 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Monte Carlo UCB for Random-Length Episodic MDPs
Paper and Code
Sep 07, 2022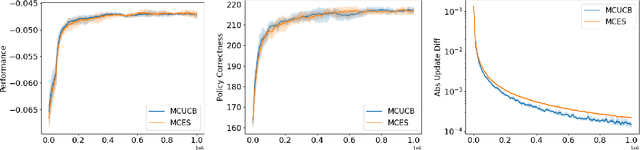
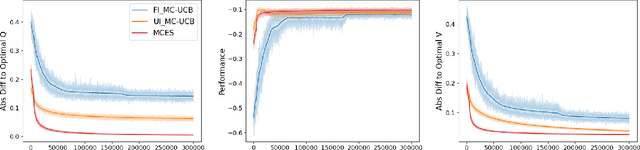
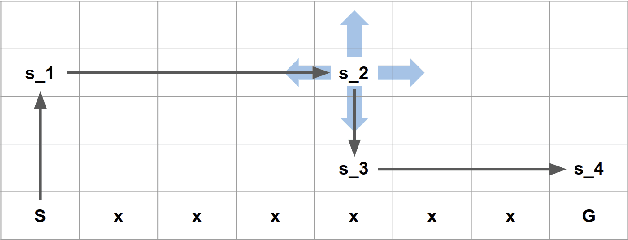
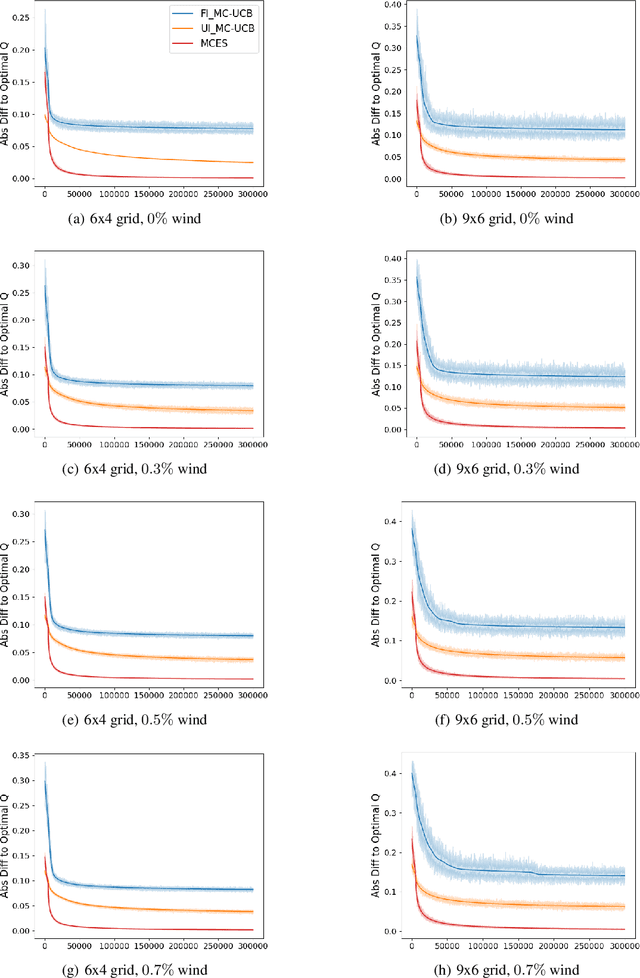
In reinforcement learning, Monte Carlo algorithms update the Q function by averaging the episodic returns. In the Monte Carlo UCB (MC-UCB) algorithm, the action taken in each state is the action that maximizes the Q function plus a UCB exploration term, which biases the choice of actions to those that have been chosen less frequently. Although there has been significant work on establishing regret bounds for MC-UCB, most of that work has been focused on finite-horizon versions of the problem, for which each episode terminates after a constant number of steps. For such finite-horizon problems, the optimal policy depends both on the current state and the time within the episode. However, for many natural episodic problems, such as games like Go and Chess and robotic tasks, the episode is of random length and the optimal policy is stationary. For such environments, it is an open question whether the Q-function in MC-UCB will converge to the optimal Q function; we conjecture that, unlike Q-learning, it does not converge for all MDPs. We nevertheless show that for a large class of MDPs, which includes stochastic MDPs such as blackjack and deterministic MDPs such as Go, the Q-function in MC-UCB converges almost surely to the optimal Q function. An immediate corollary of this result is that it also converges almost surely for all finite-horizon MDPs. We also provide numerical experiments, providing further insights into MC-UCB.