 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Dynamics Estimation from Data-Driven Inverse Dynamics Learning
Jul 11, 2023


In this paper, we propose to estimate the forward dynamics equations of mechanical systems by learning a model of the inverse dynamics and estimating individual dynamics components from it. We revisit the classical formulation of rigid body dynamics in order to extrapolate the physical dynamical components, such as inertial and gravitational components, from an inverse dynamics model. After estimating the dynamical components, the forward dynamics can be computed in closed form as a function of the learned inverse dynamics. We tested the proposed method with several machine learning models based on Gaussian Process Regression and compared them with the standard approach of learning the forward dynamics directly. Results on two simulated robotic manipulators, a PANDA Franka Emika and a UR10, show the effectiveness of the proposed method in learning the forward dynamics, both in terms of accuracy as well as in opening the possibility of using more structured~models.
Learning Object Manipulation With Under-Actuated Impulse Generator Arrays
Mar 06, 2023



For more than half a century, vibratory bowl feeders have been the standard in automated assembly for singulation, orientation, and manipulation of small parts. Unfortunately, these feeders are expensive, noisy, and highly specialized on a single part design bases. We consider an alternative device and learning control method for singulation, orientation, and manipulation by means of seven fixed-position variable-energy solenoid impulse actuators located beneath a semi-rigid part supporting surface. Using computer vision to provide part pose information, we tested various machine learning (ML) algorithms to generate a control policy that selects the optimal actuator and actuation energy. Our manipulation test object is a 6-sided craps-style die. Using the most suitable ML algorithm, we were able to flip the die to any desired face 30.4\% of the time with a single impulse, and 51.3\% with two chosen impulses, versus a random policy succeeding 5.1\% of the time (that is, a randomly chosen impulse delivered by a randomly chosen solenoid).
Learning Control from Raw Position Measurements
Jan 30, 2023We propose a Model-Based Reinforcement Learning (MBRL) algorithm named VF-MC-PILCO, specifically designed for application to mechanical systems where velocities cannot be directly measured. This circumstance, if not adequately considered, can compromise the success of MBRL approaches. To cope with this problem, we define a velocity-free state formulation which consists of the collection of past positions and inputs. Then, VF-MC-PILCO uses Gaussian Process Regression to model the dynamics of the velocity-free state and optimizes the control policy through a particle-based policy gradient approach. We compare VF-MC-PILCO with our previous MBRL algorithm, MC-PILCO4PMS, which handles the lack of direct velocity measurements by modeling the presence of velocity estimators. Results on both simulated (cart-pole and UR5 robot) and real mechanical systems (Furuta pendulum and a ball-and-plate rig) show that the two algorithms achieve similar results. Conveniently, VF-MC-PILCO does not require the design and implementation of state estimators, which can be a challenging and time-consuming activity to be performed by an expert user.
Generalizable Human-Robot Collaborative Assembly Using Imitation Learning and Force Control
Dec 02, 2022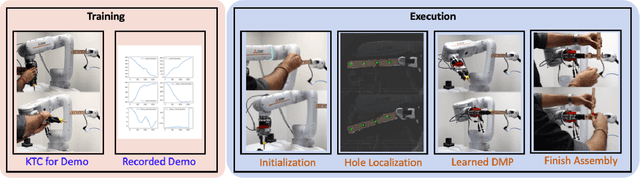
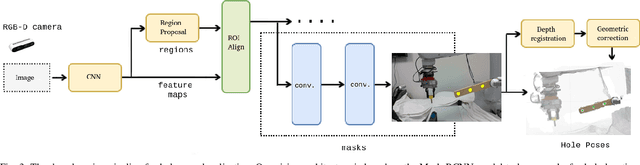

Robots have been steadily increasing their presence in our daily lives, where they can work along with humans to provide assistance in various tasks on industry floors, in offices, and in homes. Automated assembly is one of the key applications of robots, and the next generation assembly systems could become much more efficient by creating collaborative human-robot systems. However, although collaborative robots have been around for decades, their application in truly collaborative systems has been limited. This is because a truly collaborative human-robot system needs to adjust its operation with respect to the uncertainty and imprecision in human actions, ensure safety during interaction, etc. In this paper, we present a system for human-robot collaborative assembly using learning from demonstration and pose estimation, so that the robot can adapt to the uncertainty caused by the operation of humans. Learning from demonstration is used to generate motion trajectories for the robot based on the pose estimate of different goal locations from a deep learning-based vision system. The proposed system is demonstrated using a physical 6 DoF manipulator in a collaborative human-robot assembly scenario. We show successful generalization of the system's operation to changes in the initial and final goal locations through various experiments.
Constrained Dynamic Movement Primitives for Safe Learning of Motor Skills
Sep 28, 2022
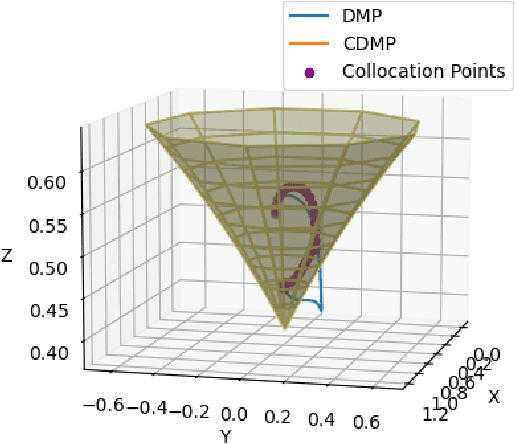
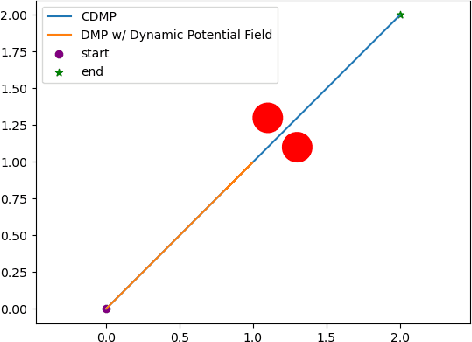
Dynamic movement primitives are widely used for learning skills which can be demonstrated to a robot by a skilled human or controller. While their generalization capabilities and simple formulation make them very appealing to use, they possess no strong guarantees to satisfy operational safety constraints for a task. In this paper, we present constrained dynamic movement primitives (CDMP) which can allow for constraint satisfaction in the robot workspace. We present a formulation of a non-linear optimization to perturb the DMP forcing weights regressed by locally-weighted regression to admit a Zeroing Barrier Function (ZBF), which certifies workspace constraint satisfaction. We demonstrate the proposed CDMP under different constraints on the end-effector movement such as obstacle avoidance and workspace constraints on a physical robot. A video showing the implementation of the proposed algorithm using different manipulators in different environments could be found here https://youtu.be/hJegJJkJfys.
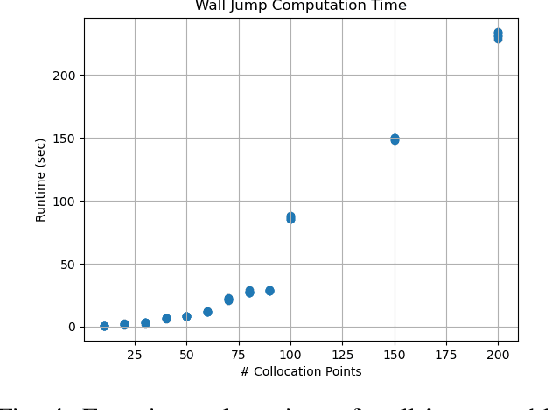
Transformer Networks for Predictive Group Elevator Control
Aug 15, 2022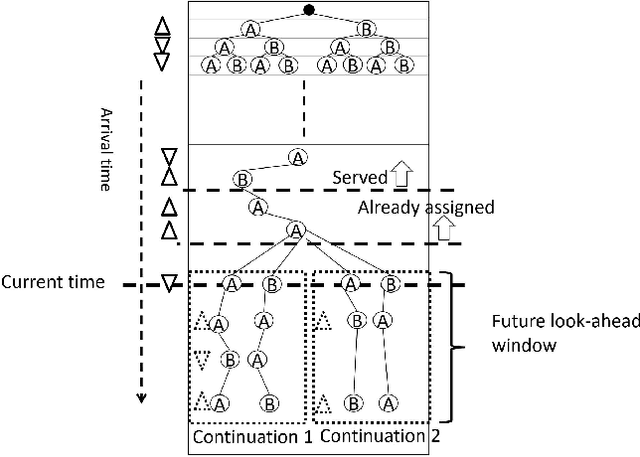
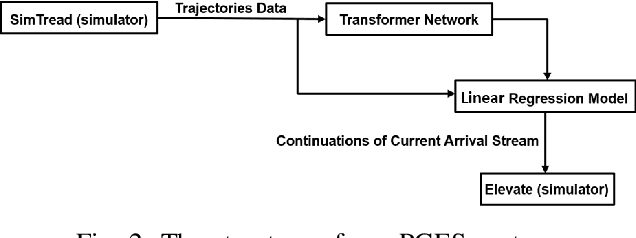
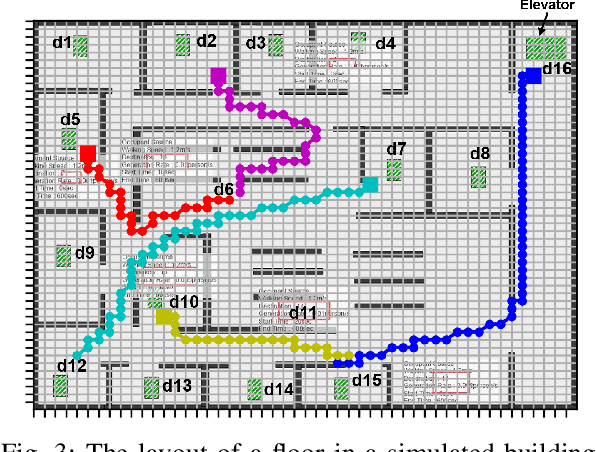
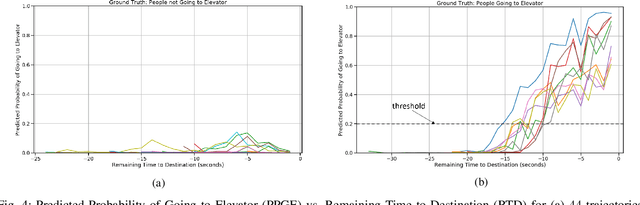
We propose a Predictive Group Elevator Scheduler by using predictive information of passengers arrivals from a Transformer based destination predictor and a linear regression model that predicts remaining time to destinations. Through extensive empirical evaluation, we find that the savings of Average Waiting Time (AWT) could be as high as above 50% for light arrival streams and around 15% for medium arrival streams in afternoon down-peak traffic regimes. Such results can be obtained after carefully setting the Predicted Probability of Going to Elevator (PPGE) threshold, thus avoiding a majority of false predictions for people heading to the elevator, while achieving as high as 80% of true predictive elevator landings as early as after having seen only 60% of the whole trajectory of a passenger.
Design of Adaptive Compliance Controllers for Safe Robotic Assembly
Apr 22, 2022
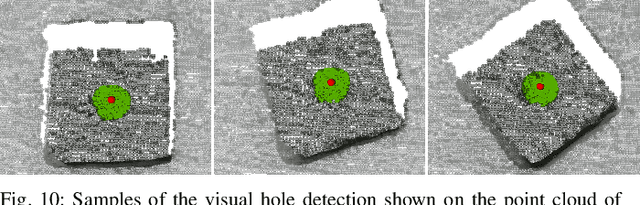

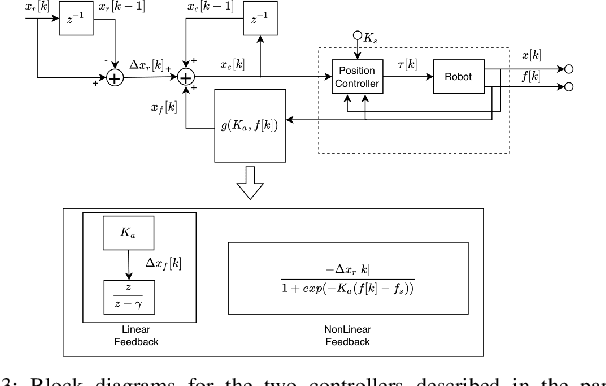
Insertion operations are a critical element of most robotic assembly operation, and peg-in-hole (PiH) insertion is one of the most widely studied tasks in the industrial and academic manipulation communities. PiH insertion is in fact an entire class of problems, where the complexity of the problem can depend on the type of misalignment and contact formation during an insertion attempt. In this paper, we present the design and analysis of adaptive compliance controllers which can be used in insertion-type assembly tasks, including learning-based compliance controllers which can be used for insertion problems in the presence of uncertainty in the goal location during robotic assembly. We first present the design of compliance controllers which can ensure safe operation of the robot by limiting experienced contact forces during contact formation. Consequently, we present analysis of the force signature obtained during the contact formation to learn the corrective action needed to perform insertion. Finally, we use the proposed compliance controllers and learned models to design a policy that can successfully perform insertion in novel test conditions with almost perfect success rate. We validate the proposed approach on a physical robotic test-bed using a 6-DoF manipulator arm.
Imitation and Supervised Learning of Compliance for Robotic Assembly
Nov 20, 2021


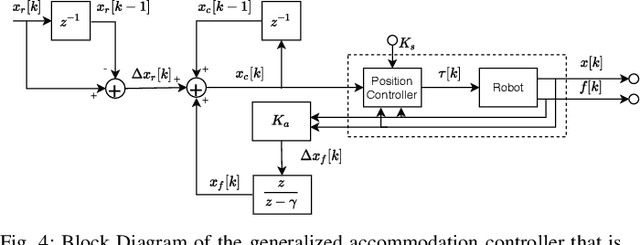
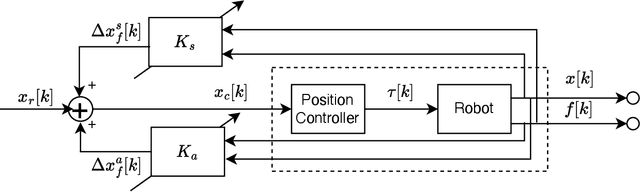
We present the design of a learning-based compliance controller for assembly operations for industrial robots. We propose a solution within the general setting of learning from demonstration (LfD), where a nominal trajectory is provided through demonstration by an expert teacher. This can be used to learn a suitable representation of the skill that can be generalized to novel positions of one of the parts involved in the assembly, for example the hole in a peg-in-hole (PiH) insertion task. Under the expectation that this novel position might not be entirely accurately estimated by a vision or other sensing system, the robot will need to further modify the generated trajectory in response to force readings measured by means of a force-torque (F/T) sensor mounted at the wrist of the robot or another suitable location. Under the assumption of constant velocity of traversing the reference trajectory during assembly, we propose a novel accommodation force controller that allows the robot to safely explore different contact configurations. The data collected using this controller is used to train a Gaussian process model to predict the misalignment in the position of the peg with respect to the target hole. We show that the proposed learning-based approach can correct various contact configurations caused by misalignment between the assembled parts in a PiH task, achieving high success rate during insertion. We show results using an industrial manipulator arm, and demonstrate that the proposed method can perform adaptive insertion using force feedback from the trained machine learning models.
Control of Mechanical Systems via Feedback Linearization Based on Black-Box Gaussian Process Models
May 02, 2021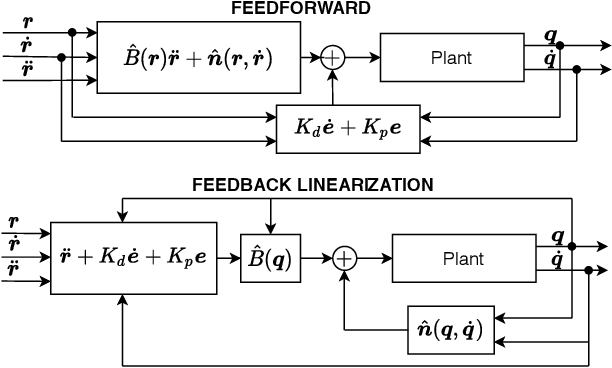
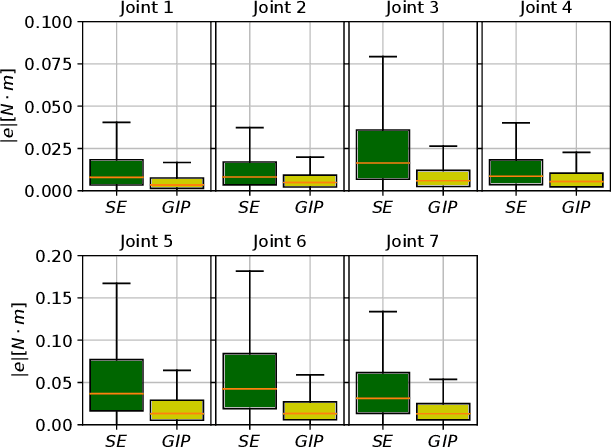
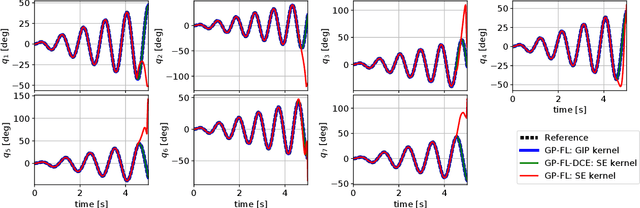
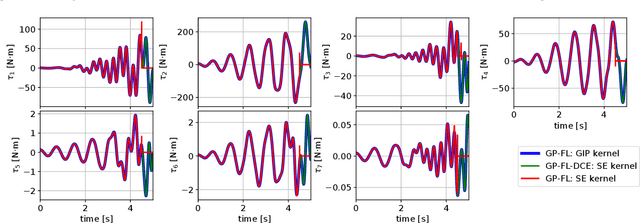
In this paper, we consider the use of black-box Gaussian process (GP) models for trajectory tracking control based on feedback linearization, in the context of mechanical systems. We considered two strategies. The first computes the control input directly by using the GP model, whereas the second computes the input after estimating the individual components of the dynamics. We tested the two strategies on a simulated manipulator with seven degrees of freedom, also varying the GP kernel choice. Results show that the second implementation is more robust w.r.t. the kernel choice and model inaccuracies. Moreover, as regards the choice of kernel, the obtained performance shows that the use of a structured kernel, such as a polynomial kernel, is advantageous, because of its effectiveness with both strategies.
Tactile-RL for Insertion: Generalization to Objects of Unknown Geometry
Apr 02, 2021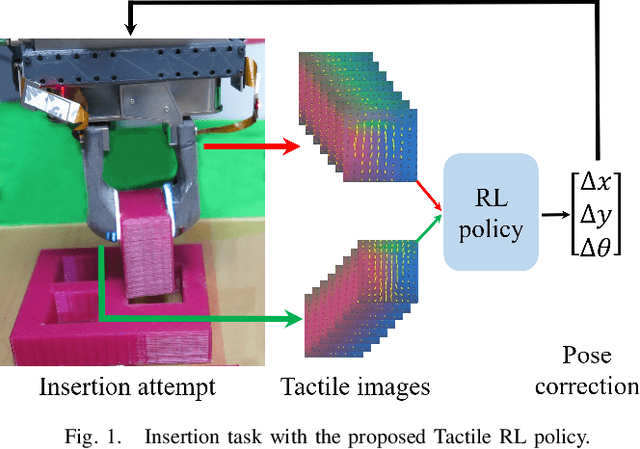
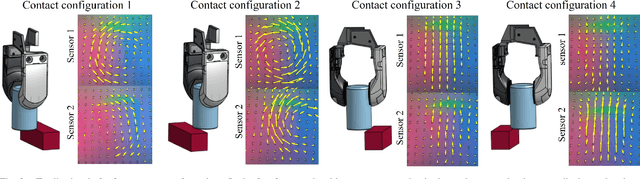
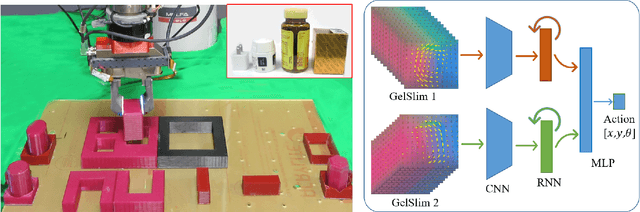
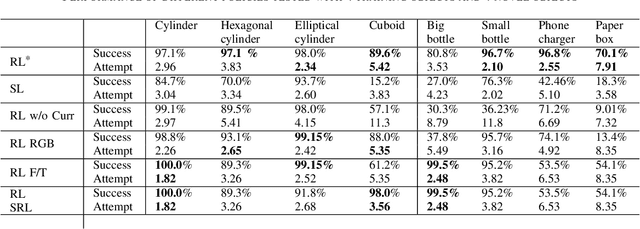
Object insertion is a classic contact-rich manipulation task. The task remains challenging, especially when considering general objects of unknown geometry, which significantly limits the ability to understand the contact configuration between the object and the environment. We study the problem of aligning the object and environment with a tactile-based feedback insertion policy. The insertion process is modeled as an episodic policy that iterates between insertion attempts followed by pose corrections. We explore different mechanisms to learn such a policy based on Reinforcement Learning. The key contribution of this paper is to demonstrate that it is possible to learn a tactile insertion policy that generalizes across different object geometries, and an ablation study of the key design choices for the learning agent: 1) the type of learning scheme: supervised vs. reinforcement learning; 2) the type of learning schedule: unguided vs. curriculum learning; 3) the type of sensing modality: force/torque (F/T) vs. tactile; and 4) the type of tactile representation: tactile RGB vs. tactile flow. We show that the optimal configuration of the learning agent (RL + curriculum + tactile flow) exposed to 4 training objects yields an insertion policy that inserts 4 novel objects with over 85.0% success rate and within 3~4 attempts. Comparisons between F/T and tactile sensing, shows that while an F/T-based policy learns more efficiently, a tactile-based policy provides better generalization.