 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closed-Form Geometric Retargeting Solver for Upper Body Humanoid Robot Teleoperation
Feb 02, 2026Retargeting human motion to robot poses is a practical approach for teleoperating bimanual humanoid robot arms, but existing methods can be suboptimal and slow, often causing undesirable motion or latency. This is due to optimizing to match robot end-effector to human hand position and orientation, which can also limit the robot's workspace to that of the human. Instead, this paper reframes retargeting as an orientation alignment problem, enabling a closed-form, geometric solution algorithm with an optimality guarantee. The key idea is to align a robot arm to a human's upper and lower arm orientations, as identified from shoulder, elbow, and wrist (SEW) keypoints; hence, the method is called SEW-Mimic. The method has fast inference (3 kHz) on standard commercial CPUs, leaving computational overhead for downstream applications; an example in this paper is a safety filter to avoid bimanual self-collision. The method suits most 7-degree-of-freedom robot arms and humanoids, and is agnostic to input keypoint source. Experiments show that SEW-Mimic outperforms other retargeting methods in computation time and accuracy. A pilot user study suggests that the method improves teleoperation task success. Preliminary analysis indicates that data collected with SEW-Mimic improves policy learning due to being smoother. SEW-Mimic is also shown to be a drop-in way to accelerate full-body humanoid retargeting. Finally, hardware demonstrations illustrate SEW-Mimic's practicality. The results emphasize the utility of SEW-Mimic as a fundamental building block for bimanual robot manipulation and humanoid robot teleoperation.
Joint Model-based Model-free Diffusion for Planning with Constraints
Sep 10, 2025Model-free diffusion planners have shown great promise for robot motion planning, but practical robotic systems often require combining them with model-based optimization modules to enforce constraints, such as safety. Naively integrating these modules presents compatibility challenges when diffusion's multi-modal outputs behave adversarially to optimization-based modules. To address this, we introduce Joint Model-based Model-free Diffusion (JM2D), a novel generative modeling framework. JM2D formulates module integration as a joint sampling problem to maximize compatibility via an interaction potential, without additional training. Using importance sampling, JM2D guides modules outputs based only on evaluations of the interaction potential, thus handling non-differentiable objectives commonly arising from non-convex optimization modules. We evaluate JM2D via application to aligning diffusion planners with safety modules on offline RL and robot manipulation. JM2D significantly improves task performance compared to conventional safety filters without sacrificing safety. Further, we show that conditional generation is a special case of JM2D and elucidate key design choices by comparing with SOTA gradient-based and projection-based diffusion planners. More details at: https://jm2d-corl25.github.io/.
SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies
Jun 13, 2025Offline Imitation Learning (IL) methods such as Behavior Cloning are effective at acquiring complex robotic manipulation skills. However, existing IL-trained policies are confined to executing the task at the same speed as shown in demonstration data. This limits the task throughput of a robotic system, a critical requirement for applications such as industrial automation. In this paper, we introduce and formalize the novel problem of enabling faster-than-demonstration execution of visuomotor policies and identify fundamental challenges in robot dynamics and state-action distribution shifts. We instantiate the key insights as SAIL (Speed Adaptation for Imitation Learning), a full-stack system integrating four tightly-connected components: (1) a consistency-preserving action inference algorithm for smooth motion at high speed, (2) high-fidelity tracking of controller-invariant motion targets, (3) adaptive speed modulation that dynamically adjusts execution speed based on motion complexity, and (4) action scheduling to handle real-world system latencies. Experiments on 12 tasks across simulation and two real, distinct robot platforms show that SAIL achieves up to a 4x speedup over demonstration speed in simulation and up to 3.2x speedup in the real world. Additional detail is available at https://nadunranawaka1.github.io/sail-policy
RAIL: Reachability-Aided Imitation Learning for Safe Policy Execution
Sep 28, 2024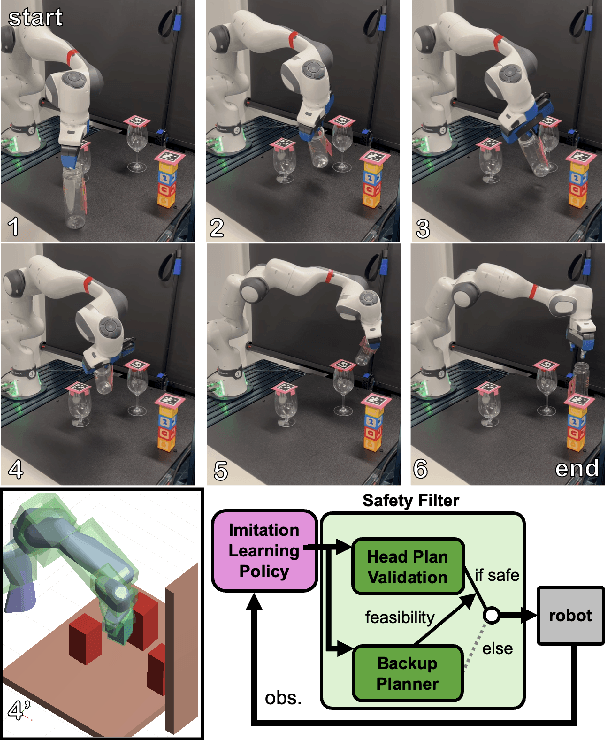


Imitation learning (IL) has shown great success in learning complex robot manipulation tasks. However, there remains a need for practical safety methods to justify widespread deployment. In particular, it is important to certify that a system obeys hard constraints on unsafe behavior in settings when it is unacceptable to design a tradeoff between performance and safety via tuning the policy (i.e. soft constraints). This leads to the question, how does enforcing hard constraints impact the performance (meaning safely completing tasks) of an IL policy? To answer this question, this paper builds a reachability-based safety filter to enforce hard constraints on IL, which we call Reachability-Aided Imitation Learning (RAIL). Through evaluations with state-of-the-art IL policies in mobile robots and manipulation tasks, we make two key findings. First, the highest-performing policies are sometimes only so because they frequently violate constraints, and significantly lose performance under hard constraints. Second, surprisingly, hard constraints on the lower-performing policies can occasionally increase their ability to perform tasks safely. Finally, hardware evaluation confirms the method can operate in real time.
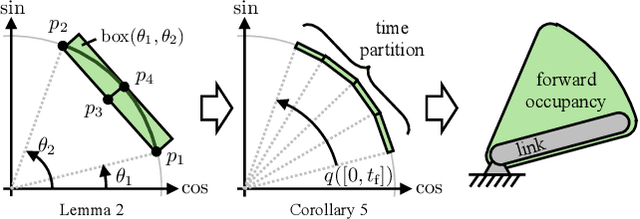
Goal-Reaching Trajectory Design Near Danger with Piecewise Affine Reach-avoid Computation
Feb 23, 2024

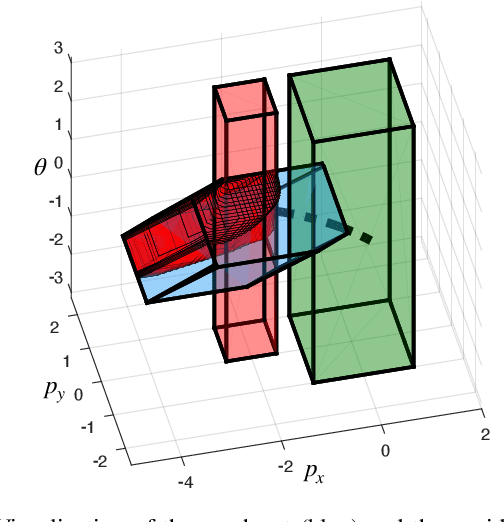
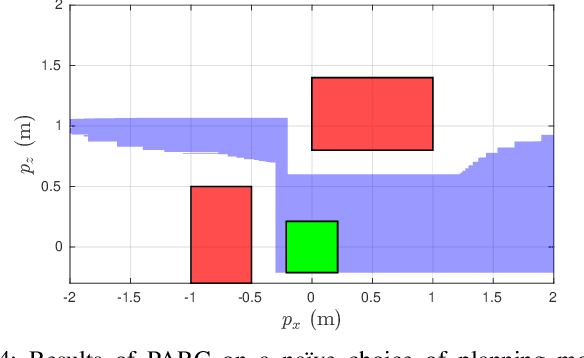
Autonomous mobile robots must maintain safety, but should not sacrifice performance, leading to the classical reach-avoid problem. This paper seeks to compute trajectory plans for which a robot is guaranteed to reach a goal and avoid obstacles in the specific near-danger case that the obstacles and goal are near each other. The proposed method builds off of a common approach of using a simplified planning model to generate plans, which are then tracked using a high-fidelity tracking model and controller. Existing safe planning approaches use reachability analysis to overapproximate the error between these models, but this introduces additional numerical approximation error and thereby conservativeness that prevents goal-reaching. The present work instead proposes a Piecewise Affine Reach-avoid Computation (PARC) method to tightly approximate the reachable set of the planning model. With PARC, the main source of conservativeness is the model mismatch, which can be mitigated by careful controller and planning model design. The utility of this method is demonstrated through extensive numerical experiments in which PARC outperforms state-of-the-art reach-avoid methods in near-danger goal-reaching. Furthermore, in a simulated demonstration, PARC enables the generation of provably-safe extreme vehicle dynamics drift parking maneuvers.
Constraint-Guided Online Data Selection for Scalable Data-Driven Safety Filters in Uncertain Robotic Systems
Nov 23, 2023As the use of autonomous robotic systems expands in tasks that are complex and challenging to model, the demand for robust data-driven control methods that can certify safety and stability in uncertain conditions is increasing. However, the practical implementation of these methods often faces scalability issues due to the growing amount of data points with system complexity, and a significant reliance on high-quality training data. In response to these challenges, this study presents a scalable data-driven controller that efficiently identifies and infers from the most informative data points for implementing data-driven safety filters. Our approach is grounded in the integration of a model-based certificate function-based method and Gaussian Process (GP) regression, reinforced by a novel online data selection algorithm that reduces time complexity from quadratic to linear relative to dataset size. Empirical evidence, gathered from successful real-world cart-pole swing-up experiments and simulated locomotion of a five-link bipedal robot, demonstrates the efficacy of our approach. Our findings reveal that our efficient online data selection algorithm, which strategically selects key data points, enhances the practicality and efficiency of data-driven certifying filters in complex robotic systems, significantly mitigating scalability concerns inherent in nonparametric learning-based control methods.
Probabilistic Safe Online Learning with Control Barrier Functions
Aug 23, 2022

Learning-based control schemes have recently shown great efficacy performing complex tasks. However, in order to deploy them in real systems, it is of vital importance to guarantee that the system will remain safe during online training and execution. We therefore need safe online learning frameworks able to autonomously reason about whether the current information at their disposal is enough to ensure safety or, in contrast, new measurements are required. In this paper, we present a framework consisting of two parts: first, an out-of-distribution detection mechanism actively collecting measurements when needed to guarantee that at least one safety backup direction is always available for use; and second, a Gaussian Process-based probabilistic safety-critical controller that ensures the system stays safe at all times with high probability. Our method exploits model knowledge through the use of Control Barrier Functions, and collects measurements from the stream of online data in an event-triggered fashion to guarantee recursive feasibility of the learned safety-critical controller. This, in turn, allows us to provide formal results of forward invariance of a safe set with high probability, even in a priori unexplored regions. Finally, we validate the proposed framework in numerical simulations of an adaptive cruise control system.