 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Simplicity in Deep Reinforcement Learning: Streamlined Off-Policy Learning
Paper and Code
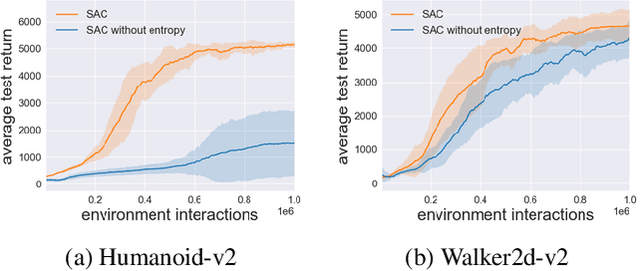



The field of Deep Reinforcement Learning (DRL) has recently seen a surge in the popularity of maximum entropy reinforcement learning algorithms. Their popularity stems from the intuitive interpretation of the maximum entropy objective and their superior sample efficiency on standard benchmarks. In this paper, we seek to understand the primary contribution of the entropy term to the performance of maximum entropy algorithms. For the Mujoco benchmark, we demonstrate that the entropy term in Soft Actor-Critic (SAC) principally addresses the bounded nature of the action spaces. With this insight, we propose a simple normalization scheme which allows a streamlined algorithm without entropy maximization match the performance of SAC. Our experimental results demonstrate a need to revisit the benefits of entropy regularization in DRL. We also propose a simple non-uniform sampling method for selecting transitions from the replay buffer during training. We further show that the streamlined algorithm with the simple non-uniform sampling scheme outperforms SAC and achieves state-of-the-art performance on challenging continuous control tasks.