 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Learning from Large-Scale Datasets for Robot Manipulation
Jun 16, 2025Imitation learning from large multi-task demonstration datasets has emerged as a promising path for building generally-capable robots. As a result, 1000s of hours have been spent on building such large-scale datasets around the globe. Despite the continuous growth of such efforts, we still lack a systematic understanding of what data should be collected to improve the utility of a robotics dataset and facilitate downstream policy learning. In this work, we conduct a large-scale dataset composition study to answer this question. We develop a data generation framework to procedurally emulate common sources of diversity in existing datasets (such as sensor placements and object types and arrangements), and use it to generate large-scale robot datasets with controlled compositions, enabling a suite of dataset composition studies that would be prohibitively expensive in the real world. We focus on two practical settings: (1) what types of diversity should be emphasized when future researchers collect large-scale datasets for robotics, and (2) how should current practitioners retrieve relevant demonstrations from existing datasets to maximize downstream policy performance on tasks of interest. Our study yields several critical insights -- for example, we find that camera poses and spatial arrangements are crucial dimensions for both diversity in collection and alignment in retrieval. In real-world robot learning settings, we find that not only do our insights from simulation carry over, but our retrieval strategies on existing datasets such as DROID allow us to consistently outperform existing training strategies by up to 70%. More results at https://robo-mimiclabs.github.io/
RAIL: Reachability-Aided Imitation Learning for Safe Policy Execution
Sep 28, 2024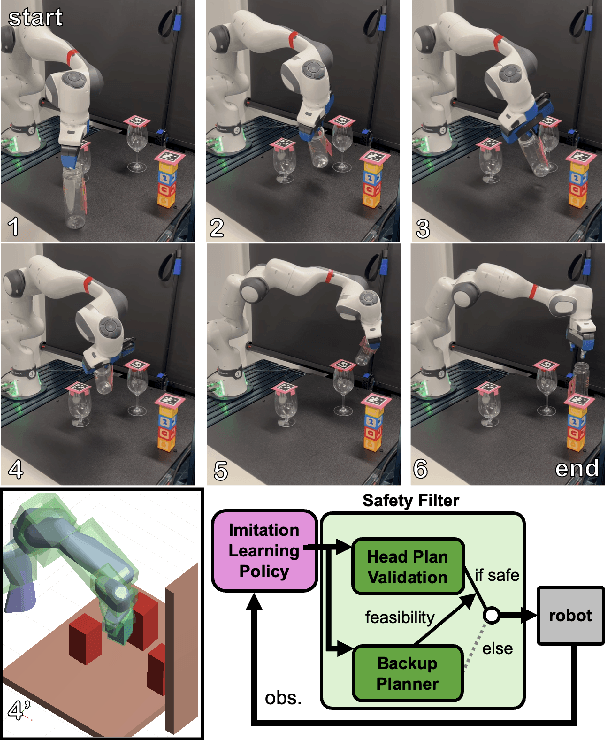


Imitation learning (IL) has shown great success in learning complex robot manipulation tasks. However, there remains a need for practical safety methods to justify widespread deployment. In particular, it is important to certify that a system obeys hard constraints on unsafe behavior in settings when it is unacceptable to design a tradeoff between performance and safety via tuning the policy (i.e. soft constraints). This leads to the question, how does enforcing hard constraints impact the performance (meaning safely completing tasks) of an IL policy? To answer this question, this paper builds a reachability-based safety filter to enforce hard constraints on IL, which we call Reachability-Aided Imitation Learning (RAIL). Through evaluations with state-of-the-art IL policies in mobile robots and manipulation tasks, we make two key findings. First, the highest-performing policies are sometimes only so because they frequently violate constraints, and significantly lose performance under hard constraints. Second, surprisingly, hard constraints on the lower-performing policies can occasionally increase their ability to perform tasks safely. Finally, hardware evaluation confirms the method can operate in real time.
Learning to Discern: Imitating Heterogeneous Human Demonstrations with Preference and Representation Learning
Oct 22, 2023



Practical Imitation Learning (IL) systems rely on large human demonstration datasets for successful policy learning. However, challenges lie in maintaining the quality of collected data and addressing the suboptimal nature of some demonstrations, which can compromise the overall dataset quality and hence the learning outcome. Furthermore, the intrinsic heterogeneity in human behavior can produce equally successful but disparate demonstrations, further exacerbating the challenge of discerning demonstration quality. To address these challenges, this paper introduces Learning to Discern (L2D), an offline imitation learning framework for learning from demonstrations with diverse quality and style. Given a small batch of demonstrations with sparse quality labels, we learn a latent representation for temporally embedded trajectory segments. Preference learning in this latent space trains a quality evaluator that generalizes to new demonstrators exhibiting different styles. Empirically, we show that L2D can effectively assess and learn from varying demonstrations, thereby leading to improved policy performance across a range of tasks in both simulations and on a physical robot.