 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWARP: Whole-Body Retargeting for Learning from Offline Human Demonstrations
Jun 29, 2026Direct transfer from human demonstration to learnable robot action is a crucial step towards scalable whole-body mobile manipulation. While human data scales better than mobile teleoperation, it requires overcoming significant embodiment gaps. Existing retargeting methods yield imprecise or inconsistent solutions, causing action multi-modality that prevents supervised policies from reliably converging. We present Whole-body-Aware Retargeting from human Pose (WARP), an offline pipeline that explicitly models embodiment differences to extract precise, unique whole-body actions. WARP leverages a closed-form Shoulder-Elbow-Wrist (SEW) geometric solver for exact end-effector tracking while preserving whole-body structural intent. Paired with lazy mobile-base control, it extracts accurate, consistent robot trajectories. Evaluations show WARP provides highly reliable data for open-loop real-world replay. To our knowledge, WARP is the first framework to achieve zero-shot whole-body mobile manipulation directly from offline human demonstrations, eliminating the need for human-in-the-loop teleoperation action data. More details on https://warp-retarget.github.io/
Going with the Flow: Koopman Behavioral Models as Implicit Planners for Visuo-Motor Dexterity
Feb 07, 2026There has been rapid and dramatic progress in robots' ability to learn complex visuo-motor manipulation skills from demonstrations, thanks in part to expressive policy classes that employ diffusion- and transformer-based backbones. However, these design choices require significant data and computational resources and remain far from reliable, particularly within the context of multi-fingered dexterous manipulation. Fundamentally, they model skills as reactive mappings and rely on fixed-horizon action chunking to mitigate jitter, creating a rigid trade-off between temporal coherence and reactivity. In this work, we introduce Unified Behavioral Models (UBMs), a framework that learns to represent dexterous skills as coupled dynamical systems that capture how visual features of the environment (visual flow) and proprioceptive states of the robot (action flow) co-evolve. By capturing such behavioral dynamics, UBMs can ensure temporal coherence by construction rather than by heuristic averaging. To operationalize these models, we propose Koopman-UBM, a first instantiation of UBMs that leverages Koopman Operator theory to effectively learn a unified representation in which the joint flow of latent visual and proprioceptive features is governed by a structured linear system. We demonstrate that Koopman-UBM can be viewed as an implicit planner: given an initial condition, it analytically computes the desired robot behavior while simultaneously ''imagining'' the resulting flow of visual features over the entire skill horizon. To enable reactivity and adaptation, we introduce an online replanning strategy in which the model acts as its own runtime monitor that automatically triggers replanning when predicted and observed visual flow diverge beyond a threshold. Across seven simulated tasks and two real-world tasks, we demonstrate that K-UBM matches or exceeds the performance of state-of-the-art baselines, while offering considerably faster inference, smooth execution, robustness to occlusions, and flexible replanning.
A Closed-Form Geometric Retargeting Solver for Upper Body Humanoid Robot Teleoperation
Feb 02, 2026Retargeting human motion to robot poses is a practical approach for teleoperating bimanual humanoid robot arms, but existing methods can be suboptimal and slow, often causing undesirable motion or latency. This is due to optimizing to match robot end-effector to human hand position and orientation, which can also limit the robot's workspace to that of the human. Instead, this paper reframes retargeting as an orientation alignment problem, enabling a closed-form, geometric solution algorithm with an optimality guarantee. The key idea is to align a robot arm to a human's upper and lower arm orientations, as identified from shoulder, elbow, and wrist (SEW) keypoints; hence, the method is called SEW-Mimic. The method has fast inference (3 kHz) on standard commercial CPUs, leaving computational overhead for downstream applications; an example in this paper is a safety filter to avoid bimanual self-collision. The method suits most 7-degree-of-freedom robot arms and humanoids, and is agnostic to input keypoint source. Experiments show that SEW-Mimic outperforms other retargeting methods in computation time and accuracy. A pilot user study suggests that the method improves teleoperation task success. Preliminary analysis indicates that data collected with SEW-Mimic improves policy learning due to being smoother. SEW-Mimic is also shown to be a drop-in way to accelerate full-body humanoid retargeting. Finally, hardware demonstrations illustrate SEW-Mimic's practicality. The results emphasize the utility of SEW-Mimic as a fundamental building block for bimanual robot manipulation and humanoid robot teleoperation.
Goal-Reaching Trajectory Design Near Danger with Piecewise Affine Reach-avoid Computation
Feb 23, 2024

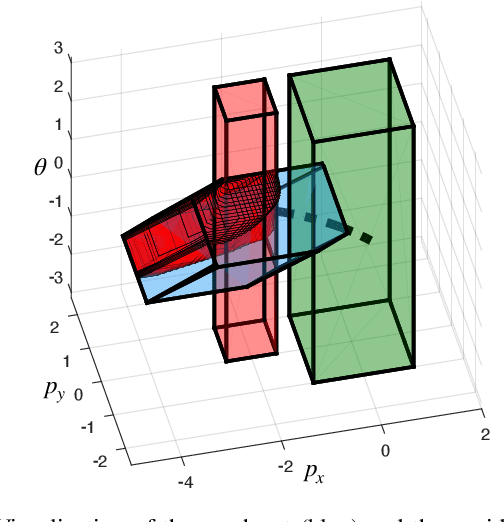
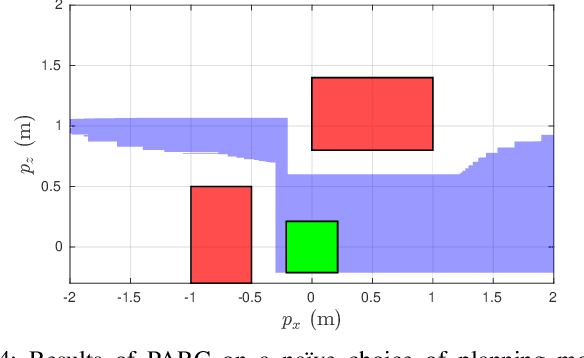
Autonomous mobile robots must maintain safety, but should not sacrifice performance, leading to the classical reach-avoid problem. This paper seeks to compute trajectory plans for which a robot is guaranteed to reach a goal and avoid obstacles in the specific near-danger case that the obstacles and goal are near each other. The proposed method builds off of a common approach of using a simplified planning model to generate plans, which are then tracked using a high-fidelity tracking model and controller. Existing safe planning approaches use reachability analysis to overapproximate the error between these models, but this introduces additional numerical approximation error and thereby conservativeness that prevents goal-reaching. The present work instead proposes a Piecewise Affine Reach-avoid Computation (PARC) method to tightly approximate the reachable set of the planning model. With PARC, the main source of conservativeness is the model mismatch, which can be mitigated by careful controller and planning model design. The utility of this method is demonstrated through extensive numerical experiments in which PARC outperforms state-of-the-art reach-avoid methods in near-danger goal-reaching. Furthermore, in a simulated demonstration, PARC enables the generation of provably-safe extreme vehicle dynamics drift parking maneuvers.
Learning Object Manipulation With Under-Actuated Impulse Generator Arrays
Mar 06, 2023



For more than half a century, vibratory bowl feeders have been the standard in automated assembly for singulation, orientation, and manipulation of small parts. Unfortunately, these feeders are expensive, noisy, and highly specialized on a single part design bases. We consider an alternative device and learning control method for singulation, orientation, and manipulation by means of seven fixed-position variable-energy solenoid impulse actuators located beneath a semi-rigid part supporting surface. Using computer vision to provide part pose information, we tested various machine learning (ML) algorithms to generate a control policy that selects the optimal actuator and actuation energy. Our manipulation test object is a 6-sided craps-style die. Using the most suitable ML algorithm, we were able to flip the die to any desired face 30.4\% of the time with a single impulse, and 51.3\% with two chosen impulses, versus a random policy succeeding 5.1\% of the time (that is, a randomly chosen impulse delivered by a randomly chosen solenoid).