 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Order Optimization in Policy Space for Constrained Deep Reinforcement Learning
Paper and Code
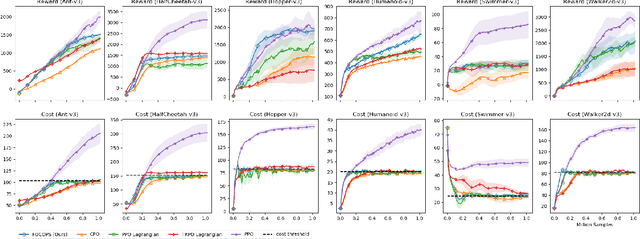
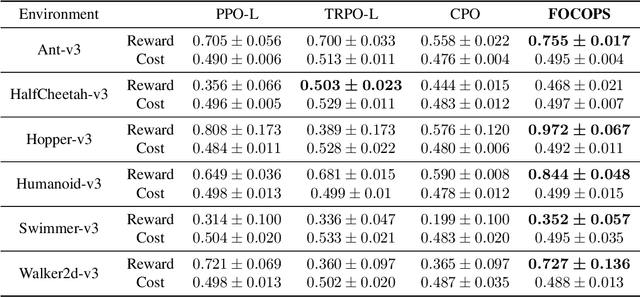
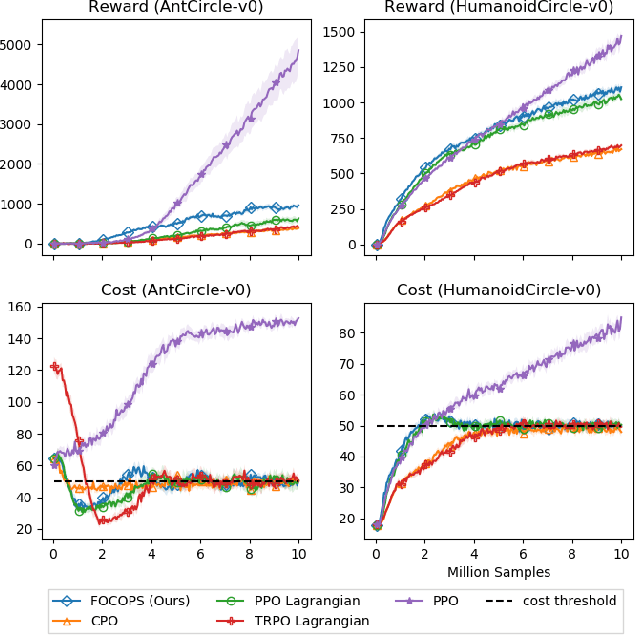

In reinforcement learning, an agent attempts to learn high-performing behaviors through interacting with the environment, such behaviors are often quantified in the form of a reward function. However some aspects of behavior, such as ones which are deemed unsafe and are to be avoided, are best captured through constraints. We propose a novel approach called First Order Constrained Optimization in Policy Space (FOCOPS) which maximizes an agent's overall reward while ensuring the agent satisfies a set of cost constraints. Using data generated from the current policy, FOCOPS first finds the optimal update policy by solving a constrained optimization problem in the nonparameterized policy space. FOCOPS then projects the update policy back into the parametric policy space. Our approach provides a guarantee for constraint satisfaction throughout training and is first-order in nature therefore extremely simple to implement. We provide empirical evidence that our algorithm achieves better performance on a set of constrained robotics locomotive tasks compared to current state of the art approaches.