 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Adjustment of HPA Parameters and Attack Prevention in Kubernetes Using Random Forests
Jan 20, 2026In this paper, HTTP status codes are used as custom metrics within the HPA as the experimental scenario. By integrating the Random Forest classification algorithm from machine learning, attacks are assessed and predicted, dynamically adjusting the maximum pod parameter in the HPA to manage attack traffic. This approach enables the adjustment of HPA parameters using machine learning scripts in targeted attack scenarios while effectively managing attack traffic. All access from attacking IPs is redirected to honeypot pods, achieving a lower incidence of 5XX status codes through HPA pod adjustments under high load conditions. This method also ensures effective isolation of attack traffic, preventing excessive HPA expansion due to attacks. Additionally, experiments conducted under various conditions demonstrate the importance of setting appropriate thresholds for HPA adjustments.
BAIL: Best-Action Imitation Learning for Batch Deep Reinforcement Learning
Oct 27, 2019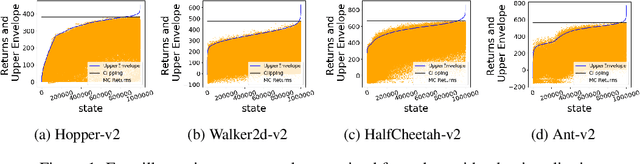

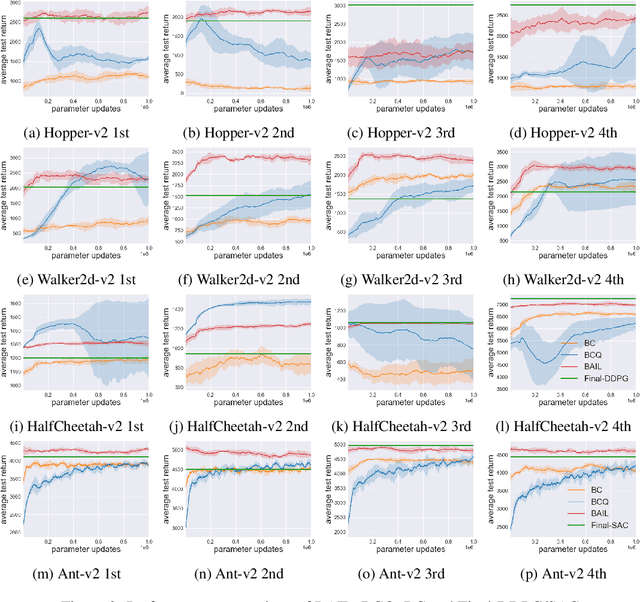

The field of Deep Reinforcement Learning (DRL) has recently seen a surge in research in batch reinforcement learning, which aims for sample-efficient learning from a given data set without additional interactions with the environment. In the batch DRL setting, commonly employed off-policy DRL algorithms can perform poorly and sometimes even fail to learn altogether. In this paper, we propose a new algorithm, Best-Action Imitation Learning (BAIL), which unlike many off-policy DRL algorithms does not involve maximizing Q functions over the action space. Striving for simplicity as well as performance, BAIL first selects from the batch the actions it believes to be high-performing actions for their corresponding states; it then uses those state-action pairs to train a policy network using imitation learning. Although BAIL is simple, we demonstrate that BAIL achieves state of the art performance on the Mujoco benchmark.