 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIL: Reachability-Aided Imitation Learning for Safe Policy Execution
Paper and Code
Sep 28, 2024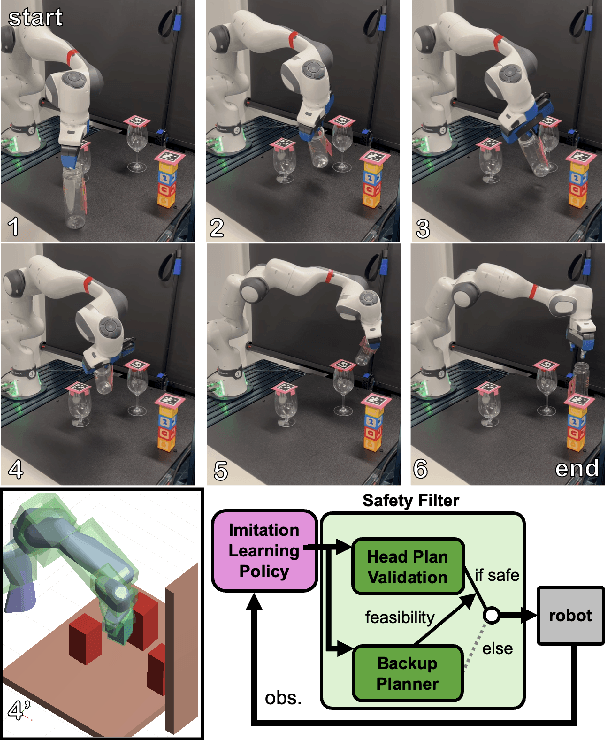
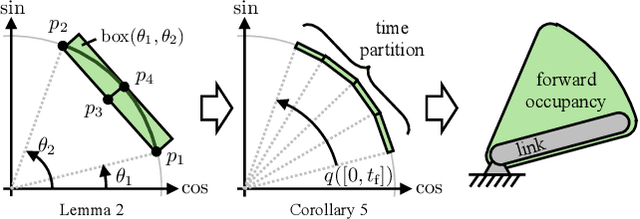


Imitation learning (IL) has shown great success in learning complex robot manipulation tasks. However, there remains a need for practical safety methods to justify widespread deployment. In particular, it is important to certify that a system obeys hard constraints on unsafe behavior in settings when it is unacceptable to design a tradeoff between performance and safety via tuning the policy (i.e. soft constraints). This leads to the question, how does enforcing hard constraints impact the performance (meaning safely completing tasks) of an IL policy? To answer this question, this paper builds a reachability-based safety filter to enforce hard constraints on IL, which we call Reachability-Aided Imitation Learning (RAIL). Through evaluations with state-of-the-art IL policies in mobile robots and manipulation tasks, we make two key findings. First, the highest-performing policies are sometimes only so because they frequently violate constraints, and significantly lose performance under hard constraints. Second, surprisingly, hard constraints on the lower-performing policies can occasionally increase their ability to perform tasks safely. Finally, hardware evaluation confirms the method can operate in real time.