 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCasa365: A Large-Scale Simulation Framework for Training and Benchmarking Generalist Robots
Mar 04, 2026Recent advances in robot learning have accelerated progress toward generalist robots that can perform everyday tasks in human environments. Yet it remains difficult to gauge how close we are to this vision. The field lacks a reproducible, large-scale benchmark for systematic evaluation. To fill this gap, we present RoboCasa365, a comprehensive simulation benchmark for household mobile manipulation. Built on the RoboCasa platform, RoboCasa365 introduces 365 everyday tasks across 2,500 diverse kitchen environments, with over 600 hours of human demonstration data and over 1600 hours of synthetically generated demonstration data -- making it one of the most diverse and large-scale resources for studying generalist policies. RoboCasa365 is designed to support systematic evaluations for different problem settings, including multi-task learning, robot foundation model training, and lifelong learning. We conduct extensive experiments on this benchmark with state-of-the-art methods and analyze the impacts of task diversity, dataset scale, and environment variation on generalization. Our results provide new insights into what factors most strongly affect the performance of generalist robots and inform strategies for future progress in the field.
What Matters in Learning from Large-Scale Datasets for Robot Manipulation
Jun 16, 2025Imitation learning from large multi-task demonstration datasets has emerged as a promising path for building generally-capable robots. As a result, 1000s of hours have been spent on building such large-scale datasets around the globe. Despite the continuous growth of such efforts, we still lack a systematic understanding of what data should be collected to improve the utility of a robotics dataset and facilitate downstream policy learning. In this work, we conduct a large-scale dataset composition study to answer this question. We develop a data generation framework to procedurally emulate common sources of diversity in existing datasets (such as sensor placements and object types and arrangements), and use it to generate large-scale robot datasets with controlled compositions, enabling a suite of dataset composition studies that would be prohibitively expensive in the real world. We focus on two practical settings: (1) what types of diversity should be emphasized when future researchers collect large-scale datasets for robotics, and (2) how should current practitioners retrieve relevant demonstrations from existing datasets to maximize downstream policy performance on tasks of interest. Our study yields several critical insights -- for example, we find that camera poses and spatial arrangements are crucial dimensions for both diversity in collection and alignment in retrieval. In real-world robot learning settings, we find that not only do our insights from simulation carry over, but our retrieval strategies on existing datasets such as DROID allow us to consistently outperform existing training strategies by up to 70%. More results at https://robo-mimiclabs.github.io/
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
RT-Affordance: Affordances are Versatile Intermediate Representations for Robot Manipulation
Nov 05, 2024We explore how intermediate policy representations can facilitate generalization by providing guidance on how to perform manipulation tasks. Existing representations such as language, goal images, and trajectory sketches have been shown to be helpful, but these representations either do not provide enough context or provide over-specified context that yields less robust policies. We propose conditioning policies on affordances, which capture the pose of the robot at key stages of the task. Affordances offer expressive yet lightweight abstractions, are easy for users to specify, and facilitate efficient learning by transferring knowledge from large internet datasets. Our method, RT-Affordance, is a hierarchical model that first proposes an affordance plan given the task language, and then conditions the policy on this affordance plan to perform manipulation. Our model can flexibly bridge heterogeneous sources of supervision including large web datasets and robot trajectories. We additionally train our model on cheap-to-collect in-domain affordance images, allowing us to learn new tasks without collecting any additional costly robot trajectories. We show on a diverse set of novel tasks how RT-Affordance exceeds the performance of existing methods by over 50%, and we empirically demonstrate that affordances are robust to novel settings. Videos available at https://snasiriany.me/rt-affordance
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Jun 04, 2024Recent advancements in Artificial Intelligence (AI) have largely been propelled by scaling. In Robotics, scaling is hindered by the lack of access to massive robot datasets. We advocate using realistic physical simulation as a means to scale environments, tasks, and datasets for robot learning methods. We present RoboCasa, a large-scale simulation framework for training generalist robots in everyday environments. RoboCasa features realistic and diverse scenes focusing on kitchen environments. We provide thousands of 3D assets across over 150 object categories and dozens of interactable furniture and appliances. We enrich the realism and diversity of our simulation with generative AI tools, such as object assets from text-to-3D models and environment textures from text-to-image models. We design a set of 100 tasks for systematic evaluation, including composite tasks generated by the guidance of large language models. To facilitate learning, we provide high-quality human demonstrations and integrate automated trajectory generation methods to substantially enlarge our datasets with minimal human burden. Our experiments show a clear scaling trend in using synthetically generated robot data for large-scale imitation learning and show great promise in harnessing simulation data in real-world tasks. Videos and open-source code are available at https://robocasa.ai/
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
PRIME: Scaffolding Manipulation Tasks with Behavior Primitives for Data-Efficient Imitation Learning
Mar 10, 2024Imitation learning has shown great potential for enabling robots to acquire complex manipulation behaviors. However, these algorithms suffer from high sample complexity in long-horizon tasks, where compounding errors accumulate over the task horizons. We present PRIME (PRimitive-based IMitation with data Efficiency), a behavior primitive-based framework designed for improving the data efficiency of imitation learning. PRIME scaffolds robot tasks by decomposing task demonstrations into primitive sequences, followed by learning a high-level control policy to sequence primitives through imitation learning. Our experiments demonstrate that PRIME achieves a significant performance improvement in multi-stage manipulation tasks, with 10-34% higher success rates in simulation over state-of-the-art baselines and 20-48% on physical hardware.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024



Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Oct 26, 2023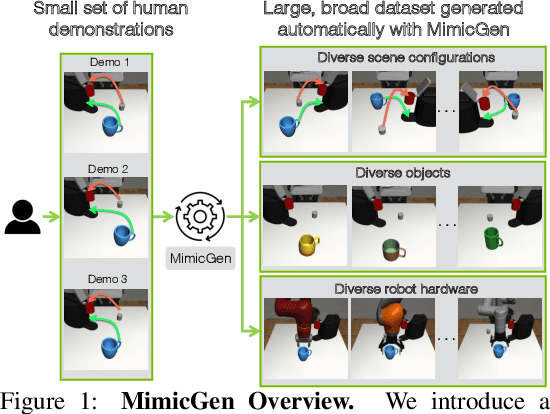
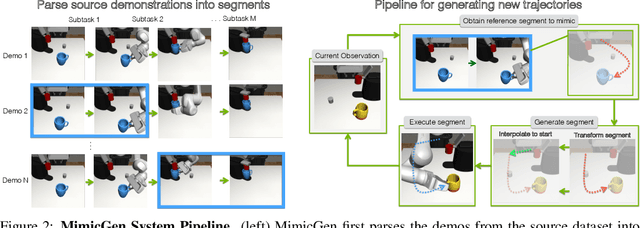

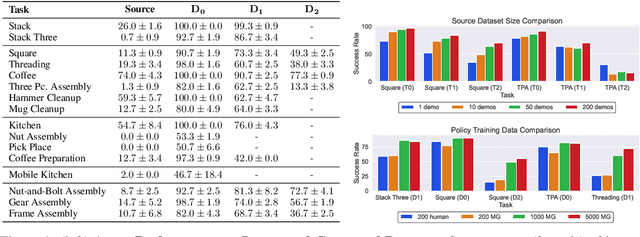
Imitation learning from a large set of human demonstrations has proved to be an effective paradigm for building capable robot agents. However, the demonstrations can be extremely costly and time-consuming to collect. We introduce MimicGen, a system for automatically synthesizing large-scale, rich datasets from only a small number of human demonstrations by adapting them to new contexts. We use MimicGen to generate over 50K demonstrations across 18 tasks with diverse scene configurations, object instances, and robot arms from just ~200 human demonstrations. We show that robot agents can be effectively trained on this generated dataset by imitation learning to achieve strong performance in long-horizon and high-precision tasks, such as multi-part assembly and coffee preparation, across broad initial state distributions. We further demonstrate that the effectiveness and utility of MimicGen data compare favorably to collecting additional human demonstrations, making it a powerful and economical approach towards scaling up robot learning. Datasets, simulation environments, videos, and more at https://mimicgen.github.io .