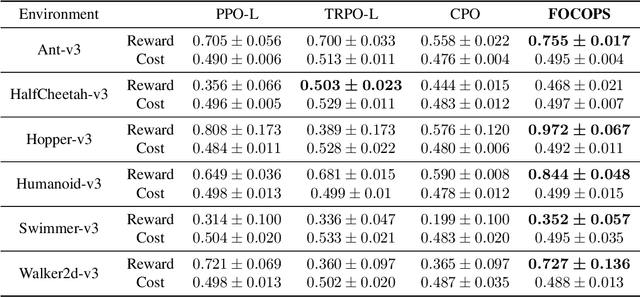
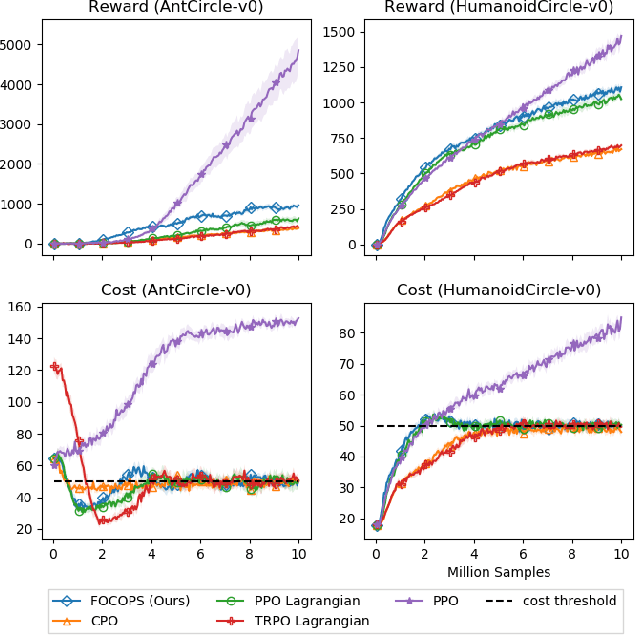

In reinforcement learning, an agent attempts to learn high-performing behaviors through interacting with the environment, such behaviors are often quantified in the form of a reward function. However some aspects of behavior, such as ones which are deemed unsafe and are to be avoided, are best captured through constraints. We propose a novel approach called First Order Constrained Optimization in Policy Space (FOCOPS) which maximizes an agent's overall reward while ensuring the agent satisfies a set of cost constraints. Using data generated from the current policy, FOCOPS first finds the optimal update policy by solving a constrained optimization problem in the nonparameterized policy space. FOCOPS then projects the update policy back into the parametric policy space. Our approach provides a guarantee for constraint satisfaction throughout training and is first-order in nature therefore extremely simple to implement. We provide empirical evidence that our algorithm achieves better performance on a set of constrained robotics locomotive tasks compared to current state of the art approaches.
Supervised Policy Update for Deep Reinforcement Learning
Dec 24, 2018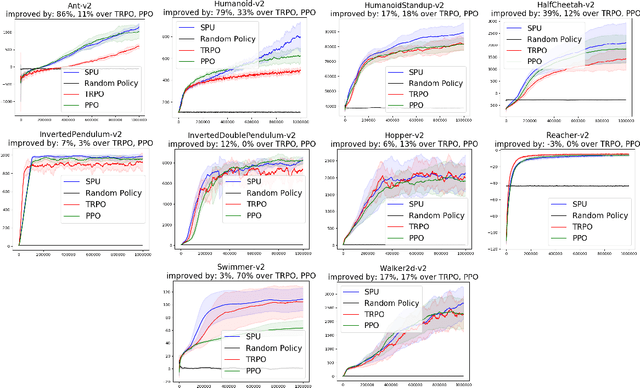



We propose a new sample-efficient methodology, called Supervised Policy Update (SPU), for deep reinforcement learning. Starting with data generated by the current policy, SPU formulates and solves a constrained optimization problem in the non-parameterized proximal policy space. Using supervised regression, it then converts the optimal non-parameterized policy to a parameterized policy, from which it draws new samples. The methodology is general in that it applies to both discrete and continuous action spaces, and can handle a wide variety of proximity constraints for the non-parameterized optimization problem. We show how the Natural Policy Gradient and Trust Region Policy Optimization (NPG/TRPO) problems, and the Proximal Policy Optimization (PPO) problem can be addressed by this methodology. The SPU implementation is much simpler than TRPO. In terms of sample efficiency, our extensive experiments show SPU outperforms TRPO in Mujoco simulated robotic tasks and outperforms PPO in Atari video game tasks.
Efficient Entropy for Policy Gradient with Multidimensional Action Space
Jun 02, 2018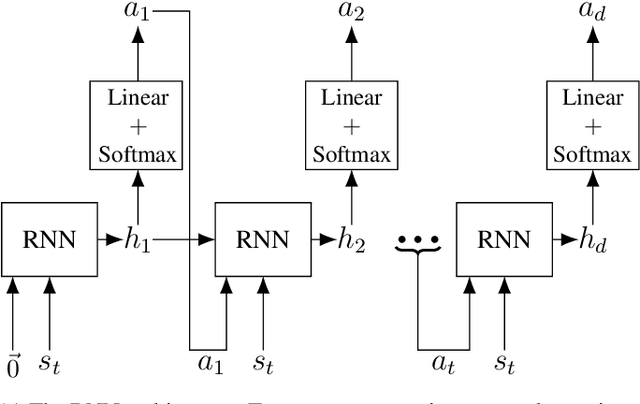
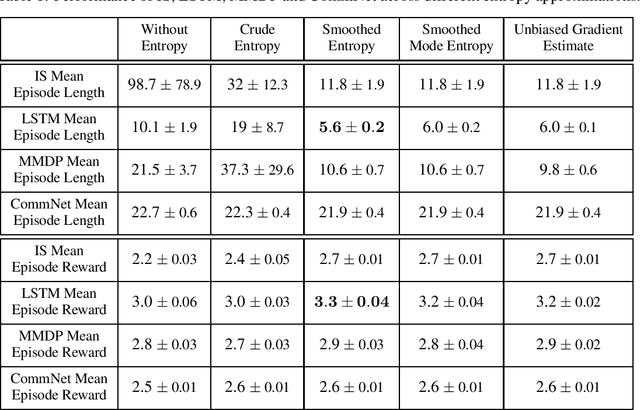


In recent years, deep reinforcement learning has been shown to be adept at solving sequential decision processes with high-dimensional state spaces such as in the Atari games. Many reinforcement learning problems, however, involve high-dimensional discrete action spaces as well as high-dimensional state spaces. This paper considers entropy bonus, which is used to encourage exploration in policy gradient. In the case of high-dimensional action spaces, calculating the entropy and its gradient requires enumerating all the actions in the action space and running forward and backpropagation for each action, which may be computationally infeasible. We develop several novel unbiased estimators for the entropy bonus and its gradient. We apply these estimators to several models for the parameterized policies, including Independent Sampling, CommNet, Autoregressive with Modified MDP, and Autoregressive with LSTM. Finally, we test our algorithms on two environments: a multi-hunter multi-rabbit grid game and a multi-agent multi-arm bandit problem. The results show that our entropy estimators substantially improve performance with marginal additional computational cost.