 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Anomaly Knowledge Excavation: Unveiling Sparse Sensitive Neurons in Vision-Language Models
Apr 09, 2026Large-scale vision-language models (VLMs) exhibit remarkable zero-shot capabilities, yet the internal mechanisms driving their anomaly detection (AD) performance remain poorly understood. Current methods predominantly treat VLMs as black-box feature extractors, assuming that anomaly-specific knowledge must be acquired through external adapters or memory banks. In this paper, we challenge this assumption by arguing that anomaly knowledge is intrinsically embedded within pre-trained models but remains latent and under-activated. We hypothesize that this knowledge is concentrated within a sparse subset of anomaly-sensitive neurons. To validate this, we propose latent anomaly knowledge excavation (LAKE), a training-free framework that identifies and elicits these critical neuronal signals using only a minimal set of normal samples. By isolating these sensitive neurons, LAKE constructs a highly compact normality representation that integrates visual structural deviations with cross-modal semantic activations. Extensive experiments on industrial AD benchmarks demonstrate that LAKE achieves state-of-the-art performance while providing intrinsic, neuron-level interpretability. Ultimately, our work advocates for a paradigm shift: redefining anomaly detection as the targeted activation of latent pre-trained knowledge rather than the acquisition of a downstream task.
DGRNet: Disagreement-Guided Refinement for Uncertainty-Aware Brain Tumor Segmentation
Mar 22, 2026Accurate brain tumor segmentation from MRI scans is critical for diagnosis and treatment planning. Despite the strong performance of recent deep learning approaches, two fundamental limitations remain: (1) the lack of reliable uncertainty quantification in single-model predictions, which is essential for clinical deployment because the level of uncertainty may impact treatment decision-making, and (2) the under-utilization of rich information in radiology reports that can guide segmentation in ambiguous regions. In this paper, we propose the Disagreement-Guided Refinement Network (DGRNet), a novel framework that addresses both limitations through multi-view disagreement-based uncertainty estimation and text-conditioned refinement. DGRNet generates diverse predictions via four lightweight view-specific adapters attached to a shared encoder-decoder, enabling efficient uncertainty quantification within a single forward pass. Afterward, we build disagreement maps to identify regions of high segmentation uncertainty, which are then selectively refined according to clinical reports. Moreover, we introduce a diversity-preserving training strategy that combines pairwise similarity penalties and gradient isolation to prevent view collapse. The experimental results on the TextBraTS dataset show that DGRNet favorably improves state-of-the-art segmentation accuracy by 2.4% and 11% in main metrics Dice and HD95, respectively, while providing meaningful uncertainty estimates.
Fault-Tolerant Evaluation for Sample-Efficient Model Performance Estimators
Feb 06, 2026In the era of Model-as-a-Service, organizations increasingly rely on third-party AI models for rapid deployment. However, the dynamic nature of emerging AI applications, the continual introduction of new datasets, and the growing number of models claiming superior performance make efficient and reliable validation of model services increasingly challenging. This motivates the development of sample-efficient performance estimators, which aim to estimate model performance by strategically selecting instances for labeling, thereby reducing annotation cost. Yet existing evaluation approaches often fail in low-variance settings: RMSE conflates bias and variance, masking persistent bias when variance is small, while p-value based tests become hypersensitive, rejecting adequate estimators for negligible deviations. To address this, we propose a fault-tolerant evaluation framework that integrates bias and variance considerations within an adjustable tolerance level ${\varepsilon}$, enabling the evaluation of performance estimators within practically acceptable error margins. We theoretically show that proper calibration of ${\varepsilon}$ ensures reliable evaluation across different variance regimes, and we further propose an algorithm that automatically optimizes and selects ${\varepsilon}$. Experiments on real-world datasets demonstrate that our framework provides comprehensive and actionable insights into estimator behavior.
A Survey on Progress in LLM Alignment from the Perspective of Reward Design
May 05, 2025The alignment of large language models (LLMs) with human values and intentions represents a core challenge in current AI research, where reward mechanism design has become a critical factor in shaping model behavior. This study conducts a comprehensive investigation of reward mechanisms in LLM alignment through a systematic theoretical framework, categorizing their development into three key phases: (1) feedback (diagnosis), (2) reward design (prescription), and (3) optimization (treatment). Through a four-dimensional analysis encompassing construction basis, format, expression, and granularity, this research establishes a systematic classification framework that reveals evolutionary trends in reward modeling. The field of LLM alignment faces several persistent challenges, while recent advances in reward design are driving significant paradigm shifts. Notable developments include the transition from reinforcement learning-based frameworks to novel optimization paradigms, as well as enhanced capabilities to address complex alignment scenarios involving multimodal integration and concurrent task coordination. Finally, this survey outlines promising future research directions for LLM alignment through innovative reward design strategies.
Radio Signal Classification by Adversarially Robust Quantum Machine Learning
Dec 13, 2023



Radio signal classification plays a pivotal role in identifying the modulation scheme used in received radio signals, which is essential for demodulation and proper interpretation of the transmitted information. Researchers have underscored the high susceptibility of ML algorithms for radio signal classification to adversarial attacks. Such vulnerability could result in severe consequences, including misinterpretation of critical messages, interception of classified information, or disruption of communication channels. Recent advancements in quantum computing have revolutionized theories and implementations of computation, bringing the unprecedented development of Quantum Machine Learning (QML). It is shown that quantum variational classifiers (QVCs) provide notably enhanced robustness against classical adversarial attacks in image classification. However, no research has yet explored whether QML can similarly mitigate adversarial threats in the context of radio signal classification. This work applies QVCs to radio signal classification and studies their robustness to various adversarial attacks. We also propose the novel application of the approximate amplitude encoding (AAE) technique to encode radio signal data efficiently. Our extensive simulation results present that attacks generated on QVCs transfer well to CNN models, indicating that these adversarial examples can fool neural networks that they are not explicitly designed to attack. However, the converse is not true. QVCs primarily resist the attacks generated on CNNs. Overall, with comprehensive simulations, our results shed new light on the growing field of QML by bridging knowledge gaps in QAML in radio signal classification and uncovering the advantages of applying QML methods in practical applications.
Quantum-Inspired Machine Learning: a Survey
Sep 08, 2023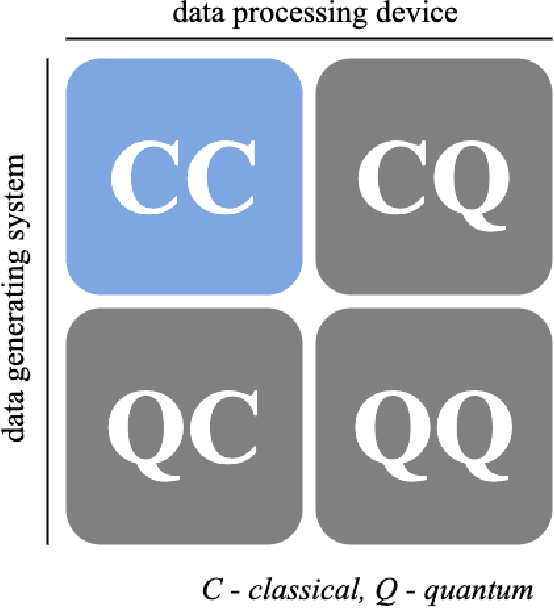

Quantum-inspired Machine Learning (QiML) is a burgeoning field, receiving global attention from researchers for its potential to leverage principles of quantum mechanics within classical computational frameworks. However, current review literature often presents a superficial exploration of QiML, focusing instead on the broader Quantum Machine Learning (QML) field. In response to this gap, this survey provides an integrated and comprehensive examination of QiML, exploring QiML's diverse research domains including tensor network simulations, dequantized algorithms, and others, showcasing recent advancements, practical applications, and illuminating potential future research avenues. Further, a concrete definition of QiML is established by analyzing various prior interpretations of the term and their inherent ambiguities. As QiML continues to evolve, we anticipate a wealth of future developments drawing from quantum mechanics, quantum computing, and classical machine learning, enriching the field further. This survey serves as a guide for researchers and practitioners alike, providing a holistic understanding of QiML's current landscape and future directions.
Spatio-temporal Incentives Optimization for Ride-hailing Services with Offline Deep Reinforcement Learning
Nov 06, 2022A fundamental question in any peer-to-peer ride-sharing system is how to, both effectively and efficiently, meet the request of passengers to balance the supply and demand in real time. On the passenger side, traditional approaches focus on pricing strategies by increasing the probability of users' call to adjust the distribution of demand. However, previous methods do not take into account the impact of changes in strategy on future supply and demand changes, which means drivers are repositioned to different destinations due to passengers' calls, which will affect the driver's income for a period of time in the future. Motivated by this observation, we make an attempt to optimize the distribution of demand to handle this problem by learning the long-term spatio-temporal values as a guideline for pricing strategy. In this study, we propose an offline deep reinforcement learning based method focusing on the demand side to improve the utilization of transportation resources and customer satisfaction. We adopt a spatio-temporal learning method to learn the value of different time and location, then incentivize the ride requests of passengers to adjust the distribution of demand to balance the supply and demand in the system. In particular, we model the problem as a Markov Decision Process (MDP).
Aggressive Q-Learning with Ensembles: Achieving Both High Sample Efficiency and High Asymptotic Performance
Nov 17, 2021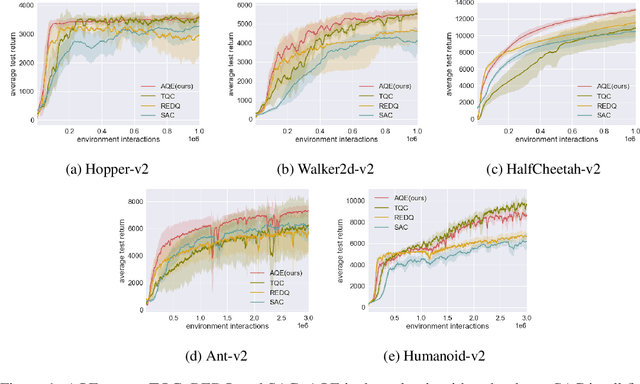


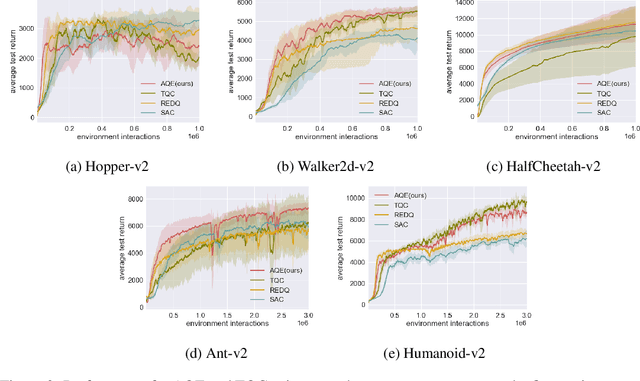
Recently, Truncated Quantile Critics (TQC), using distributional representation of critics, was shown to provide state-of-the-art asymptotic training performance on all environments from the MuJoCo continuous control benchmark suite. Also recently, Randomized Ensemble Double Q-Learning (REDQ), using a high update-to-data ratio and target randomization, was shown to achieve high sample efficiency that is competitive with state-of-the-art model-based methods. In this paper, we propose a novel model-free algorithm, Aggressive Q-Learning with Ensembles (AQE), which improves the sample-efficiency performance of REDQ and the asymptotic performance of TQC, thereby providing overall state-of-the-art performance during all stages of training. Moreover, AQE is very simple, requiring neither distributional representation of critics nor target randomization.
BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning
Oct 27, 2019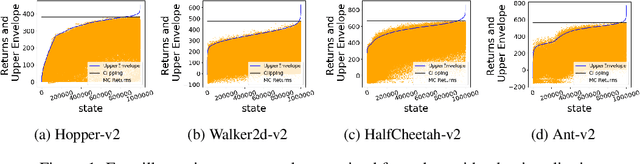

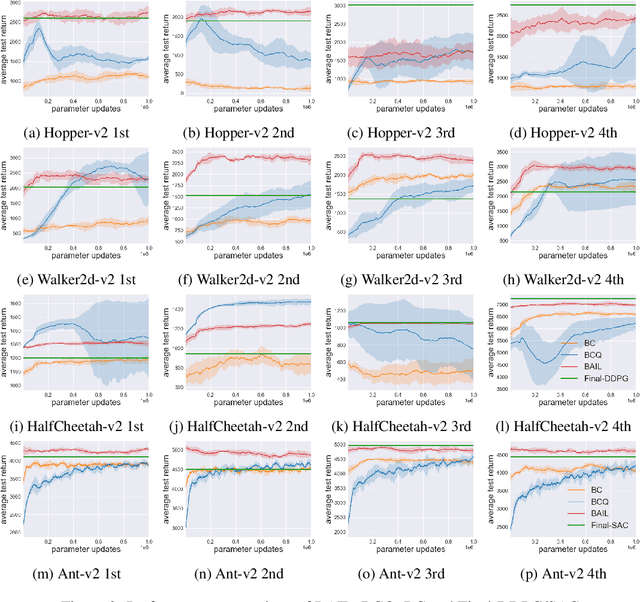

The field of Deep Reinforcement Learning (DRL) has recently seen a surge in research in batch reinforcement learning, which aims for sample-efficient learning from a given data set without additional interactions with the environment. In the batch DRL setting, commonly employed off-policy DRL algorithms can perform poorly and sometimes even fail to learn altogether. In this paper, we propose a new algorithm, Best-Action Imitation Learning (BAIL), which unlike many off-policy DRL algorithms does not involve maximizing Q functions over the action space. Striving for simplicity as well as performance, BAIL first selects from the batch the actions it believes to be high-performing actions for their corresponding states; it then uses those state-action pairs to train a policy network using imitation learning. Although BAIL is simple, we demonstrate that BAIL achieves state of the art performance on the Mujoco benchmark.
Towards Simplicity in Deep Reinforcement Learning: Streamlined Off-Policy Learning
Oct 10, 2019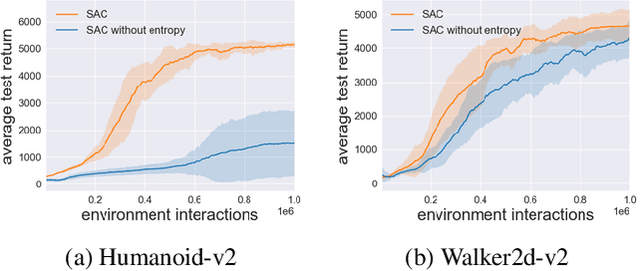



The field of Deep Reinforcement Learning (DRL) has recently seen a surge in the popularity of maximum entropy reinforcement learning algorithms. Their popularity stems from the intuitive interpretation of the maximum entropy objective and their superior sample efficiency on standard benchmarks. In this paper, we seek to understand the primary contribution of the entropy term to the performance of maximum entropy algorithms. For the Mujoco benchmark, we demonstrate that the entropy term in Soft Actor-Critic (SAC) principally addresses the bounded nature of the action spaces. With this insight, we propose a simple normalization scheme which allows a streamlined algorithm without entropy maximization match the performance of SAC. Our experimental results demonstrate a need to revisit the benefits of entropy regularization in DRL. We also propose a simple non-uniform sampling method for selecting transitions from the replay buffer during training. We further show that the streamlined algorithm with the simple non-uniform sampling scheme outperforms SAC and achieves state-of-the-art performance on challenging continuous control tasks.