 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real Transfer Learning using Robustified Controllers in Robotic Tasks involving Complex Dynamics
Sep 17, 2018
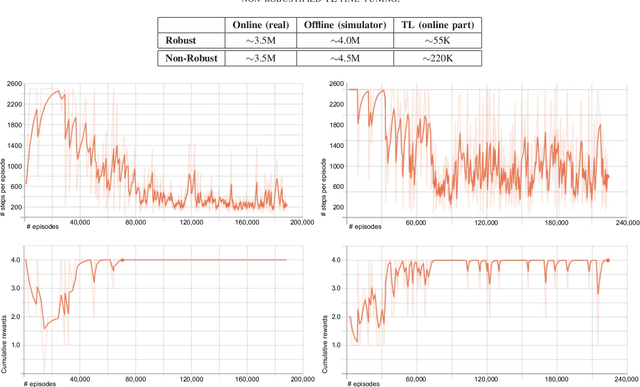
Learning robot tasks or controllers using deep reinforcement learning has been proven effective in simulations. Learning in simulation has several advantages. For example, one can fully control the simulated environment, including halting motions while performing computations. Another advantage when robots are involved, is that the amount of time a robot is occupied learning a task---rather than being productive---can be reduced by transferring the learned task to the real robot. Transfer learning requires some amount of fine-tuning on the real robot. For tasks which involve complex (non-linear) dynamics, the fine-tuning itself may take a substantial amount of time. In order to reduce the amount of fine-tuning we propose to learn robustified controllers in simulation. Robustified controllers are learned by exploiting the ability to change simulation parameters (both appearance and dynamics) for successive training episodes. An additional benefit for this approach is that it alleviates the precise determination of physics parameters for the simulator, which is a non-trivial task. We demonstrate our proposed approach on a real setup in which a robot aims to solve a maze game, which involves complex dynamics due to static friction and potentially large accelerations. We show that the amount of fine-tuning in transfer learning for a robustified controller is substantially reduced compared to a non-robustified controller.