 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
Learning to Synthesize Volumetric Meshes from Vision-based Tactile Imprints
Mar 29, 2022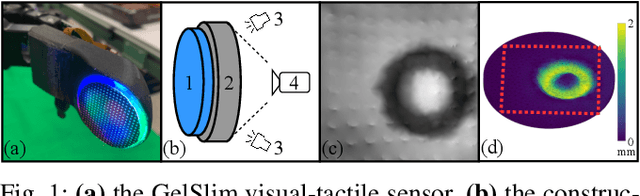



Vision-based tactile sensors typically utilize a deformable elastomer and a camera mounted above to provide high-resolution image observations of contacts. Obtaining accurate volumetric meshes for the deformed elastomer can provide direct contact information and benefit robotic grasping and manipulation. This paper focuses on learning to synthesize the volumetric mesh of the elastomer based on the image imprints acquired from vision-based tactile sensors. Synthetic image-mesh pairs and real-world images are gathered from 3D finite element methods (FEM) and physical sensors, respectively. A graph neural network (GNN) is introduced to learn the image-to-mesh mappings with supervised learning. A self-supervised adaptation method and image augmentation techniques are proposed to transfer networks from simulation to reality, from primitive contacts to unseen contacts, and from one sensor to another. Using these learned and adapted networks, our proposed method can accurately reconstruct the deformation of the real-world tactile sensor elastomer in various domains, as indicated by the quantitative and qualitative results.
Joint 3D Human Shape Recovery from A Single Imag with Bilayer-Graph
Oct 16, 2021



The ability to estimate the 3D human shape and pose from images can be useful in many contexts. Recent approaches have explored using graph convolutional networks and achieved promising results. The fact that the 3D shape is represented by a mesh, an undirected graph, makes graph convolutional networks a natural fit for this problem. However, graph convolutional networks have limited representation power. Information from nodes in the graph is passed to connected neighbors, and propagation of information requires successive graph convolutions. To overcome this limitation, we propose a dual-scale graph approach. We use a coarse graph, derived from a dense graph, to estimate the human's 3D pose, and the dense graph to estimate the 3D shape. Information in coarse graphs can be propagated over longer distances compared to dense graphs. In addition, information about pose can guide to recover local shape detail and vice versa. We recognize that the connection between coarse and dense is itself a graph, and introduce graph fusion blocks to exchange information between graphs with different scales. We train our model end-to-end and show that we can achieve state-of-the-art results for several evaluation datasets.
Cross-domain Imitation from Observations
May 20, 2021



Imitation learning seeks to circumvent the difficulty in designing proper reward functions for training agents by utilizing expert behavior. With environments modeled as Markov Decision Processes (MDP), most of the existing imitation algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitation policy is to be learned. In this paper, we study the problem of how to imitate tasks when there exist discrepancies between the expert and agent MDP. These discrepancies across domains could include differing dynamics, viewpoint, or morphology; we present a novel framework to learn correspondences across such domains. Importantly, in contrast to prior works, we use unpaired and unaligned trajectories containing only states in the expert domain, to learn this correspondence. We utilize a cycle-consistency constraint on both the state space and a domain agnostic latent space to do this. In addition, we enforce consistency on the temporal position of states via a normalized position estimator function, to align the trajectories across the two domains. Once this correspondence is found, we can directly transfer the demonstrations on one domain to the other and use it for imitation. Experiments across a wide variety of challenging domains demonstrate the efficacy of our approach.
Towards Human-Level Learning of Complex Physical Puzzles
Nov 14, 2020
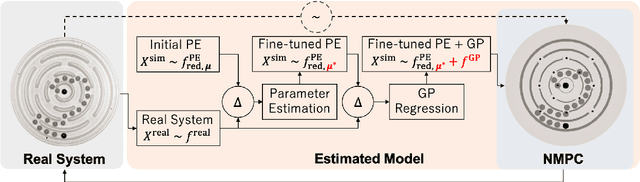
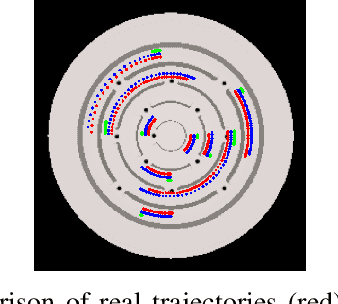
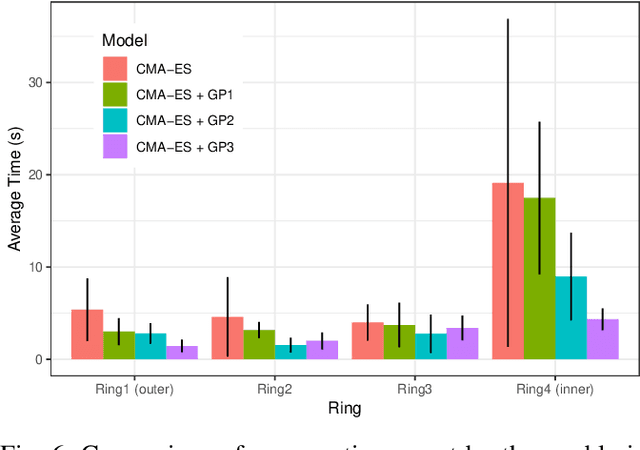
Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine equipped with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. We contrast the learning behavior against the time taken by humans to solve the problem to show comparable behavior. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC). Codes for the simulation environment can be downloaded here https://www.merl.com/research/license/CME . A video describing our method could be found here https://youtu.be/xaxNCXBovpc .
Learning from Trajectories via Subgoal Discovery
Nov 03, 2019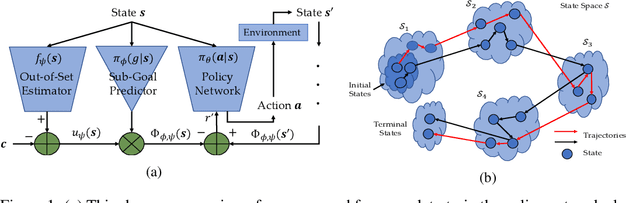

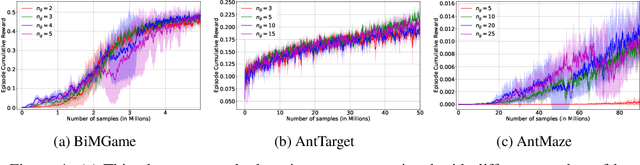
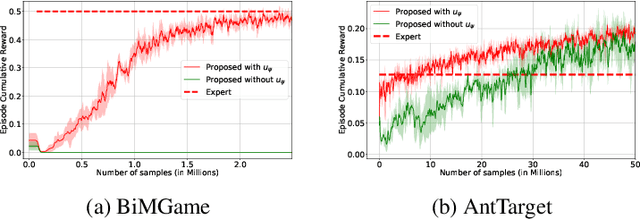
Learning to solve complex goal-oriented tasks with sparse terminal-only rewards often requires an enormous number of samples. In such cases, using a set of expert trajectories could help to learn faster. However, Imitation Learning (IL) via supervised pre-training with these trajectories may not perform as well and generally requires additional finetuning with expert-in-the-loop. In this paper, we propose an approach which uses the expert trajectories and learns to decompose the complex main task into smaller sub-goals. We learn a function which partitions the state-space into sub-goals, which can then be used to design an extrinsic reward function. We follow a strategy where the agent first learns from the trajectories using IL and then switches to Reinforcement Learning (RL) using the identified sub-goals, to alleviate the errors in the IL step. To deal with states which are under-represented by the trajectory set, we also learn a function to modulate the sub-goal predictions. We show that our method is able to solve complex goal-oriented tasks, which other RL, IL or their combinations in literature are not able to solve.
Trajectory-based Learning for Ball-in-Maze Games
Nov 28, 2018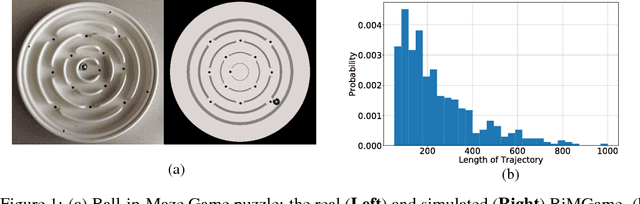

Deep Reinforcement Learning has shown tremendous success in solving several games and tasks in robotics. However, unlike humans, it generally requires a lot of training instances. Trajectories imitating to solve the task at hand can help to increase sample-efficiency of deep RL methods. In this paper, we present a simple approach to use such trajectories, applied to the challenging Ball-in-Maze Games, recently introduced in the literature. We show that in spite of not using human-generated trajectories and just using the simulator as a model to generate a limited number of trajectories, we can get a speed-up of about 2-3x in the learning process. We also discuss some challenges we observed while using trajectory-based learning for very sparse reward functions.
Sim-to-Real Transfer Learning using Robustified Controllers in Robotic Tasks involving Complex Dynamics
Sep 17, 2018
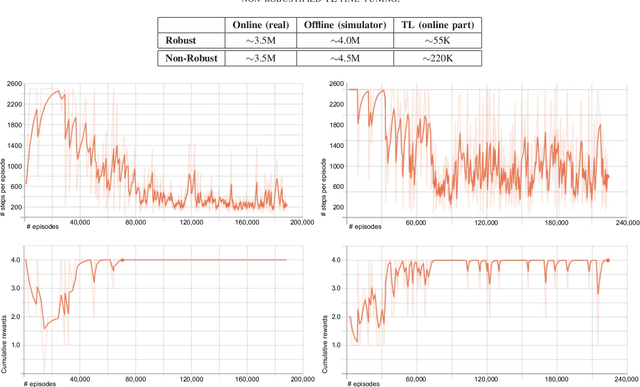
Learning robot tasks or controllers using deep reinforcement learning has been proven effective in simulations. Learning in simulation has several advantages. For example, one can fully control the simulated environment, including halting motions while performing computations. Another advantage when robots are involved, is that the amount of time a robot is occupied learning a task---rather than being productive---can be reduced by transferring the learned task to the real robot. Transfer learning requires some amount of fine-tuning on the real robot. For tasks which involve complex (non-linear) dynamics, the fine-tuning itself may take a substantial amount of time. In order to reduce the amount of fine-tuning we propose to learn robustified controllers in simulation. Robustified controllers are learned by exploiting the ability to change simulation parameters (both appearance and dynamics) for successive training episodes. An additional benefit for this approach is that it alleviates the precise determination of physics parameters for the simulator, which is a non-trivial task. We demonstrate our proposed approach on a real setup in which a robot aims to solve a maze game, which involves complex dynamics due to static friction and potentially large accelerations. We show that the amount of fine-tuning in transfer learning for a robustified controller is substantially reduced compared to a non-robustified controller.